Download
1 / 23
230 likes | 253 Views
ML operations comprise a set of practices and methods specifically crafted for streamlined management of the complete lifecycle of machine learning models in production environments. It encompasses the iterative process of model development, deployment, monitoring, maintenance and integrating the model into operational systems, ensuring reliability, scalability, and performance.

E N D
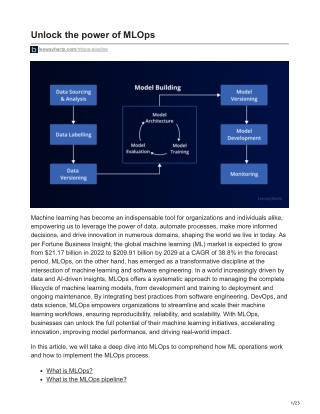
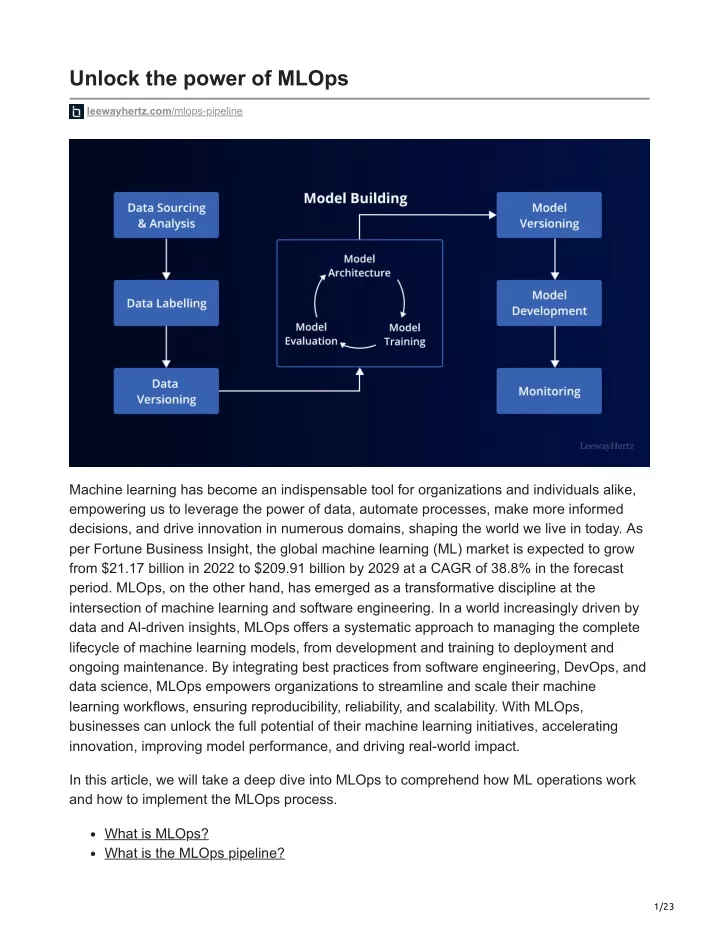
Unlock the power of MLOps leewayhertz.com/mlops-pipeline Machine learning has become an indispensable tool for organizations and individuals alike, empowering us to leverage the power of data, automate processes, make more informed decisions, and drive innovation in numerous domains, shaping the world we live in today. As per Fortune Business Insight, the global machine learning (ML) market is expected to grow from $21.17 billion in 2022 to $209.91 billion by 2029 at a CAGR of 38.8% in the forecast period. MLOps, on the other hand, has emerged as a transformative discipline at the intersection of machine learning and software engineering. In a world increasingly driven by data and AI-driven insights, MLOps offers a systematic approach to managing the complete lifecycle of machine learning models, from development and training to deployment and ongoing maintenance. By integrating best practices from software engineering, DevOps, and data science, MLOps empowers organizations to streamline and scale their machine learning workflows, ensuring reproducibility, reliability, and scalability. With MLOps, businesses can unlock the full potential of their machine learning initiatives, accelerating innovation, improving model performance, and driving real-world impact. In this article, we will take a deep dive into MLOps to comprehend how ML operations work and how to implement the MLOps process. What is MLOps? What is the MLOps pipeline? 1/23
An overview of the MLOps process How to implement MLOps? How to build an MLOps pipeline? What is MLOps? ML operations comprise a set of practices and methods specifically crafted for streamlined management of the complete lifecycle of machine learning models in production environments. It encompasses the iterative process of model development, deployment, monitoring, maintenance and integrating the model into operational systems, ensuring reliability, scalability, and performance. In certain cases, ML operations are solely employed for deploying machine learning models. However, there are businesses that have embraced ML operations throughout multiple stages of the ML lifecycle development. These areas include Exploratory Data Analysis (EDA), data preprocessing, model training, and more. ML operations are based on DevOps, a method for creating, deploying, and managing enterprise applications more effectively. Software development teams (the Devs) and IT operations teams (the Ops) came together to form DevOps to break down silos and improve collaboration. An ML Operations team includes data scientists and ML engineers, in addition to a software development team and an IT operation team. Data scientists organize datasets and perform analysis on them using AI algorithms. ML engineers run the datasets through the models using automated, structured procedures. Machine learning operations aim to eliminate waste, increase automation, and produce deeper and more trustworthy insights. Machine learning models’ development, deployment, monitoring, and maintenance must be streamlined while leveraging tools, methodologies, and best practices to ensure consistency, scalability, and performance in practical applications. ML operations aim to eliminate the communication gap between data scientists, developers, and operations teams by efficiently and effectively deploying machine learning models into production environments. What is the MLOps pipeline? Machine learning pipelines are a collection of connected procedures arranged logically to automate and streamline the development of a machine learning model. Data extraction, preprocessing, feature engineering, model training, evaluation and deployment are just a few examples that can be incorporated into these pipelines. A machine learning pipeline aims to automate the entire process of developing a machine learning model, from data collection to model deployment, while ensuring consistency, scalability, and maintainability. Machine learning pipelines are essential for navigating the complexity of machine-learning projects and maximizing the efficiency of model-building activities. They facilitate data scientists and machine learning professionals to systematically experiment with various data before working on treatment methods, feature engineering strategies, and model algorithms. 2/23
A standardized framework for creating, evaluating, and deploying machine learning models is provided by machine learning pipelines, which also enhance communication between team members. Pipelines are a collection of planned, automated operations utilized to complete tasks and apply them to various fields, such as machine learning and data orchestration. They facilitate the completion of difficult tasks by streamlining workflows, increasing effectiveness, and ensuring consistency. An overview of the MLOps process Data Processing Phase Data Collection & Ingestion ML Model Selection Data Processing With Model Data Labeling Once the data processing satisfactory move to production phase Finish Data Data Processing Phase Transformation Model Training Save the Model Monitor Model’s Performance Deploy Production Phase LeewayHertz Let us understand the process of ML operations in detail. The workflow has two separate phases: an experimental phase and a production phase. There are specific workflow stages for each component of the workflow. Experimental phase This phase is divided into 3 categories, and they are discussed below: 3/23
