Download

1 / 18
180 likes | 209 Views
Machine learning is a sub-field of artificial intelligence (AI) that focuses on creating statistical models and algorithms that allow computers to learn and become more proficient at performing particular tasks. Machine learning algorithms create a mathematical model with the help of historical sample data, or u201ctraining data,u201d that assists in making predictions or judgments without being explicitly programmed.

E N D
How to build machine learning apps? leewayhertz.com/how-to-build-a-machine-learning-app Machine learning is a subfield of artificial intelligence that focuses on developing models that learn from data and demonstrate incremental improvement in performance over time. Even though many still associate “machine learning” with unrealistic sci-fi tales, we now see applications of this technology everywhere around us. Facebook’s chatbots, Spotify and Netflix suggestions, Alexa from Amazon, online spellcheckers, and predictive text on your phone are just a few instances of machine learning technology at work. Market revenue for machine learning (ML) in 2021 was estimated at $15.44 billion. The market is projected to increase from USD 21.17 billion in 2022 to USD 209.91 billion in 2029, with a CAGR of 38.8%. Industries are progressively embracing the creation of machine-learning apps that perform various tasks using machine-learning algorithms, including predictive text input, speech recognition, object detection, and more. Additionally, they can gather information from user behavior and preferences, allowing for more individualized recommendations and a better user experience. Machine learning enables tracking heart rate, activity level, and other metrics in real-time on wearable devices like smartwatches and fitness trackers. Incorporating machine learning into applications can enhance user experience and offer insightful data on user behavior and preferences, creating new opportunities for businesses to engage with their clients. 1/18
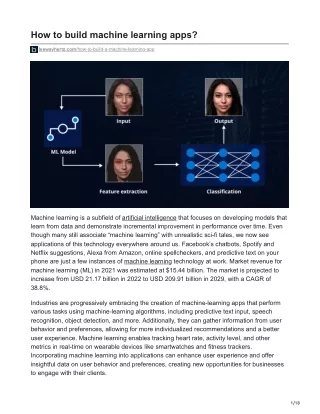
In this article, we will dive deep into machine learning fundamentals and their components and learn how to build a machine learning app. What is machine learning? Key components of machine learning Machine learning methods Machine learning algorithms Use cases of machine learning How to build a machine learning app? What is machine learning? Machine learning is a sub-field of artificial intelligence (AI) that focuses on creating statistical models and algorithms that allow computers to learn and become more proficient at performing particular tasks. Machine learning algorithms create a mathematical model with the help of historical sample data, or “training data,” that assists in making predictions or judgments without being explicitly programmed. Machine learning uses computer science and statistics to create prediction models. It requires a huge amount of data to perform well; in short, the higher the volume of data, the higher the accuracy. When a machine learning system receives new data, it forecasts the results based on the patterns learned from the historical data. The amount of data used to train the model affects how precisely the output is predicted because a larger data set allows for the creation of a more accurate model. One may readily see the importance of machine learning by looking at numerous applications. Machine learning is presently used in self-driving cars, cyber fraud detection, and face recognition, among other use cases. Some top companies like Netflix and Amazon have created machine-learning models that analyze user interests and offer personalized product suggestions. Key components of machine learning The key components of machine learning are: Data Data is a key component in machine learning and provides the foundation for machine learning algorithms. Machines require vast amounts of data to learn from to function and make informed decisions. Any unprocessed information, value, sound, image, or text can be considered data. The accuracy and effectiveness of a machine learning model heavily depend on the quality and quantity of data used for its training. While creating a data set, ensure that it has the 5V characteristics: 2/18
Volume: The amount of information required for the model to be accurate and effective matters. The accuracy of the machine learning model will increase with the size of the data collected. Velocity: The speed of data generation and processing is also crucial. Real-time data processing may be required in some cases to get accurate results. Variety: The data set should include variety in form, for instance, structured, unstructured, and semi-structured data. Veracity: Data cleanliness, consistency, and error-free are all qualities and accuracy aspects of data. Only with accurate data a precise output can be expected. Value: The information in the data must be valuable to draw any conclusion. Model The model serves as the underlying core component of machine learning and represents the link between input and output to generate precise and fresh data. It is trained on a dataset