Download
1 / 1
20 likes | 311 Views
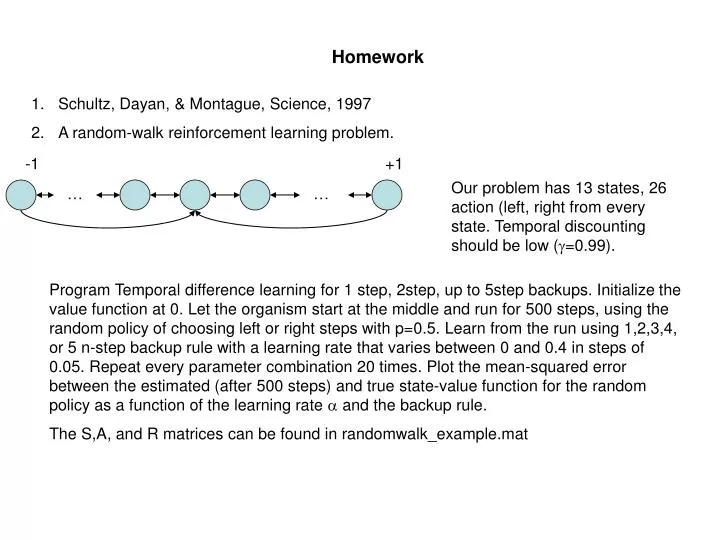
Homework. Schultz, Dayan, & Montague, Science, 1997 A random-walk reinforcement learning problem. -1. +1. Our problem has 13 states, 26 action (left, right from every state. Temporal discounting should be low ( g =0.99). …. ….

E N D
Homework • Schultz, Dayan, & Montague, Science, 1997 • A random-walk reinforcement learning problem. -1 +1 Our problem has 13 states, 26 action (left, right from every state. Temporal discounting should be low (g=0.99). … … Program Temporal difference learning for 1 step, 2step, up to 5step backups. Initialize the value function at 0. Let the organism start at the middle and run for 500 steps, using the random policy of choosing left or right steps with p=0.5. Learn from the run using 1,2,3,4, or 5 n-step backup rule with a learning rate that varies between 0 and 0.4 in steps of 0.05. Repeat every parameter combination 20 times. Plot the mean-squared error between the estimated (after 500 steps) and true state-value function for the random policy as a function of the learning rate a and the backup rule. The S,A, and R matrices can be found in randomwalk_example.mat





