Stage-1: Problem identification, data collection and analysis The initial stage in the MLOps process involves defining the issue that must be resolved and gathering data to train and deploy the machine learning model at hand. For example, hospital video data is gathered to serve as input for the machine-learning model in a fall detection application. Real-time video feeds from cameras placed in different hospital locations, like patient rooms or hallways, are included in the video data gathered. These videos featuring the behaviors of patients would provide the data needed to create the foundation for the fall detection algorithm. These data are further preprocessed and labeled. Once a fall is detected the application will notify the nursing or support staff caring for the patients and send an alert to ensure that staff can assist the fallen patient. This step involves the following sub-stages: Data collection and ingestion Once the sample video data has been extracted, the development environment’s data warehouse can be used to store it. The testing process can be made more effective by using a portion of the dataset for testing and experimentation. This enables identifying and resolving any problems or difficulties in a controlled setting before introducing the entire dataset to the program. The data may need to be modified or cleaned once extracted to ensure consistency, correctness, and standardization. Data normalization, enrichment, validation, and cleaning are a few techniques that can be used in data transformation. This stage ensures the data is in a format that can be properly processed and analyzed. A unified dataset may need to be created by integrating or combining data from multiple sources to be processed or analyzed further. It is necessary to load the unified data into the intended system or application for additional processing or analysis after it has been transformed, integrated, and validated. Writing data to data lakes, pushing data to real-time streaming platforms, and database insertion are a few common data loading procedures. These methods ensure the data is accessible for later processing in the desired place and format. During the data ingestion process, it is essential to ensure data security and privacy. Sensitive data should be safeguarded and handled safely via encryption, concealment, or other security methods. Compliance with pertinent rules, such as industry-specific requirements, should be maintained to preserve data privacy and ensure data security. Monitoring and auditing data ingestion are crucial to ensure data reliability, precision, and compliance. Any data quality problems, breaches, or compliance violations can be found and corrected with regular monitoring and audits. Employing monitoring tools, logs, or automatic alerts can help identify any irregularities or contradictions in the data. 4/23
Data ingestion procedures may run into errors or exceptions for several reasons, including network challenges, data format problems, and data gaps. Strong error-handling procedures should be in place to record and handle such errors or exceptions efficiently. Errors may be recorded, unsuccessful procedures may be tried again, or alerts may be sent to the concerned parties for correction. Data labeling Data labeling involves tagging and identifying data to train machine learning models. In the context of identifying patient falls from video footage, data labeling may entail data scientists manually annotating the footage by selecting and marking up specific 3 to 5 seconds video segments that capture instances of patients falling. This labor-intensive process can be streamlined by employing data labeling software tools and other services to accelerate or automate the labeling process using test data. Data scientists may label video segments that show people sitting, standing, or walking in addition to labeling video portions with patient falls. This allows the machine learning program to figure out what activities are taking place in the video and how a patient fall appears. The machine learning model is then trained using labeled data to precisely identify patient falls in real-time production footage. Through data labeling, it becomes possible to identify particular elements in the video footage, such as specific physical areas within the hospital, including patient rooms. The data provided serve as valuable input for the machine learning model, aiding it in understanding the context of the video and its relevance to the specific behavior being recognized, such as patient falls. Stage-2: Machine learning model selection Choosing and evaluating machine learning models and algorithms is a pivotal stage in the ML operations workflow, as it helps identify the most effective approach for detecting patient falls in the sample video collected during the previous phase. Data scientists utilize various strategies and optimizations to produce accurate results using their mathematics and machine learning expertise. To find patterns suggestive of a fall, data scientists may experiment with various video image processing