Download

1 / 14
140 likes | 299 Views
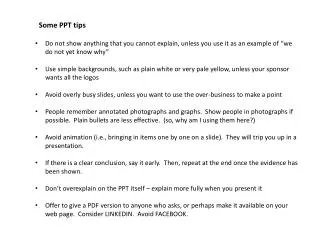
Some string optimization tips. Haiyang Yu. Outline. Background Tips for dealing with strings. Background. Find all pairs from two set which are similar. Data Cleaning. Query Relaxation Spellchecking. “PO BOX 23, Main St.” “P.O. Box 23, Main St”. “imformation”. “information”.

E N D
Some string optimization tips Haiyang Yu
Outline • Background • Tips for dealing with strings http://datamining.xmu.edu.cn
Background • Find all pairs from two set which are similar. • Data Cleaning. • Query Relaxation • Spellchecking “PO BOX 23, Main St.” “P.O. Box 23, Main St” “imformation” “information” http://datamining.xmu.edu.cn
Background • Find similar pairs • We have two string sets ,one is {vldb,sigmod,….} ,the other is {pvldb,icde,…}. • Find some candidate pairs , and then verify these pairs. {<vldb,pvldb>,<vldb,icde>,<vldb,..>,<sigmod,pvldb>,<sigmod,icde>,….} <vldb,pvldb> Yes <vldb,icde> No http://datamining.xmu.edu.cn
Optimization tips • Do whatever you can do to improve your algorithm’s time performance. • Some tips seem simple but they are important. http://datamining.xmu.edu.cn
Optimization tips • Inverted index • Suppose we have some strings • Inverted index http://datamining.xmu.edu.cn
Optimization tips • How to get “kau”? • Sub3_1 = S3. subString(0,3),then map it to S3,so we now have a map Sub3_1 -> 3 • Record the position information and calculate the hash code, then calculate the hash code Hash(“kau”) = ((((‘k’*131+’a’)*131+’u’)*…) It’s too expensive. http://datamining.xmu.edu.cn
Optimization tips • Length information • When we are dealing with s3 = “kaushic chaduri” , we split it to several segments which’s length are |s3|/(tau+1) or |s3|/(tau+1) +1. Then we get the substring {“kau”,”shic”,”_cha”,”duri”} http://datamining.xmu.edu.cn
Optimization tips • Length information • So will we calculate |Si|/(tau+1) every time we use it ? No, even though it seems not that expensive , but we must do our best to improve time performance if RAM allowed. • We store the position information. • Let L[length][partI] store the information . L[15][0].start = 0, L[15][0].length =3 … http://datamining.xmu.edu.cn
Optimization tips • Repetitive sequence • Some algorithm split string into repetitive sequence. For example , Q-Grams split S = “kaushic ” into {“kaush”,”aushi”,”ushic”}. • So if you use function substring, you have to load RAM three times to get the substring. But if you use the position information and hash code, you can just load it once. http://datamining.xmu.edu.cn
Optimization tips • Repetitive sequence • So we calculate Hash(“kaush”) = ((((‘k’*131+’a’)*131+’u’)*…) • When we calculate next hash code Hash(”aushi”),we needn’t recalculate Hash(“aush”) cause we have calculated it before, so Hash(”aushi”) = (Hash(“kaush”) - 131^4)*131 + ‘i’ http://datamining.xmu.edu.cn
Optimization tips • Sometimes you have done whatever you can to improve your code, but you still cannot beat the origin code which was written by author. Why? Maybe you need watch the experiment part, for example http://datamining.xmu.edu.cn
Optimization tips • What does the “-O3 flag” mean” • It’s the optimizing strategy for compiler. They have O0 -->> O1 -->> O2 -->> O3 which O3 is the highest optimizing level. http://datamining.xmu.edu.cn
Email: yhycai@gmail.com Thanks for patience http://datamining.xmu.edu.cn