to identify underlying patterns and produce accurate results. Following training, the model is tested to determine if it can provide fresh and precise data; if the test is successful, it is then used for real-world applications. Let’s take an example to understand this further. You want to create a model that considers characteristics like age, body mass index (BMI), and blood sugar levels, to identify whether a person has diabetes. We must first compile a dataset of people with diabetes and the associated health metrics. The algorithm uses the dataset of people with diabetes and considers their health indicators to analyze the data for patterns and relationships and generate accurate results. It identifies the underlying relationships between the outcome (diabetes status) and the input features (blood sugar level, BMI, and age). Once trained, the model can predict if new patients have diabetes using information like blood sugar level, weight, and age. Algorithm A model is trained using an algorithm that can learn the hidden patterns from the data, predict the output, and improve the performance from experiences. It is an essential part of machine learning since it powers the learning process and affects the precision and potency of the model. A training dataset consists of input data and associated output values. Once patterns and associations have been identified in the data, several mathematical and statistical techniques are used to determine the underlying relationship between the input and output. For example, when we have a dataset of animal photos with their matching species labels, we need to train a machine-learning model to identify the species of animals in the photograph. 3/18
A convolutional neural network (CNN) may be used for this purpose. The CNN method breaks down the incoming visual data into numerous layers of mathematical operations that recognize features like edges, shapes, and patterns. The image is then classified into one of the species categories using these characteristics. However, several alternative methods exist, including decision trees, logistic regression, k- nearest neighbors, etc. The provided dataset and the issues that must be solved determine your algorithm. Machine learning methods Machine learning can be used in various methods for producing valuable outcomes. The various machine learning techniques include: Supervised learning Supervised learning is a subset of machine learning that trains its algorithm using labeled datasets. Labeled data are those that have output tagged along with the input. In this approach, machines are trained using some labeled datasets, and then the machine is expected to produce accurate results using those training data. Here’s an example to help you understand: Images of several animals, including cats and dogs, are given to the machine with labels. The machine uses the animals’ attributes, like shape, size, color, etc., to learn and generate responses. Here the response generated is based on the labeled dataset. The two major types of supervised learning are: Classification Classification is used when an output variable is categorical and has two or more classes. For instance, yes or no, true or untrue, male or female, etc. For example, if we want a machine to recognize spam mail, we must first teach it what spam mail is so that it can determine whether a message is a spam. This is done using different spam filters, which examine the email’s topic, body, heading, etc., to check whether it contains deceptive information. Spammers who have already been blacklisted use specific phrases and blacklist filters to blackmail. The message is assessed using all these characteristics to determine its spam score. Regression Regression is utilized when the output variable has a real or continuous value. There is a relationship between two or more variables; a change in one variable is proportional to a change in the other. For instance, estimating a house’s cost based on its size, location, and other factors. Here price of the house is dependent on size, location etc. 4/18
Unsupervised learning Unsupervised learning involves using unlabeled data for machine learning. The computer seeks trends and patterns in unlabeled data without being specifically told the desired result. Let’s use the prior example to understand this better. Without labels, the machine is provided pictures of animals, such as cats and dogs, to produce the response. The machine analyses patterns in the input and categorizes the data appropriately using characteristics like form, size, color etc. The datasets are completely unlabeled here, and the system compares and analyzes the patterns to generate desired results. Semi-supervised learning Semi-supervised learning refers to machine learning that falls between supervised and unsupervised learning. It is a training method that blends a significant amount of unlabeled data with a small amount of labeled data. Semi-supervised learning seeks to create a function that can accurately predict the output variable from the input variables, just like supervised learning does. An