methods, such as object detection or motion analysis algorithms. To enhance the functionality of the machine learning program, they can also change variables like color or image quality (such as contrast, brightness, and sharpness). These experiments and modifications aim to identify the ideal settings and algorithms that produce maximum fall detection accuracy. In this iterative process, several strategies are tested, their effectiveness is evaluated, and the model is adjusted to produce the desired outcomes. It’s important to remember that finding the model and parameters that would most effectively detect patient falls in the test video may require several modifications and experiments. Data scientists iteratively improve the fall detection accuracy of the ML application using their domain knowledge, machine learning expertise, and data analysis skills. 5/23
Stage-3: Experiment with data and model training and tuning with hyperparameters As data scientists test different settings and algorithms, keeping track of each trial and test iteration is important. Proper documentation of machine learning models, along with the data and parameters employed in testing, is essential for future reference, and advanced tools can assist in recording and maintaining this information accurately. Data scientists perform experiments and fine-tune the hyperparameters of their models to optimize performance. They can leverage their chosen cloud platform’s ability to spin up multiple instances, allowing them to run numerous experiments simultaneously and efficiently explore different configurations. Hyperparameter tuning Hyperparameter tuning is a crucial phase in the machine learning model optimization process. Data scientists frequently use hyperparameter tuning to enhance the model’s performance after selecting an algorithm and optimizing it with labeled data. Hyperparameters refer to the adjustable settings or configuration variables that are determined before the learning process begins. These parameters are not learned from the data but are set by the practitioner or researcher to control the behavior and performance of the learning algorithm. Hyperparameter tuning involves experimenting with different values of hyperparameters, such as the number of layers, learning rate, batch size, and regularization methods, to fine-tune the model’s architecture and determine the optimal combination that enhances the model’s performance. For instance, to improve the performance of a neural network model, data scientists may change the number of layers, the size of each layer, and the activation functions employed in each layer. They may also change regularization-related hyperparameters to avoid over fittings, such as the strength of L1 or L2 regularisation. Hyperparameter tweaking often entails training the model with various combinations of hyperparameter values, assessing the model’s performance using the right evaluation metrics, and repeating the process. Using this iterative technique, data scientists can find the optimal hyperparameter values that enhance model performance. Hyperparameter tuning is a continuous process that may involve numerous iterations and experiments to fine-tune the model for optimum performance. One must thoroughly understand the model’s architecture, underlying data, and problem to evaluate the results and decide which hyperparameter values to use. Finishing the experimental phase 6/23
The final product of the ML operations experimental phase is a configured algorithm that performs efficiently on test data, and is demonstrably functional. Additionally, by the end of this stage, there will be a list of every experiment conducted and all the outcomes they produced. Production phase Let’s now understand the processing of the production stage. This phase aims to set up an entirely tested ML application (a packed binary) on the hospital’s camera system. Stage-1: Transform the data The initial stage in the production phase involves training the application with the complete data set. It’s worth noting that the experimentation in the previous phase used a portion of the entire dataset. The original quantity of test data is also used for assessment. Stage-2: Train the model You need scalable and effective training methods, including distributed training techniques, to train a machine learning model with a big dataset. Here are a few approaches that are frequently employed in this situation: Data parallelism In data parallelism, the dataset is divided into smaller batches, and each batch is processed simultaneously on several computing devices, such as GPUs. Because many batches can be processed concurrently, this enables effective parallel processing of the data, resulting in shorter training times. The model weights are then updated using the aggregated gradients calculated from each computing resource, often using methods like gradient averaging or gradient summation. Even though the model is being run in parallel across various computational resources, this synchronization of gradients and weight updates helps to ensure that the model learns from the aggregate information in the entire dataset. In large- scale machine learning scenarios, when the dataset is too huge to fit into the memory of a single computational resource, data parallelism is a popular method for speeding up the training process. Model parallelism Model parallelism refers to the parallel processing of several model components on various computing resources, such as GPUs or computers. This is helpful if the model architecture is intricate and consumes more memory than a single computing resource can hold. The outputs of each computer resource are usually processed on a subset of layers or neurons and then combined to generate the final prediction. 7/23
