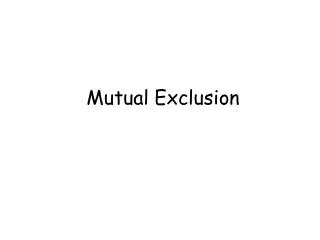Download

1 / 62
620 likes | 629 Views
Explore distributed mutual exclusion algorithms for concurrent access to shared resources in computer systems, including token-based and permission-based solutions, with centralized and decentralized approaches. Learn about basic algorithms and the challenges faced in implementing distributed algorithms in various applications.

E N D
Mutual exclusion • Concurrent access of processes to a shared resource or data is executed in mutually exclusive manner • Distributed mutual exclusion can be classified into two different categories. • Token based solutions • Permission based approach
Token based approach In token based solutions mutual exclusion is achieved by passing a special message between the processes, known as a token.
processes share a special message known as a token. There is only one token available. Token holder has right to access shared resource Wait for/ask for (depending on algorithm) token; enter Critical Section when it is obtained and pass to another process on exit. If a process receives the token and doesn’t need it, just pass it on.
Overview - Token-based Methods Advantages: Starvation can be avoided by efficient organization of the processes Deadlock is also avoidable Disadvantage: token loss Must initiate a cooperative procedure to recreate the token Must ensure that only one token is created!
Permission-based solutions process that wishes to access a shared resource must first get permission from one or more other processes. Avoids the problems of token-based solutions, but is more complicated to implement.
Basic Algorithms Centralized Decentralized Distributed Distributed with “voting” – for increased fault tolerance Token ring algorithm
Centralized algorithm One process is elected as the coordinator. Whenever a process wants to access a shared resource, it sends a request message to the coordinator stating which resource it wants to access and asking for permission.
If no other process is currently accessing that resource, the coordinator sends back a reply granting permission.
Mutual ExclusionA Centralized Algorithm Figure 6-14. Process 1 asks the coordinator for permission to access a shared resource. Permission is granted.
Mutual ExclusionA Centralized Algorithm Figure 6-14 Process 2 then asks permission to access the same resource. The coordinator does not reply.
Mutual ExclusionA Centralized Algorithm Figure 6-14. (c) When process 1 releases the resource, it tells the coordinator, which then replies to 2.
Centralized Mutual Exclusion Central coordinator manages requests FIFO queue to guarantee no starvation 0 1 2 0 1 2 0 1 2 OK Request Release Request OK 3 3 3 2 No Reply Wait Queue Figure 6-14
Decentralized algorithm • Based on the Distributed Hash Table (DHT) system structure • Object names are hashed to find the node where they are stored • n replicas of each object are placed on n successive nodes • Hash object name to get addresses • Now every replica has a coordinator that controls access
Coordinators respond to requests at once: Yes or No For a process to use the resource it must receive permission from m > n/2 coordinators. If the requester gets fewer than m votes it will wait for a random time and then ask again. If a request is denied, or when the CS is completed, notify the coordinators who have sent OK messages, so they can respond again to another request.
Distributed algorithms are the backbone of distributed computing systems. They are essential for the implementation of distributed systems. Distributed operating systems Distributed databases Distributed communication systems Real-time process-control systems Transportation systems, etc.
A distributed algorithm is an algorithm designed to run on computer hardware constructed from interconnected processors. Distributed algorithms are used in many varied application areas of distributed computing, such as telecommunications, scientific computing, distributed information processing, and real-time process control. Standard problems solved by distributed algorithms include leader election, consensus, distributed search, spanning tree generation, mutual exclusion, and resource allocation. .
Distributed algorithms are typically executed concurrently, with separate parts of the algorithm being run simultaneously on independent processors, and having limited information about what the other parts of the algorithm are doing. One of the major challenges in developing and implementing distributed algorithms is successfully coordinating the behavior of the independent parts of the algorithm in the face of processor failures and unreliable communications links.
Distributed Mutual Exclusion Probabilistic algorithms do not guarantee mutual exclusion is correctly enforced. Many other algorithms do, including the following. Originally proposed by Lamport, based on his logical clocks and total ordering relation Modified by Ricart-Agrawala
The Algorithm Two message types: Request Critical Section: sent to all processes in the group Reply/OK: A message eventually received at the request site, Si, from all other sites. Messages are time-stamped based on Lamport’s total ordering relation, with logical clock, process id.
Requesting When a process Pi wants to access a shared resource it builds a message with the resource name, pid and current timestamp: Request (ra, tsi, i) A request sent from P3 at “time” 4 would be time-stamped (4.3). Send the message to all processes, including yourself. Assumption: message passing is reliable.
Processing a Request Pi sends a Request (ra, tsi, i) to all sites. When Pk receives the request it inserts it on its own queue and sends a Reply (OK) if it is not in the critical section and doesn’t want the critical section does nothing, if it is in its critical section If it isn’t in the CS but would like to be, sends a Reply if the incoming Request has a lower timestamp than its own, otherwise does not reply.
