Download

1 / 18

E N D
MUSCLE movie data base is a multimodal movie corpus collected to develop content-based multimedia processing like:- speaker clustering- speaker turn detection- visual speech activity detection- face detection- facial feature detection- face clustering scene segmentation- saliency detection- multimodal dialogue detection
This database covers four different modalities :- audio- video- audiovisual - text Video annotation tool ANVIL and Anthropos 7 Editor are described
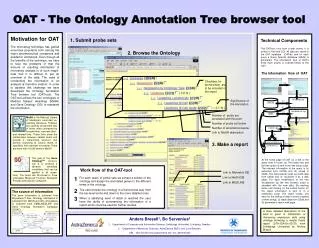
VIDEO ANNOTATION TOOL • ANVIL : video annotation tool • It offers hierarchical multi-layered annotation • Annotation board shows colour-coded elements on multiple tracks in time-alignment • ANVIL can import data from PRAAT and XWaves
Anthropos 7 Editor • Anthropos 7 Editor is an annotation tool for MPEG-7 data • It makes viewing and editing MPEG-7 data easier • To visualise information Anthropos 7 Editor uses the Timeline Area. Information based on a single frame is visualised in the Video Area, static movie information in the Static Information Area. • These areas communicate with each other • Anthropos 7 Editor can visualise the ROI (Region of interest) of each actor. The user can interact using the mouse. • Every image region encompassing an actor can be overlaid as a Box and it can be modified by a user
MUSCLE movie data base specifications • Concepts like dialogue, saliency must be described independently: audio-only, video-only and also audio-visual description
Dialogue annotation • 54 movie scenes extracted from 8 movies • The language for all scenes is English • Duration of each scene is 24-123 seconds • Each movie scene was separated in two different files: an audio file, a video file
MUSCLE movie data base description • Movie title Number of Number of non-dialogue Scenes per Movie Dialoguescenes scenes • Analyze That 4 2 6 • Cold Mountain 5 1 6 • Jackie Brown 3 3 6 • Lord of the Rings I 5 3 8 • Platoon 4 2 6 • Secret Window 4 6 10 • The Prestige 4 2 6 • American Beauty 10 0 10 • Total number 39 19 58
Types of dialogues for audios:- with low-level audio background: BD (dialogue wih background): dialogue in the presence of noisy background or music- monologue is classified as CM (clean monologue) or BM (Monologue with backrgound)all scenes not labeled CD or BD are considered non-dialogueTypes of dialogues for video:- CD: 2 actors present in the scene- BD: at least two actors are present- monologues types for video labeled as CM or BM
Metadata for audio files: • Speech activity data: • Speech intervals (from the start and the end time) Metadata for video files: • Lip activity data (defined by the start and end time and frame)
States to label lip activity intervals: • 0 : ack of actor’s head visible • 1 :actor’s frontal face is visible • 2 : actor’s frontal face visible + lip activity
Afterwards: • Face tracking info extracted from the scenes • The extracted info is processed by a human annotator • face of each actor in a dialogue or monologue is assigned a bounding box • Data saved in xml MPEG-7 format • Two files (audio, video) merged into one xml file for each scene
Saliency annotation • Based on detection of „pops-out” (abrupt changes, abnormalities e.g. in speech, environmental noises etc.)
3 movie clips (27 mins) from 3 different movies of different genres • Chosen carefully to represent all cases of saliency • Audio content includes: speech in a dialogie, with background sound like music, noises. • The background sounds: animals, knockings, cars etc. • Visual content: abrupt scene changes,editing effects e.g. computer made light
clips annotated by two different annotatorsan event considered salient is annotated separatelyfor audio this event depends on the importance of sounds it makes in scenes for the annotatorfor visual: pop-out colour and motionsudden events can be regarded as salientsilence is not annotated
ANVIL used for saliency detection • 3 main saliency categories of the annotation scheme: visual, audio, generic saliency • Audio saliency is annotated using auditory sense • Visual saliency using the visual sense • Generic saliency using both modalities simultaneously
Audio saliency • Description of the audio in the scene • Chosen categories: dialogue, music, noise, sound effect, environmental sound, machine sound, background sound, unclassified sound, mixed sound. • The annotator can chose more than one sound • Speech saliency measured by intensity and loudness of voice
Visual saliency • Description of the object’s motion • Pop-out events annotated as well Visual Saliency Motion Start-Stop, Stop-Start, Impulsive event, Static, Moving, Other Changes of cast (binary decision) Pop-out event (binary decision) Saliency Factor None, Low, Mid, High
Generic saliency • A low-level description of saliency • Description features are: audio, visual, audiovisual • Saliency measured as high, mid or low