unsupervised learning technique is used to cluster comparable data, which also helps to categorize the unlabeled data into labeled ones. When there is a large amount of unlabeled data accessible but categorizing it all would be expensive or difficult, semi-supervised learning is extremely useful. For example, suppose we have a collection of 10,000 photos of animals, but only 1000 have been assigned to the appropriate class, such as dog or cat. With semi-supervised learning, we can train a convolutional neural network (CNN) model to distinguish between dogs and cats using the labeled photos. The remaining 9,000 photos that are not identified can then be labeled using this trained model. With the addition of these anticipated labels, the original labeled dataset can grow from 1000 to 10,000 labels. To increase the model’s accuracy in categorizing dogs and cats, it can then be retrained on the new, larger labeled dataset. Reinforcement learning Reinforcement learning (RL) is a type of machine learning that involves an autonomous agent learning to make decisions and take actions in an environment to maximize a reward signal. The agent interacts with the environment by taking actions and receiving feedback in the form of rewards or penalties, depending on the outcome of its actions. RL aims to find the optimal policy, which is a set of rules that tells the agent which action to take in a given state to maximize its long-term reward. The agent learns this policy through trial and error by taking actions, observing the resulting state and reward, and updating its decision-making strategy accordingly. The environment in RL is typically defined by a set of states and actions that the agent can take. The agent starts in a given state, takes action, and transitions to a new state. The reward function evaluates the outcome of each action, providing the agent with feedback on 5/18
its performance. The agent’s objective is to learn the policy that leads to the highest possible reward over time. In summary, reinforcement learning is a type of machine learning where an agent learns to take actions in an environment to maximize a reward signal. It is a trial-and-error process where the agent interacts with the environment and receives feedback through rewards or penalties. The goal is to learn the optimal policy, which maximizes the long-term reward. Deep learning Deep learning algorithms are created to learn and develop over time through a process known as backpropagation. The structure and operation of the human brain inspire these algorithms. Deep learning includes training artificial neural networks with numerous layers to evaluate and comprehend complicated data. Deep learning neural networks often include numerous layers of linked nodes, where each layer picks up increasingly abstract properties from the input data. The first layer receives the input data, processes it, and then transfers the results to the following layer. This process is carried out with successive layers, refining the features the prior layer had discovered. The network’s final output is a prediction or classification based on the learned features. Let’s say we wish to group pictures of animals into subcategories like cats, dogs, and birds. A big collection of labeled photos, where each image is tagged with its appropriate category, could be used to train a deep learning algorithm. Starting with the raw pixel values from the photographs, the algorithm would feed them into a deep neural network comprising many layers of interconnected nodes. Edges, textures, and forms are just a few examples of the abstract qualities each layer would gradually learn from the input data. The network’s final output layer would comprise nodes for each potential category, with each node producing a score indicating a probability that the input image falls into that category. Machine learning algorithms An algorithm is a series of guidelines or instructions created to solve a particular issue or carry out a certain operation. It is a set of precise actions a computer can carry out to solve a problem or achieve a goal. There are various types of algorithms, a few of which are discussed below: Decision trees The decision tree algorithm belongs to the supervised learning subset and can be applied to classification and regression issues. Each leaf node of the decision tree corresponds to a class label, and the tree’s internal nodes represent the attributes to resolve the problem. Suppose you want to determine a person’s health based on age, dietary habits, level of physical activity, etc. Questions like “What’s the age?” “Does he exercise?” and “Does he eat 6/18