Model parallelism calls for careful planning and coordination between the various computational resources to ensure consistent changes to the model weights. For instance, to ensure consistency throughout the model, each resource must be aware of any updates to its model components and adjust its computations accordingly. Coordination may utilize methods like message forwarding, synchronization, or averaging model weights to ensure that all computing resources use the most recent data. Model parallelism is frequently used when a model’s architecture is complicated and its computing demands are greater than a single computing resource can handle. Careful design and implementation are necessary to ensure consistency in the model updates and achieve optimal performance to enable effective coordination and communication among the compute resources. Parameter server In the parameter server architecture, the model parameters are kept on a specific server referred to as the parameter server. During the training phase, several computing resources, whether GPUs or computers, communicate with the parameter server to fetch and update the model parameters. Each computing resource may separately compute gradients and update the model parameters, enabling the effective distribution of the model parameters across various computing resources and parallel processing. The parameter server is a central location in this architecture for maintaining and storing the model parameters. When updating the model parameters, compute resources, often referred to as workers, typically retrieve the most recent model parameters from the parameter server, perform calculations on their local data, compute gradients, and then send the gradients back to the parameter server. This method speeds up the training process, which enables parallel data processing across different computing resources. Various approaches to implementing parameter server topologies include synchronous or asynchronous updates. Synchronous updates ensure that every worker utilizes the same set of parameters by having all computing resources wait for the gradients from every worker before changing the model parameters. In asynchronous updates, each worker individually updates the model parameters based on its own computed gradients without waiting for other workers. As workers may update the model parameters at different times, asynchronous updates can be more scalable but may lead to parameter inconsistencies. In distributed training settings, parameter server architectures are frequently employed when the dataset is vast and the model needs a lot of computational power to train. To enable effective updates to the model parameters and preserve consistency during training, rigorous communication management and coordination between the parameter server and computing resources is necessary. 8/23
The training must be closely monitored to ensure smooth progress and identify potential problems or abnormalities. Real-time tracking of variables, including loss, accuracy, and convergence rate, as well as visualizing training progress, may be involved in monitoring. These are typical machine learning model training techniques when working with a huge dataset. The particulars of the problem influence the selection of a method or combination of methods, the computing resources at hand, and the scalability of the machine learning framework being utilized. It is crucial to design and implement these approaches carefully to ensure efficient and effective training of the model on the vast dataset being used. Version control The ML operations method relies heavily on version control to maintain and monitor various iterations of the machine learning models throughout their production process. This promotes collaboration, traceability, and reliability among team members. The popular open-source DVC (Data Version Control) tool is used for version control in machine learning applications. You can track changes to data, code, and models using DVC, which also produces a versioned repository where you can store and manage various iterations of these assets. To manage the end-to-end ML workflow, DVC offers capabilities like data lineage, tracking model metrics, and reproducibility. Stage-3: Serve the model Once the model is fully operational and its versions are tracked in a repository, it can be further modified and optimized. This involves certain testing methods, which are: A/B testing and canary testing The ML operations process frequently employs A/B testing and canary testing to assess the effectiveness of various model iterations in a production environment and come to data- driven model deployment decisions. A/B testing, often known as split testing, compares the performance of two or more model versions operating concurrently in a production environment using predetermined metrics. Typically, a portion of the incoming data is divided randomly among the many model iterations, and the predictions are compared. This enables a quantitative evaluation of how the new model version compares to an earlier version or a baseline model in terms of performance. Based on the findings, decisions might be made regarding whether to completely deploy the new model version or revert to the older version. On the other hand, canary testing is gradually introducing a new model version to a portion of the production data, often beginning with a small proportion and increasing the amount of data it processes as it demonstrates its performance. As a result, it is possible to gradually 9/23
