Download

1 / 64
640 likes | 754 Views
Recent developments in tree induction for KDD « Towards soft tree induction ». Louis WEHENKEL University of Liège – Belgium Department of Electrical and Computer Engineering. A. Supervised learning (notation). x = ( x 1 ,…, x m ) vector of input variables (numerical and/or symbolic)

E N D
Recent developments in tree induction for KDD« Towards soft tree induction » Louis WEHENKEL University of Liège – Belgium Department of Electrical and Computer Engineering
A. Supervised learning (notation) • x = (x1,…,xm) vector of input variables (numerical and/or symbolic) • y single output variable • Symbolic : classification problem • Numeric : regression problem • LS = ((x1,y1),…,(xN,yN)), sample of I/O pairs • Learning (or modeling) algorithm • Mapping from sample sp. to hypothesis sp.H • Say : y = f(x) + e , where ‘e’ = modeling error • « Guess » ‘fLS’ in H so as to minimize ‘e’
Statistical viewpoint • x and y are random variables distributed according to p(x,y) • LS is distributed according to pN(x,y) • fLS is a random function (selected in H) • e(x) = y – fLS(x) is also a random variable • Given a ‘metric’ to measure the error we can define the best possible model (Bayes model) • Regression : fB(x) = E(y|x) • Classification : fB(x) = argmaxy P(y|x)
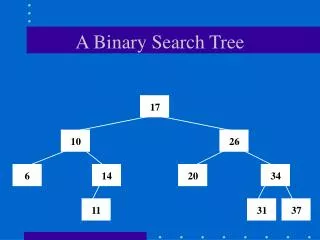
B. Crisp decision trees (what is it ?) X1<0.6 Yes No X2<1.5 Y is big Yes No Y is very big Y issmall
B. Crisp decision trees (what is it ?) X2=1.5 X1=0.6
Tree induction (Overview) • Growing the tree (uses GS, a part of LS) • Top down (until all nodes are closed) • At each step • Select open node to split (best first, greedy approach) • Find best input variable and best question • If node can be purified split, otherwise close the node • Pruning the tree (uses PS, rest of LS) • Bottom up (until all nodes are contracted) • At each step • Select test node to contract (worst first, greedy…) • Contract and evaluate
Tree Growing • Demo : Titanic database • Comments • Tree growing is a local process • Very efficient • Can select relevant input variables • Cannot determine appropriate tree shape • (Just like real trees…)
Tree Pruning • Strategy • To determine appropriate tree shape let tree grow too big (allong all branches), and then reshape it by pruning away irrelevant parts • Tree pruning uses global criterion to determine appropriate shape • Tree pruning is even faster than growing • Tree pruning avoids overfitting the data
Underfitting Overfitting Pruning Growing Final tree Growing – Pruning (graphically) Error (GS / PS) Tree complexity
C. Soft trees (what is it ?) • Generalization of crisp trees using continuous splits and aggregation of terminal node predictions 1 0
Soft trees (discussion) • Each split is defined by two parameters • Position a , and width b of transition region • Generalize decision/regression trees into a continuous and differentiable model w.r.t. the model parameters • Test nodes : aj , bj • Terminal nodes : ni • Other names (of similar models) • Fuzzy trees, continuous trees • Tree structured (neural, bayesian) networks • Hierarchical models
Soft trees (Motivations) • Improve performance (w.r.t. crisp trees) • Use of a larger hypothesis space • Reduced variance and bias • Improved optimization (à la backprop) • Improve interpretability • More « honest » model • Reduced parameter variance • Reduced complexity
D. Plan of the presentation • Bias/Variance tradeoff (in tree induction) • Main techniques to reduce variance • Why soft trees have lower variance • Techniques for learning soft trees
Concept of variance • Learning sample is random • Learned model is function of the sample • Model is also random : variance • Model predictions have variance • Model structure / parameters have variance • Variance reduces accuracy and interpretability • Variance can be reduced by various ‘averaging or smoothing’ techniques