healthy food?” are the decision nodes in this scenario. And the leaves, which represent either “healthy” or “unhealthy,” are the consequences. In this instance, the issue was binary classification (a yes-no type problem). There are various types of decision trees, they are: Classification trees: These decision trees group or classify input data into multiple classes or categories by their traits or characteristics. Regression trees: These decision-making structures are employed to forecast a continuous numerical value in light of the input data. Binary decision trees: These decision trees are classified as binary since each node only has two possible outcomes. Multiway decision trees: Each node has multiple alternative outcomes in these decision trees. K-nearest neighbors (K-NN) K-nearest neighbors are a supervised machine-learning technique for solving classification and regression issues. Nevertheless, classification issues are where it’s most frequently applied. It is considered a non-parametric method since it makes no assumptions about the underlying data distribution. When accepting input, it doesn’t do any calculations or other operations; instead, it retains the information until the query is executed. It is a great option for data mining and is also referred to as a lazy learning algorithm. The parameter “K” in K-NN controls how many nearest neighbors will participate in the voting. K-NN uses a voting system to identify the class of an unobserved observation. As a result, the class with the most votes will be the class of the relevant data point. If K equals 1, we will only utilize the data point’s closest neighbor to classify the data point. We will use the ten closest neighbors if K equals ten, and so on. It is straightforward to comprehend and apply the k-nearest neighbors categorization method, and it works best when the data points are non-linear. Support vector machines One of the most prominent supervised learning algorithms, Support Vector Machine, or SVM, is used to solve Classification and Regression problems. However, it is largely employed in Machine Learning Classification issues. The SVM algorithm aims to establish the best decision boundary or line to divide n-dimensional space into classes so that subsequent data points can be assigned to the appropriate category. The term “hyperplane” refers to this optimal decision boundary. To create the hyperplane, SVM selects the extreme points and vectors. 7/18
Finding a hyperplane in an N-dimensional space that classifies the data points is the goal of the SVM method. The number of features determines the hyperplane’s size. The hyperplane is essentially a line if there are just two input features, and the hyperplane turns into a 2-D plane if there are three input features. Imagining something with more than three features gets challenging. The SVM technique can be used to develop a model that can accurately determine the outcome. For example, the image contains a basket of fruits (apple and banana), and we want the system to identify these fruits. We will train our model with several photographs of apples and bananas to become familiar with the attributes of these fruits. As a result, the support vector will see the extreme cases and attributes of apples and bananas when drawing a judgment border between these two data sets. Based on the support vectors, it will categorize it as an apple or banana. Neural networks A neural network is an artificial intelligence technique instructing computers to analyze data. The human brain is the inspiration behind neural network architecture. Human brain cells, called neurons, form a complex, highly interconnected network and send electrical signals to each other to help humans process information. Similarly, an artificial neural network comprises neurons that work together to solve problems. Artificial neurons are software modules called nodes, and artificial neural networks are software programs or algorithms that, at their core, use computing systems to solve mathematical calculations. Computers can use this to build an adaptive system that helps them improve by learning from their failures. As a result, artificial neural networks try to tackle challenging issues like summarising documents or identifying faces. The input layer, hidden layer, and output layer are the three layers that make up a simple neural network. The input layer is where data from the outside world enters an artificial neural network. Input nodes process, analyze, or categorize data before forwarding it to the hidden layer. The input or other hidden layers serve as the input for hidden layers. Artificial neural networks can have a lot of hidden layers. Each hidden layer evaluates the output from the preceding layer, refines it, and then sends it to the output layer. The artificial neural network’s output layer presents the complete data processing results. Feedforward neural networks, also known as multi-layer perceptrons (MLPs), convolutional neural networks (CNNs), and recurrent neural networks (RNNs), are among the various types of neural networks that are used for different purposes. Clustering 8/18