evaluate the new model version in a real-world setting and spot any problems or inconsistencies immediately. Once the new model version has demonstrated its performance and stability, it can be fully deployed to handle the entire burden of production data. A/B and canary testing offer strategies to evaluate the performance of various model versions and make wise model deployment decisions. By reducing risks and ensuring a seamless model deployment in a real-world scenario, these strategies ensure that only stable and high-performing model versions are deployed to meet the production burden. Stage-4: Monitor the model’s performance After deploying the model, it is essential to monitor its performance, and it can be checked using various ways: Drift monitoring Once we deploy a model into production, monitoring the system for CPU and memory usage and other project-specific infrastructure performance, like data bandwidth, camera power states, etc., is important. However, “drift monitoring” (model or data drift) is also conducted. There are two forms of model drift. The first one is called the train inference, drift, or skew. Maintaining a production machine learning system requires careful attention to model drift. Model performance can deteriorate over time due to model drift, defined as changes in the distribution or quality of the data the model uses. Data drift can be introduced when cameras are upgraded from HD to Ultra High Definition (UHD) video feeds. The performance of the trained model may be impacted by differences in the statistical features of the data, such as pixel values, color distributions, and object sizes, caused by the resolution change from 720p HD to 4K UHD. Drift monitoring strategies, which entail contrasting the distributions of incoming data and the data used during model training, can be used to identify and correct model drift. Here are a few typical methods for drift monitoring: Statistical monitoring: It is possible to compare the statistical characteristics of the incoming data with the training data using statistical techniques like hypothesis testing. For instance, you can compute and compare statistics for the data distributions, such as mean, variance, and covariance. Significant departures from the predicted statistical features may indicate drift. Drift detection algorithm: Several techniques for detecting drift, including the Wasserstein distance, Kullback-Leibler divergence, and Kolmogorov-Smirnov test, can be used to identify changes in data distribution. These algorithms can offer numerical drift measurements and be added to a monitor pipeline to send alerts when drift is found. 10/23
Visualization and manual inspection: Plotting data points or creating heatmaps that depict the data distributions can help visually inspect the data and help spot potential drift. Drift can also be found by manual inspection by subject-matter specialists who thoroughly understand the application and data. If drift is found, the proper steps can be taken to remedy it. Address the underlying changes in data quality or distribution; this may entail retraining the model with the updated data, adjusting the model dynamically during inference, or implementing remedial measures in the data collection or preprocessing pipeline. In a production context, it’s crucial to conduct routine checks for model drift to ensure the deployed model keeps functioning properly and delivers accurate predictions. Drift monitoring helps maintain the machine learning system’s performance and accuracy, particularly when the production environment or data properties change. How to implement MLOps? Depending on the extent of automation for each pipeline stage, there are three different ML operation levels. Let’s discuss each one individually. MLOps level 0 (Manual process) The first step in integrating MLOps practices into a machine learning workflow is MLOps level 0, sometimes called the “Manual process” level. The workflow is entirely manual at this level, and if scripts are utilized, they frequently call for last-minute adjustments to accommodate various testing scenarios. This may hinder the effective deployment of machine learning models by causing inconsistencies, delays, and higher risks of errors. Organizations can automate their MLOps procedures to mitigate these challenges. The pipeline typically consists of several processes: Exploratory Data Analysis (EDA), data preparation, model training, evaluation, fine-tuning, and deployment. However, logging, modeling, and experiment tracking are not implemented or performed inefficiently. Manual approaches may be adequate in certain cases where machine learning models are rarely changed, and the aim is merely to experiment and discover rather than be ready for production deployments. Manual procedures may provide flexibility and agility for quick iterations and testing of various model versions in research- or experimental-oriented environments where models constantly develop. In ML operations level 0, continuous integration and deployment (CI/CD) pipelines—typical in DevOps practices—are frequently ignored or not fully implemented. MLOps level 1 (ML pipeline automation) MLOps Level 1 incorporates automated methods for training machine learning models through continuous training (CT) pipelines, building on the fundamentally manual approach of level 0. At this stage, the emphasis is on orchestrating experiments and feedback loops to 11/23
