Download
1 / 1
10 likes | 116 Views
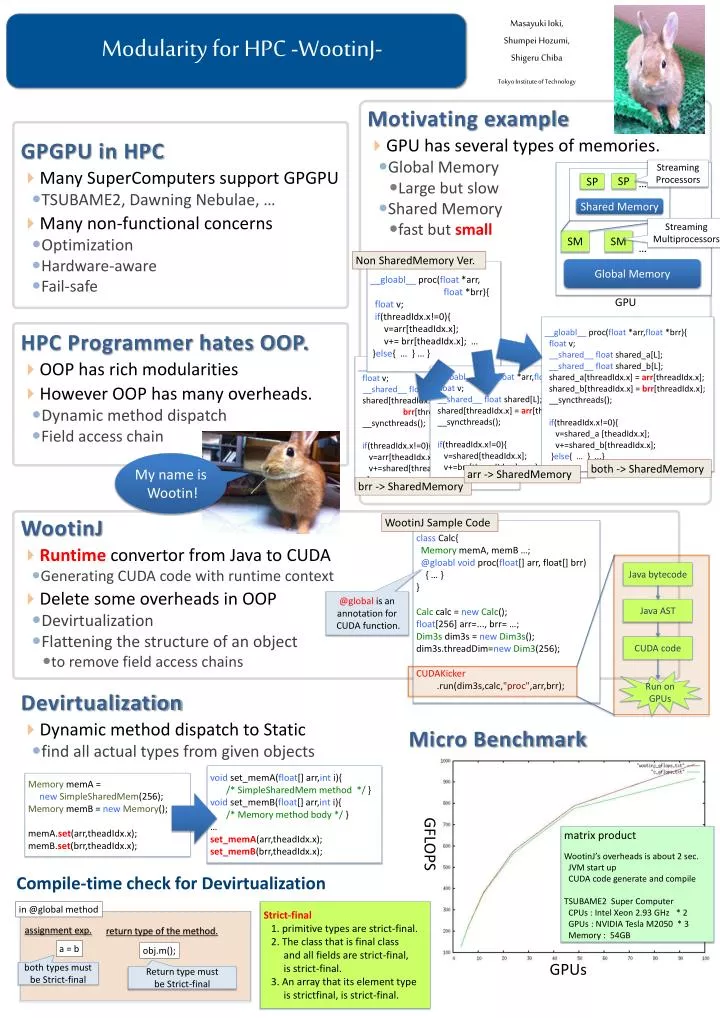
Modularity for HPC - WootinJ -. HPC Programmer hates OOP. OOP has rich modularities However OOP has many overheads. Dynamic method dispatch Field access chain. Micro Benchmark. M otivating example GPU has several types of memories. Global Memory Large but slow Shared Memory

E N D
Modularity for HPC -WootinJ- HPC Programmer hates OOP. • OOPhas rich modularities • However OOP has many overheads. • Dynamic method dispatch • Field access chain Micro Benchmark Motivating example • GPU has several types of memories. • Global Memory • Large but slow • Shared Memory • fast but small Devirtualization • Dynamic method dispatch to Static • find all actual types from given objects Masayuki Ioki, ShumpeiHozumi, Shigeru Chiba Tokyo Institute of Technology GPGPU in HPC • Many SuperComputers support GPGPU • TSUBAME2, Dawning Nebulae, … • Many non-functional concerns • Optimization • Hardware-aware • Fail-safe WootinJ • Runtime convertor from Java to CUDA • Generating CUDA code with runtime context • Delete some overheads in OOP • Devirtualization • Flattening the structure of an object • to remove field access chains Streaming Processors SP SP … Shared Memory Streaming Multiprocessors SM SM … Non SharedMemory Ver. __gloabl__proc(float *arr, float *brr){ float v; if(threadIdx.x!=0){ v=arr[theadIdx.x]; v+= brr[theadIdx.x]; … }else{ … } … } Global Memory GPU __gloabl__proc(float *arr,float*brr){ float v; __shared__ float shared_a[L]; __shared__ float shared_b[L]; shared_a[threadIdx.x] = arr[threadIdx.x]; shared_b[threadIdx.x] = brr[threadIdx.x]; __syncthreads(); if(threadIdx.x!=0){ v=shared_a [theadIdx.x]; v+=shared_b[threadIdx.x]; }else{ … } ...} __gloabl__proc(float *arr,float*brr){ float v; __shared__ float shared[L]; shared[threadIdx.x] = brr[threadIdx.x]; __syncthreads(); if(threadIdx.x!=0){ v=arr[theadIdx.x]; v+=shared[threadIdx.x]; …}else{ … } … } __gloabl__proc(float *arr,float*brr){ float v; __shared__ float shared[L]; shared[threadIdx.x] = arr[threadIdx.x]; __syncthreads(); if(threadIdx.x!=0){ v=shared[theadIdx.x]; v+=brr[threadIdx.x]; …}else{ … } … } My name is Wootin! both -> SharedMemory arr -> SharedMemory brr -> SharedMemory WootinJ Sample Code • classCalc{ • MemorymemA, memB …; • @gloabl void proc(float[] arr, float[] brr) • { … } • } • Calccalc = newCalc(); • float[256] arr=..., brr= …; • Dim3s dim3s = newDim3s(); • dim3s.threadDim=newDim3(256); • CUDAKicker • .run(dim3s,calc,"proc",arr,brr); Java bytecode @global is an annotation for CUDA function. Java AST CUDA code Run on GPUs • voidset_memA(float[] arr,inti){ • /* SimpleSharedMem method */ } • voidset_memB(float[] arr,inti){ • /* Memory method body */ } • … • set_memA(arr,theadIdx.x); • set_memB(brr,theadIdx.x); • MemorymemA = • newSimpleSharedMem(256); • MemorymemB = newMemory(); • memA.set(arr,theadIdx.x); • memB.set(brr,theadIdx.x); matrix product WootinJ’s overheads is about 2 sec. JVM start up CUDA code generate and compile TSUBAME2 Super Computer CPUs : Intel Xeon 2.93 GHz * 2 GPUs : NVIDIA Tesla M2050 * 3 Memory : 54GB GFLOPS Compile-time check for Devirtualization in @global method Strict-final 1. primitive types are strict-final. 2. The class that is final class and all fields are strict-final, is strict-final. 3. An array that its element type is strictfinal, is strict-final. assignment exp. return type of the method. a = b obj.m(); GPUs both types must be Strict-final Return type must be Strict-final