Theoretical explanation • Bias, variance and residual error • Residual error • Difference between output variable and the best possible model (i.e. error of the Bayes model) • Bias • Difference between the best possible model and the average model produced by algorithm • Variance • Average variability of model around average model • Expected error2 : res2+bias2+var • NB: these notions depend on the ‘metric’ used for measuring error
p(y|x) y Regression (locally, at point x) Find y’=f(x) such that Ey|x{err(y,y’)} is minimum, where err is an error measure. Usually, err = squared error = (y- y’)2 • f(x)=Ey|x{y} minimizes the error at every point x • Bayes model is the conditional expectation
Learning algorithm (1) Usually, p(y|x) is unknown • Use LS = ((x1,y1),…,(xN,yN)), and a learning algorithm to choose hypothesis in H • ŷLS(x)=f(LS,x) • At each input point x, the prediction ŷLS(x) is a random variable • Distribution of ŷLS(x) depends on sample size N and on the learning algorithm used
Learning algorithm (2) pLS (ŷ(x)) ŷ Since LS is randomly drawn, estimation ŷ(x) is a random variable
Good learning algorithm • A good learning algorithm should minimize the average (generalization) error over all learning sets • In regression, the usual error is the mean squared error. So we want to minimize (at each point x) Err(x)=ELS{Ey|x{(y-ŷLS(x))2}} • There exists a useful additive decomposition of this error into three (positive) terms
Bias/variance decomposition (1) vary|x{y} y Ey|x{y} Err(x)= Ey|x{(y- Ey|x{y})2} + … Ey|x{y} = arg miny’Ey|x{(y- y’)2}} =Bayes model vary|x{y} = residual error = minimal error
ELS{ŷ(x)} Bias/variance decomposition (2) bias2(x) ŷ Ey|x{y} Err(x) = vary|x{y} + (Ey|x{y}-ELS{ŷ(x)})2 + … ELS{ŷ(x)} = average model (w.r.t. LS) bias2(x) = error between Bayes and average model
ELS{ŷ} Bias/variance decomposition (3) varLS{ŷ} ŷ Err(x)= vary|x{y} + bias2(x) + ELS{(ŷ(x)-ELS{ŷ(x)})2} varLS{ŷ(x)} = variance
bias2(x) ŷ Ey|x{y} ELS{ŷ(x)} Bias/variance decomposition (4) vary|x{y} varLS{ŷ(x)} Local error decomposition Err(x) = vary|x{y} + bias2(x) + varLS{ŷ(x)} Global error decomposition (take average w.r.t. p(x)) EX{Err(x)} = EX{vary|x{y}} + EX{bias2(x)}+ EX{varLS{ŷ(x)}}
Problem definition: One input x, uniform random variable in [0,1] y=h(x)+ε where εN(0,1) Illustration (1) h(x)=Ey|x{y} x
ELS{ŷ(x)} Illustration (2) • Small variance, high bias method
ELS{ŷ(x)} Illustration (3) • Small bias, high variance method
Illustration (Methods comparison) • Artificial problem with 10 inputs, all uniform random variables in [0,1] • The true function depends only on 5 inputs: y(x)=10.sin(π.x1.x2)+20.(x3-0.5)2+10.x4+5.x5+ε, where ε is a N(0,1) random variable • Experimentation: • ELSaverage over 50 learning sets of size 500 • Ex,yaverage over 2000 cases • Estimate variance and bias (+ residual error)
Illustration (Linear regression) • Veryfew parameters : small variance • Goal function is not linear : high bias
Illustration (k-Nearest Neighbors) • Small k : high variance and moderate bias • High k : smaller variance but higher bias
Illustration (Multilayer Perceptrons) • Small bias • Variance increases with the model complexity
Illustration (Regression trees) • Small bias, a (complex enough) tree can approximate any non linear function • High variance (see later)
Variance reduction techniques • In the context of a given method: • Adapt the learning algorithm to find the best trade-off between bias and variance. • Not a panacea but the least we can do. • Example: pruning, weight decay. • Wrapper techniques: • Change the bias/variance trade-off. • Universal but destroys some features of the initial method. • Example: bagging.