ensure high model quality while automating the machine learning workflow. Machine learning models trained automatically via pipelines eliminate the need for user involvement. With the help of CT pipelines, organizations can regularly update and develop their models to reflect the most recent data and operational needs. Key features of MLOps level 1 include: Rapid experiment: ML experiment phases are coordinated and automated, enabling more rapid iterations and effective model creation and training procedures. Continuous training of the model in production: The model is automatically trained during production utilizing new data based on active pipeline triggers. This continuous training approach ensures the model is constantly updated with the most recent data for greater accuracy and performance. Experimental-operational symmetry: The pipeline used in the pre-production and production environments is the same in the development or experiment environment. This unifies the development and operational workflows and ensures consistency throughout each phase of the machine learning lifecycle. Modularized code for components and pipelines: For easy development and deployment of ML pipelines and to encourage code reuse and maintainability, ML pipelines are built using reusable, composable, and maybe shareable components, such as containers. A container is a standardized software unit that packs up code and all its dependencies to ensure an application runs swiftly and consistently in different computing environments. Continuous delivery of models: Model deployment is automated, allowing for the seamless and quick deployment of updated models into production systems. This stage uses the trained and validated model as a forecasting service for online predictions. Pipeline deployment: MLOps level 1, or “Training Pipeline Deployment,” automates and integrates the whole training pipeline, including data preparation procedures, feature engineering, model training, and evaluation. As a result, the training pipeline can be fully automated and activated depending on predetermined timetables or events, including the model training process. By implementing the training pipeline as an automated system, businesses can ensure that the model is trained using the most recent data and training methods. This enables the model to adjust and learn from the most recent data, enhancing its accuracy and performance. Automated training pipelines also ensure consistency and repeatability during the model training process, lowering the possibility of mistakes and inconsistencies caused by human error. By putting these practices into reality, businesses may increase their machine learning operations’ automation, efficiency, and dependability, enabling them to scale up their ML services, enhance the quality of their models, and respond promptly to changing business 12/23
and data requirements. The team must incorporate metadata management, pipeline triggers, and automated data and model validation procedures to automate retraining production models with new data. MLOps level 2 (CI/CD pipeline automation) A powerful combination incorporating continuous training with CI/CD enables data scientists to experiment with different parts of the ML pipeline, such as feature engineering, model architectures, and hyperparameters, while ensuring robustness, version control, reliability, and scalability. MLOps level 2, commonly called the CI/CD pipeline, is a crucial element in the workflow for machine learning operations. It automatically creates the source code, executes tests, and packages the model files, logging files, metadata, and other artifacts that are part of the ML pipeline. Unit testing can be performed for many parts of the ML pipeline and is used to validate the accuracy and functionality of individual code or components. Unit testing can reduce the risk of incorporating mistakes or faults into the production system by identifying potential problems in the context of ML pipeline components, such as division by zero or NaN (Not a Number) values. Organizations can reduce the risk of releasing incorrect models into production by introducing unit testing into the continuous integration process. Continuous training and CI/CD work together to allow organizations to iteratively and quickly experiment with various ML pipeline configurations, test their performance, and seamlessly deploy updated components, resulting in more reliable, repeatable, and scalable ML processes. This strategy suits businesses that regard machine learning as their main product and need ongoing innovation to remain competitive. Key components of MLOps Level 2 include: Development and experimentation: It involves the iterative testing of new ML algorithms and modeling techniques, where the experiment phases are planned. The source code for the ML pipeline steps is produced at this stage and is then uploaded to a source repository. Pipeline continuous integration: Building source code and running various tests constitute phases in a continuous integration pipeline. Packages, executables, and artifacts are the results of this step, which will be deployed later. Automated triggering: The standard ML pipeline is automated and programmed to operate in a production environment according to a predetermined schedule or in response to a trigger, such as an event or a change in the data. A newly trained model is generated from the training process once the pipeline has been run and uploaded to the model database for application in production. 13/23
