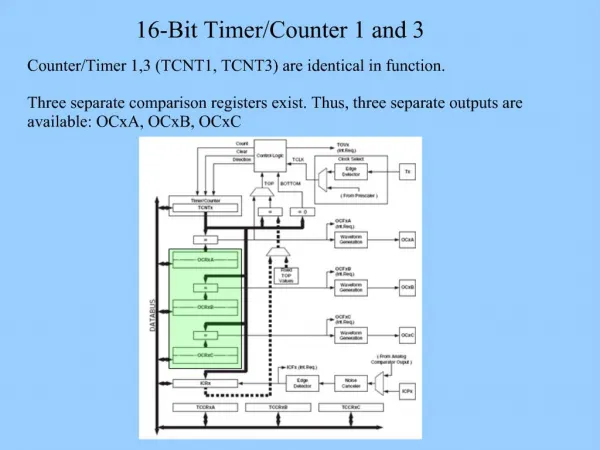
Download

1 / 20
200 likes | 217 Views
Proposal for an invertible 16-bit architecture with low complexity for H.26L codec, offering improved performance and reduced complexity. Includes details on 16-bit proposals, relative merits, motivation, performance-complexity, and detailed implementation.

E N D
A 16-Bit Invertible Architecture for H.26L Pankaj Topiwala FastVDO Inc. Columbia, MD 21044 VCEG-N24
Proposal Features • Our solution (uniquely) offers low-complexity, invertible 16-bit architecture for 12-bit input • Approach first proposed at Austin Mtg, April, 01 • Full disclosure (M16) • Word doc, PPT, Excel, SW insertion (tml5.2), Example reconstructions • Now offered conditionally royalty-free
16-Bit Proposals • N20 (Sharp) and N22 (TI) – keep current transform, refactorize quantization method. Get 9-bits in, 16-bits out • Encoder not 16-bit for N20 • New 4-pt transform methods: • N24 (FastVDO): [1 1 1 1; 5-2 2-5; 1-1-1 1; 1-2 2 -1]* • N44 (MS): [1 1 1 1; 2 1-1-2; 1-1-1 1; 1-2 2-1] • N43 (Nokia): [a a a a; b c -c -b;a -a -a a;c -b b -c] *FastVDO actually offers a series of 4-pt transforms, of which this is the lowest complexity solution.
Relative Merits • Comparisons • All 5 virtually match current 32-bit performance • All offer reduced, nearly identical complexity • Only N24 offers16-bit architecture for 12-bit input • Room for improvement by scaling tricks • Only N24 offers exact invertibility • Fast, low-bit 8-pt, 16-pt transforms ready (e.g. ABT)
Motivation • Similar coding performance as the DCT • Supporting a 16-bit (or less) architecture • Low complexity, multiplierless implementation (adds, right shifts) • Invertible integer-to-integer mapping • In-place computation
DCT • Coding gain: 7.57 dB; Complexity: 8 adds, 6 mults in floating point • Integer approximation:
1 2 3 4 Previous Integer DCT p 7/16 3/8 1/2 1/2 - - u 3/8 3/8 3/8 1/2 - - # adds 10 10 9 8 8 (16) 8 # shifts 5 5 4 3 0 (8) 0 # mults 0 0 0 0 6 (0) 6 CG in dB 7.57 7.56 7.55 7.55 7.57 7.57 Performance-Complexity
x[0] Y[0] >>1 x[1] Y[2] x[2] Y[3] >>1 >>3 >>1 >>4 x[3] Y[1] Detailed Implementation • Using only binary right-shifts • Biorthogonal (nearly orthog.) • Linear (up to bit constraint)
Coding Performance in H.26L • PSNRs in Excel file (N24.xls) • No performance loss comparing to the previous integer transform
Scaling Matrix • Approximate uniform quantization for all transform coefficients
Approximation Accuracy • MSE between the basis functions • MSE between the produced coefficients
8 x 8 BinDCT Coding gain: 8.77 to 8.82 dB for AR(1) process with p=0.95
16 x 16 BinDCT Coding gain: 9.4499 dB for AR(1) process with p=0.95
Conclusion • Fast multiplier-free transform • Supporting a 16-bit architecture for 12-bit input • Explicit 16-bit quantization tables provided (V24qtable.zip) • Similar coding performances to current transform • Invertible integer-to-integer mapping