It is an unsupervised learning method, meaning the algorithm gets no supervision and works with an unlabeled dataset. The unlabeled dataset is grouped using machine learning clustering or cluster analysis. It can be described as a method of dividing the data points into clusters of related data points. It identifies some comparable patterns in the unlabeled dataset, including shape, size, color, behavior, etc., and divides them into groups based on the presence or absence of those similar patterns. For example, in a shopping center, t-shirts are classified in one section, trousers in another, and fruits and vegetables are arranged in different sections to help customers find the products easily. The clustering process operates similarly. The two main clustering techniques are Hard clustering (where each data point belongs to a single group) and Soft Clustering (data points can belong to another group also). However, there are several different Clustering techniques also available. The primary clustering techniques in machine learning are listed below: 1. Partitioning clustering– This clustering method divides the data into non-hierarchical groups. It’s also known as the centroid-based approach. The K-Means Clustering algorithm is the most popular example of partitioning clustering. The dataset is split into k groups, where K refers to the number of pre-defined groups. The cluster centroid is designed to have a minimum distance between data points in one cluster compared to other cluster centroids. 2. Density-based clustering– The density-based clustering algorithm joins into clusters, and arbitrary shapes are formed as long as the highly packed regions can be connected. After discovering several clusters in the dataset, the algorithm groups the high-density areas into clusters. The sparser areas in data space separate the dense sections from one another. If the dataset includes many dimensions and densities, these algorithms may have trouble clustering the data points. 3. Distribution model-based clustering– In the distribution model-based clustering method, the data is separated according to the likelihood that each dataset corresponds to a specific distribution. A few distributions—most frequently the Gaussian distribution—are presumptively used to classify the objects. 4. Hierarchical clustering– Hierarchical clustering can be utilized as an alternative to partitioned clustering, as there is no need to pre-specify the number of clusters to be produced. This method divides the dataset into clusters to produce a structure resembling a tree known as a dendrogram. Removing the appropriate amount of the tree makes it possible to choose the observations or any number of clusters. The Agglomerative Hierarchical algorithm is the most popular example of this technique. 5. Fuzzy clustering– When using fuzzy clustering, data points might be included in more than one category (or “cluster”). To identify patterns or commonalities between items in a set, clustering separates data points into sections based on the similarity between items; items in clusters should be similar and distinct from items in other groups. 9/18
Apart from the above-discussed algorithms, many other algorithms are used in machine learning, such as Naïve Bayes Algorithm, Random Forest Algorithm, Apriori Algorithm etc. Use cases of machine learning Automating numerous time-consuming processes has made machine-learning apps a vital part of our life. Here are a few examples of typical use cases: Self-driving cars Self-driving cars heavily use machine learning algorithms to assess and analyze huge amounts of real-time information from sensors, cameras, and other sources. Machine learning algorithms are employed to identify and categorize items, such as cars, people walking on the pavement, and traffic signs, to decide how the automobile should navigate the road. To get better at driving over time, such as responding to shifting road conditions and avoiding collisions, these algorithms also learn from prior driving experiences. Utilizing machine learning, self-driving vehicles can provide passengers with increased safety, effectiveness, and convenience while reducing traffic congestion. Predict traffic patterns Machine learning is commonly used in the logistics and transportation industries to predict traffic patterns. To accurately predict traffic patterns and congestion levels, machine learning algorithms can examine enormous volumes of historical traffic data, including weather, time of day, and other factors. These forecasts can streamline traffic flow, lessen obstructions and delays, and optimize vehicle travel times. Moreover, ML can forecast demand for public transportation, improve traffic signal timing, and give drivers real-time traffic alerts and alternate routes. Cities and transportation agencies may increase the effectiveness and safety of their transportation systems, lower carbon emissions, and improve the overall travel experience for customers by utilizing machine learning to predict traffic patterns. Fraud detection Machine learning is crucial for detecting fraud in the financial, e-commerce, and other sectors. Machine learning algorithms can evaluate massive volumes of transactional data, including user behavior, past transactions, and other factors, to find trends and abnormalities that might indicate fraudulent conduct. To increase their precision and recognize new forms of fraudulent activity, these algorithms can learn from prior instances of fraud. Organizations can decrease financial losses, avoid reputational harm, and increase consumer trust by utilizing machine learning for fraud detection. Moreover, it can optimize fraud protection methods, detect fraud in real time, and streamline investigation processes. In general, 10/18