Model continuous delivery: The trained model is deployed as a prediction service, providing user predictions. After the trained model has been uploaded to the model database, it can be included in a prediction service that exposes an API or other interfaces for forecasting fresh data. Depending on the needs of the organization and the infrastructure configuration, this prediction service may be deployed to a production environment, such as a cloud server, a containerized environment, or other infrastructure. The prediction service usually gets input data, processes it using the trained model, and outputs predictions. Depending on the specific use case and business objectives, the predictions may be utilized for various purposes, including creating insights, classifying data, making suggestions, and predicting outcomes. Monitoring: In ML operations, monitoring and keeping track of the performance of the deployed model in use is crucial. Organizations can use real-time data to compile statistics on the model’s performance in the production environment. Depending on the particular use case and requirements, monitoring and performance tracking mechanisms can be implemented in the deployed model prediction service to gather pertinent metrics, such as prediction accuracy, latency, resource utilization, error rates, or other performance indicators. The result of this monitoring and performance tracking phase can be used as a trigger to run the ML pipeline once again or to begin a new cycle of tests. For instance, if the model’s prediction accuracy falls below a predetermined level, it might require to be retrained with newer data or tested with various techniques or hyperparameters. If the model’s prediction latency rises above a certain threshold, it may prompt performance improvements in the deployment infrastructure or model architecture. How to build an MLOps pipeline? Let’s learn how to build a continuous integration pipeline for a machine-learning project. Before continuing, let’s clarify what exactly CI is. Continuous integration continuously integrates and tests change to a common repository in an artificial intelligence project. By automatically testing any code modifications, CI makes spotting issues promptly throughout the development stage easier. The steps to build an MLOps CI pipeline are as follows: Step-1: Build the workflow Suppose 3 experiments are being conducted named A, B, and C, and after experimenting with various processing methods and ML models, experiment C performs remarkably well. As a result, we want to include the code and model in the main branch. The undermentioned actions must be taken to achieve this: Version the experiment’s inputs and outcomes: 14/23
To version the inputs and outputs of an experiment involving a pipeline, including the code, data, and model, we will use the DVC. The pipeline is defined based on the file locations in the project. In the dvc.yaml file, we will outline the pipeline steps and the data dependencies that exist between them: stages: process: cmd: python src/process_data.py deps: - data/raw - src/process_data.py params: - process - data outs: - data/intermediate train: cmd: python src/train.py deps: - data/intermediate - src/train.py params: - data - model - train outs: - model/svm.pkl 15/23
evaluate: cmd: python src/evaluate.py deps: - model - data/intermediate - src/evaluate.py params: - data - model metrics: - dvclive/metrics.json Type the following command into your terminal to launch an experiment pipeline specified in dvc.yaml: dvc exp run We will get the following output: 'data/raw.dvc' didn't change, skipping Running stage 'process': > python src/process_data.py Running stage 'train': > python src/train.py Updating lock file 'dvc.lock' Running stage 'evaluate': > python src/evaluate.py The model's accuracy is 0.65 Updating lock file 'dvc.lock' 16/23
Ran experiment(s): drear-cusp Experiment results have been applied to your workspace. To promote an experiment to a Git branch run: dvc exp branch The dvc.lock file, which contains the precise versions of the data, code, and dependencies between them, is automatically generated by the run. The same experiment can be repeated in the future by using identical versions of the inputs and outputs. schema: '2.0' stages: process: cmd: python src/process_data.py deps: - path: data/raw md5: 84a0e37242f885ea418b9953761d35de.dir size: 84199 nfiles: 2 - path: src/process_data.py md5: 8c10093c63780b397c4b5ebed46c1154 size: 1157 params: params.yaml: data: raw: data/raw/winequality-red.csv intermediate: data/intermediate process: 17/23
feature: quality test_size: 0.2 outs: - path: data/intermediate md5: 3377ebd11434a04b64fe3ca5cb3cc455.dir size: 194875 nfiles: 4 Step-2: Upload the data model to remote storage Data files and models created by pipeline stages in the dvc.yaml file can be easily uploaded by DVC to a remote storage location. Before uploading our files, we will specify the remote storage location in the file .dvc/config : ['remote "read"'] url = https://winequality-red.s3.amazonaws.com/ ['remote "read-write"'] url = s3://winequality-red/ Ensure that the “read-write” remote storage URI is substituted for the URI of your S3 bucket. Push files to the “read-write” remote storage location: dvc push -r read-write Step-3: Create tests We will also create tests that confirm the functionality of the code in charge of handling data processing, training the model, and the model itself, guaranteeing that the code and model live up to our expectations. Step-4: Create a GitHub workflow The fun part is building a GitHub workflow to automate your data and model testing. In the file.github/workflows/run_test.yaml, we will build the process titled Test code and model: name: Test code and model 18/23