Variance reduction: 1 model (1) • General idea: reduce the ability of the learning algorithm to over-fit the LS • Pruning • reduces the model complexity explicitly • Early stopping • reduces the amount of search • Regularization • reduce the size of hypothesis space
Variance reduction: 1 model (2) Optimal fitting E=bias2+var var bias2 Fitting • Bias2 error on the learning set, E error on an independent test set • Selection of the optimal level of tuning • a priori (not optimal) • by cross-validation (less efficient)
As expected, reduces variance and increases bias Examples: Post-pruning of regression trees Early stopping of MLP by cross-validation Variance reduction: 1 model (3)
Variance reduction: bagging (1) • Idea: the average model ELS{ŷ(x)} has the same bias as the original method but zero variance • Bagging (Bootstrap AGGregatING): • To compute ELS{ŷ(x)}, we should draw an infinite number of LS(of size N) • Since we have only one single LS, we simulate sampling from nature by bootstrap sampling from the given LS • Bootstrap sampling = sampling with replacement of N objects from LS (N is the size of LS)
LS1 LS2 LSk x ŷ1(x) ŷ2(x) ŷk(x) ŷ(x) = 1/k.(ŷ1(x)+ŷ2(x)+…+ŷk(x)) Variance reduction: bagging (2) LS
Application to regression trees Strong variance reduction without increasing bias (although the model is much more complex than a single tree) Variance reduction: bagging (3)
Instead of perturbing learning sets to obtain several predictions, directly perturb the test case at the prediction stage Given a model ŷ(.) and a test case x: Form k attribute vectors by adding Gaussian noise to x: {x+ε1, x+ε2, …, x+εk}. Average the predictions of the model at these points to get the prediction at point x: 1/k.(ŷ(x+ε1)+ŷ(x+ε2)+…+ŷ(x+εk) Noise level λ(variance of Gaussian noise) selected by cross-validation Dual bagging (1)
With regression trees: Smooth the function ŷ(.). Too much noise increases bias there is a (new) trade-off between bias and variance Dual bagging (2)
Dual bagging (classification trees) λ = 1.5 error =4.6 % λ = 0.3 error =1.4 % λ = 0 error =3.7 %
Variance in tree induction • Tree induction is among the ML methods of highest variance (together with 1-NN) • Main reason • Generalization is local • Depends on small parts of the learning set • Sources of variance: • Discretization of numerical attributes (60 %) • The selected thresholds have a high variance • Structure choice (10 %) • Sometimes, attribute scores are very close • Estimation at leaf nodes (30 %) • Because of the recursive partitioning, prediction at leaf nodes is based on very small samples of objects • Consequences: • Questionable interpretability and higher error rates
Threshold variance (1) • Test on numerical attributes : [a(o)<ath] • Discretization: find ath which minimizes score • Classification: maximize information • Regression: minimize residual variance Score a(o) ath
Tree variance • DT/RT are among the machine learning methods which present the highest variance
DT variance reduction • Pruning: • Necessary to select the right complexity • Decreases variance butincreases bias : small effect on accuracy • Threshold stabilization: • Smoothing of score curves, bootstrap sampling… • Reduces parameter variance but has only a slight effect on accuracy and prediction variance • Bagging: • Very efficient at reducing variance • But jeopardizes interpretability of trees and computational efficiency • Dual bagging: • In terms of variance reduction, similar to bagging • Much faster and can be simulated by soft trees • Fuzzy tree induction • Build soft trees in a full fledged approach
Dual tree bagging = Soft trees • Reformulation of dual bagging as an explicit soft tree propagation algorithm • Algorithms • Forward-backward propagation in soft trees • Softening of thresholds during learning stage • Some results
Dual bagging = soft thresholds • x+ε<xth sometimes left, sometimes right • Multiple ‘crisp’ propagations can be ‘replaced’ by one ‘soft’ propagation • E.g. if ε has uniform pdf in [ath- l/2,ath+ l/2] then probability of right propagation is as follows l TSleft TSright ath
Forward-backward algorithm Top-down propagation of probability Root P(Root|x)=1 P(N1|x) = P(Test1|x) P(Root|x) Test1 N1 L3 P(L3|x) = P(Test1|x)P(Root|x) Test2 L1 L2 Bottom-up aggregation of predictions P(L1|x) = P(Test2|x)P(N1|x) P(L2|x) = P(Test2|x)P(N1|x)