machine learning is a potent fraud detection technique that can assist firms in staying ahead of the growing cyber risks and safeguarding their resources and clients from criminal activities. Image recognition Machine learning is used extensively in various sectors, including security, retail, and healthcare. ML algorithms can evaluate and classify huge amounts of visual data, including medical photos, product images, and surveillance footage, to find patterns and features that distinguish one thing from another. Image recognition is used in the healthcare industry to evaluate medical pictures such as X- rays, MRIs, and CT scans to detect and treat diseases. In the retail industry, it is used to analyze product images, find flaws, and locate counterfeit goods. Image recognition is used in security to review surveillance footage, spot potential dangers, and monitor crowd behavior. Organizations may automate image analysis activities, increase accuracy and efficiency, and uncover new insights and prospects by utilizing machine learning algorithms for image recognition. Speech recognition A well-known use of machine learning (ML) is speech recognition. Computers can understand and recognize human voices using machine learning (ML) techniques and then translate them into text or other data types that may be utilized for various tasks. Among the frequent applications of speech recognition enabled by ML are: Virtual assistants: The core technology behind virtual assistants like Amazon’s Alexa, Apple’s Siri, Google Assistant, and Microsoft’s Cortana is speech recognition. These helpers can answer inquiries, play music, create reminders, and execute other chores by understanding natural language commands. Transcription: Voice recognition is frequently used to convert audio and video content, including meetings, interviews, podcasts, and dictations, into written text. Machine learning (ML) algorithms can accurately convert spoken words into text, saving time and effort compared to manual transcription. Customer service: Customer support interactions can be automated in call centers using ML-powered speech recognition. Automatic voice systems can recognize client inquiries, respond to them, and route calls to the agent or department as and when required. How to build a machine learning app? 11/18
Here is a general breakdown of the procedure needed to create machine-learning apps. We will use the Naive Bayes Classifier, one of the simplest machine learning techniques, and construct an app that forecasts airline information whenever a query is generated. The following stages demonstrate how to build a machine-learning app: Step 1- Libraries and datasets In this step, install scikit-learn and pandas: pip install scikit-learn pip install pandas We’ll apply a dataset using an example of airline travel where we create a query regarding the information on flights, and we get the response as per the query generated. Let’s examine this dataset using Pandas. import pandas as pd df_train = pd.read_csv('atis_intents_train.csv') df_test = pd.read_csv('atis_intents_test.csv') Step 2- Preprocess data In this process, we clean the raw data. Before running the algorithm, the dataset is preprocessed to look for missing values, noisy data, and other abnormalities. df_train = pd.read_csv('atis_intents_train.csv') df_train.columns = ['intent','text'] df_train = df_train[['text','intent']] df_test = pd.read_csv('atis_intents_test.csv') df_test.columns = ['intent','text'] 12/18
df_test = df_test[['text','intent']] Step 3- Remove extra spaces Extra spaces between the text and intent are removed using the strip method. Use the following code to remove spaces. df_train['text'] = df_train['text'].str.strip() df_train['intent'] = df_train['intent'].str.strip() df_test['text'] = df_test['text'].str.strip() df_test['intent'] = df_test['intent'].str.strip() Step 4- Vectorize the text data using TF-IDF We will vectorize the data to convert it into numerical form, which would be the training input. vectorizer = TfidfVectorizer(stop_words='english') X_train = vectorizer.fit_transform(df_train['text']) X_test = vectorizer.transform(df_test['text']) Step 5- Encode the target variable We store the labels corresponding to the data points from the training and testing dataset in y_train and y_test, respectively. y_train = df_train['intent'] y_test = df_test['intent'] Step 6- Train a Naive Bayes classifier We are using the Naive Bayes classifier, and the code we used are: clf = MultinomialNB() clf.fit(X_train, y_train) Step 7- Install flask and quick set up Run the following line in the terminal to install the flask. pip install flask 13/18