on: pull_request: paths: - conf/** - src/** - tests/** - params.yaml jobs: test_model: name: Test processed code and model runs-on: ubuntu-latest steps: - name: Checkout id: checkout uses: actions/checkout@v2 - name: Environment setup uses: actions/setup-python@v2 with: python-version: 3.8 - name: Install dependencies run: pip install -r requirements.txt - name: Pull data and model env: AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }} AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }} 19/23
run: dvc pull -r read-write - name: Run tests run: pytest - name: Evaluate model run: dvc exp run evaluate - name: Iterative CML setup uses: iterative/setup-cml@v1 - name: Create CML report env: REPO_TOKEN: ${{ secrets.TOKEN_GITHUB }} run: | # Add the metrics to the report dvc metrics show --show-md >> report.md # Add the parameters to the report cat dvclive/params.yaml >> report.md # Create a report in PR cml comment create report.md The on field indicates that a pull request event triggers the pipeline. The steps in the test_model job are as follows: Examining the code The Python environment setup\Setting up dependencies Using DVC to fetch information and models Using Pytest to run tests Model evaluation with DVC experiments Establishing the environment for iterative CML (continuous machine learning) Making a report with metrics and parameters and using CML to remark on the pull request while using the report. 20/23
Note that the following are necessary for the work to perform effectively: AWS login information for pulling the data and A model GitHub token for pulling comments. We will employ encrypted secrets to make sure that sensitive data is stored securely in our repository and give GitHub Actions access to it. All done! Let’s try this experiment to see if it performs as planned. Setup Create a new repository using the project template to try out this project. Clone the repository to your local machine: git clone https://github.com/your-username/cicd-mlops-demo Setup the environment: # Go to the project directory cd cicd-mlops-demo # Create a new branch git checkout -b experiment # Install dependencies pip install -r requirements.txt Pull data from the remote storage location called “read”: dvc pull -r read Create experiments If the params.yaml file or any files in the src and tests directories are modified, and the GitHub workflow will be activated. We’ll make a few changes to the params.yaml file to demonstrate this. Next, let’s create a new experiment with the change: dvc exp run Push the modified data and model to remote storage called “read-write”: dvc push -r read-write 21/23
Add, commit, and push changes to the repository: git add . git commit -m 'add 100 for C' git push origin experiment Create a pull request Next, click the Contribute button to start a pull request. A GitHub workflow will be triggered after a pull request is created in the repository to perform tests on the code and model. The metrics and settings of the new experiment will be included in a comment that will be submitted to the pull request if all the tests pass. This information makes it simpler for reviews to comprehend the code and model changes that have been done. They can then decide quickly whether to approve the PR for merging into the main branch by assessing if the changes fulfill the anticipated performance criteria. MLOps is a crucial technique that streamlines the deployment, monitoring, and upkeeping of machine learning models in production by fusing the ideas of DevOps with machine learning. To ensure that machine learning models are reliable, scalable, and continuously optimized for performance, ML operations span several stages of the machine learning lifecycle, including model development, testing, deployment, and monitoring. Enhancing the stability and dependability of machine learning models is one of ML operations’ main advantages. ML operations help discover and fix issues early in the model’s lifespan, lowering the chance of production failures and minimizing downtime. ML operations is a vital practice that equips businesses with the tools they need to operationalize machine learning successfully, enabling the efficient, scalable, and reliable deployment of machine learning models in real-world settings. Organizations may speed up creating and using machine learning models, boost performance, and increase communication between data science and IT operations teams by implementing ML operations principles. This will enable machine learning to be successfully applied in real- world scenarios. As businesses work to integrate artificial intelligence and machine learning into their business operations, the use of ML operations has become increasingly vital. ML operations make it easier for data science teams and IT operations to work together while ensuring that machine learning models are efficiently deployed and managed in production settings. 22/23
Elevate your ML workflows with MLOps! Connect with LeewayHertz’s experts for efficient and effective ML operations. Contact now! 23/23