Executing the Critical Section Pi can enter its critical section when it has received an OK Reply from every other process. At this time its request message will be at the top of every queue.
Distributed algorithms outline Synchronization Distributed mutual exclusion: needed to regulate accesses to a common resource that can be used only by one process at a time Election Used for instance, to design a new coordinator when the currentcoordinator fails
A Distributed Algorithm (1) Three different cases: If the receiver is not accessing the resource and does not want to access it, it sends back an OK message to the sender. If the receiver already has access to the resource, it simply does not reply. Instead, it queues the request. If the receiver wants to access the resource as well but has not yet done so, it compares the timestamp of the incoming message with the one contained in the message that it has sent everyone. The lowest one wins.
A Distributed Algorithm (2) Figure 6-15. (a) Two processes want to access a shared resource at the same moment.
A Distributed Algorithm (3) Figure 6-15. (b) Process 0 has the lowest timestamp, so it wins.
A Distributed Algorithm (4) Figure 6-15. (c) When process 0 is done, it sends an OK also, so 2 can now go ahead.
Distributed algorithms: outline Distributed agreement Distributed agreement is used for To determine which nodes are alive in the system To control the behavior of some components In distributed databases to determine when to commit a transaction Fault tolerance
Distributed algorithms: outline Check-pointing and recovery Error recovery is essential for fault-tolerance When a processor fails and then is repaired, it will need to recover its state of the computation To enable recovery, check-pointing (recording of the state into a stable storage) is needed
A Token Ring Algorithm Previous algorithms are permission based, this one is token based. Processors on a bus network are arranged in a logical ring, ordered by network address, or process number (as in an MPI environment), or some other scheme. Main requirement: that the processes know the ordering arrangement.
Algorithm Description At initialization, process 0 gets the token. The token is passed around the ring. If a process needs to access a shared resource it waits for the token to arrive. Execute critical section & release resource Pass token to next processor. If a process receives the token and doesn’t need a critical section, hand to next processor.
Lost Tokens What does it mean if a processor waits a long time for the token? Another processor may be holding it It’s lost No way to tell the difference; in the first case continue to wait; in the second case, regenerate the token.
A Token Ring Algorithm Figure 6-16. (a) An unordered group of processes on a network. (b) A logical ring constructed in software.
A Comparison of the Four Algorithms Figure 6-17. A comparison of three mutual exclusion algorithms.
In general, election algorithms attempt to locate the process with the highest process number and designate it as coordinator.
Motivation We often need a coordinator in distributed systems Leader, distinguished node/process If we have a leader, mutual exclusion is trivially solved The leader determined who enters CS If we have a leader, totally ordered broadcast trivially solved The leader stamps messages with consecutive integers 38
What is Leader Election? • In distributed computing, leader election is the process of designating a single process as the organizer, coordinator, initiator or sequencer of some task distributed among several computers (nodes). • Leader election is the process of determining a process as the manager of some task distributed among several processes (computers).
Why is Leader Election Required? The existence of a centralized controller greatly simplifies process synchronization. However, if the central controller breaks down, the service availability can be limited. The problem can be avoided if a new controller (leader) can be chosen. Different Algorithms would be employed to successfully elect the leader
When any process notices that the coordinator is no longer responding to requests, it initiates an election. A process P, holds an election as follows.
P sends an ELECTION message to all processes with higher numbers. If no one responds, P wins the election and becomes coordinator. If one of the higher-ups answers, it takes over. P’s job is done.
Bully Algorithm When a process P notices that current coordinator has failed, it sends an ELECTION message to all processes with higher IDs. If no one responds, P becomes the leader. If a higher-up receives P’s message, it will send an OK message to P and execute the algorithm. Process with highest ID takes over as coordinator by sending COORDINATOR message. If a process with higher ID comes back, it takes over leadership by sending COORDINATOR message.
At any moment, a process can get an ELECTION message from one of its lower-numbered colleagues. When such a message arrives, the receiver sends an OK message back to the sender to indicate that he is alive and will take over.
The receiver then holds an election, unless it is already holding one. Eventually , all processes give up but one, and that one is the new coordinator. It announces its victory by sending all processes a message telling them that starting immediately it is the new coordinator.
Bully Algorithm - Example Process 4 holds an election Process 5 and 6 respond, telling 4 to stop Now 5 and 6 each hold an election
Bully Algorithm - Example Process 6 tells 5 to stop Process 6 wins and tells everyone
A ring algorithm Assume that all processes are physically or logically ordered, so that each process knows who is successor is. When any process notices that the coordinator is not functioning, it builds an ELECTION message containing its own process number and sends a message to its successor.
If the successor is down, the sender skips over the successor and goes to the next number along the ring ,or the one after that, until a running process is located. At each step along the way, the sender adds its own process number to the list in the message effectively making itself a candidate to be elected as coordinator.