Step 8- Define the flask app Now follow these instructions to ensure everything is operating properly. The following code is an example of a simple app taken from the Flask documentation. app = Flask(__name__) @app.route('/') def home(): return render_template('index.html') Let’s explain this further: app = Flask( name__) – Creates a Flask class instance with the command app Flask name. The name of the application’s module is represented by the variable name, which aids Flask in knowing where to seek resources like “templates,” which we’ll utilize later. @app.route(“/”): @ – denotes decorators (they modify the behavior of a function or class). Flask is informed by the route() decorator, which URL should call our function. Step 9 – Make an HTML file To begin building the front end, first, create a folder where your app is stored called “templates” (you are not allowed to use any other name). Make an HTML file and place it in the “templates” folder. You can give this file whatever name you like; we named it index.html. Open the HTML file, type doc or HTML and hit the Tab key. Furthermore, your IDE will produce a simple HTML template for you. If not, copy and paste the template below. <!DOCTYPE html> <html > <head> <meta charset="UTF-8"> <title>My Machine Learning Model</title> <!-- Quick Start: CSS --> <link href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.3/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384- 1BmE4kWBq78iYhFldvKuhfTAU6auU8tT94WrHftjDbrCEXSU1oBoqyl2QvZ6jIW3" 14/18
crossorigin="anonymous"> Step 10- Add navigation bar Go to the website’s navbar section, copy and paste the code into the< head> section. We’ll also add a navigation bar (we don’t need it, but it’ll help you get accustomed to bootstrap). We will modify the navbar’s color to dark before running the script by changing the light components in the first line of code to dark (if you leave it as is, it will have a light color). <!-- Nav Bar --> <nav class="navbar navbar-expand-lg navbar-dark bg-dark"> <div class="container-fluid"> <a class="navbar-brand" href="#">Navbar</a> <button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs- target="#navbarSupportedContent" aria-controls="navbarSupportedContent" aria- expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarSupportedContent"> <ul class="navbar-nav me-auto mb-2 mb-lg-0"> <li class="nav-item"> <a class="nav-link active" aria-current="page" href="#">Home</a> </li> <li class="nav-item"> <a class="nav-link" href="#">Link</a> </li> <li class="nav-item dropdown"> <a class="nav-link dropdown-toggle" href="#" id="navbarDropdown" role="button" data-bs- toggle="dropdown" aria-expanded="false"> Dropdown 15/18
</a> <ul class="dropdown-menu" aria-labelledby="navbarDropdown"> <li><a class="dropdown-item" href="#">Action</a></li> <li><a class="dropdown-item" href="#">Another action</a></li> <li><hr class="dropdown-divider"></li> <li><a class="dropdown-item" href="#">Something else here</a></li> </ul> </li> <li class="nav-item"> <a class="nav-link disabled">Disabled</a> </li> </ul> <form class="d-flex"> <input class="form-control me-2" type="search" placeholder="Search" aria-label="Search"> <button class="btn btn-outline-success" type="submit">Search</button> </form> </div> </div> </nav> </head> Step 11 – POST request using form element through UI We are making a post request via form element, which will hit the endpoint at the backend, providing us with the desired outcome. <body> <div class="login"> 16/18
<h2>Airline Travel Information System</h2> <p>Enter Your Query:</p> <!-- Inputs for our ML model --> <form action="{{ url_for('predict')}}" method="post"> <input type="text" name="text" placeholder="Text" required="required" /> <button type="submit" class="btn btn-primary btn-block btn-large">Predict Value!</button> </form> <br> <br> <b> {{ prediction_text }} </b> </div> </body> </html> Step 12- See the result When you add a query, the system will provide the desired outcomes. Airline Travel Information System Enter Your Query Text Predict Value! Intent: axis_ground_service Endnote 17/18
Machine learning is a subset of AI that enables machines to extract information from data and make predictions or judgments without being explicitly programmed. As a result, it has become a useful tool for businesses looking to gather information, streamline operations, and enhance decision-making. Its capacity to learn from data and improve over time has caused a rise in its use across industries, from finance and e-commerce to healthcare. Machine learning applications have improved the ability to detect fraud, recognize faces in pictures, recognize speech, and perform other time-consuming tasks. Developing machine learning apps is a complex process that demands a deep understanding of algorithms, data science, and statistics. The right techniques must be adopted to develop machine learning-based solutions. It is advised to collaborate with an expert that can guide you through the process and assist you in creating highly valuable applications. Machine learning has the power to transform your business and keep you one step ahead of the competition in a digital world that is rapidly changing. Want to develop robust machine-learning apps? Contact LeewayHertz for your requirements. We create reliable and highly performant machine-learning apps with advanced features. 18/18