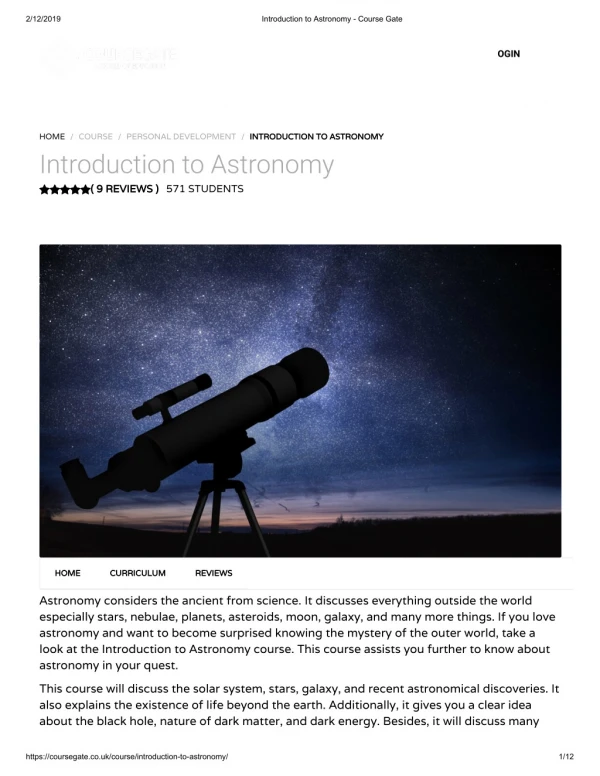
Download

1 / 34
340 likes | 466 Views
An Introduction to GATE. Presented by Lin Lin. What is GATE?. Stands for G eneral A rchitecture for T ext E ngineering. The theory behind GATE is SALE (Software Architecture for Language Engineering): computer processing of human language

E N D
An Introduction to GATE Presented by Lin Lin
What is GATE? • Stands for General Architecture for Text Engineering. • The theory behind GATE is SALE (Software Architecture for Language Engineering): • computer processing of human language • computer infrastructure for software development
Who Use GATE? • Scientists performing experiments that involve processing human language • Developers developing applications with language processing components • Teachers and students of courses about language and language computation
How GATE can Help? • Specify an architecture, or organizational structure, for language processing software • Provide a framework, or class library, that implements the architecture and can be used to embed language processing capabilities in diverse applications • Provide a development environment built on top of the framework made up of convenient graphical tools for developing components
What are GATE Components? • Reusable software chunks with well defined interfaces • Used in Java beans and Microsoft’s .Net
GATE as an architecture • Breaks down to three types of components: • LanguageResources (LRs) • represent entities such as lexicons, corpora, or ontologies; • ProcessingResources (PRs) • represent entities that are primarily algorithmic, such as parsers, generators or ngram modelers; • VisualResources (VRs) • represent visualization and editing components that participate in GUIs.
LRs: Corpora, Documents, and Annotations • A Corpus in Gate is a Java Set whose members are Documents. • Documents are modeled as content plus annotations plus features. • Annotations are organized in graphs, which are modeled as Java sets of Annotation.
Documents Processing in GATE • Document: • Formats including XML, RTF, email, HTML, SGML, and plain text. • Identified and converted into GATE annotation format. • Processed by PRs. • Results stored in a serial data store (based on Java serialization) or as XML.
Built-in GATE Components • Resources for common LE data structures and algorithms, including documents, corpora and various annotation types • A set of language analysis components for Information Extraction (e.g. ANNIE) • A range of data visualization and editing components
Develop Language Processing Functionality using GATE • Programming, or the development of Language Resources such as grammars that are used by existing Processing Resources, or a mixture of both. • The development environment is used for: • visualization of the data structures produced and consumed during processing • debugging • performance measurement
CREOLE • A Collection of REusable Objects for Language Engineering • The set of resources integrated with GATE • All the resources are packaged as Java Archive (or ‘JAR’) files, plus some XML configuration data.
PRs: ANNIE • A family of Processing Resources for language analysis included with GATE • Stands for ANearly-New Information Extraction system. • Using finite state techniques to implement various tasks: tokenization, semantic tagging, verb phrase chunking, and so on.
ANNIE Components • Tokenizer • Gazetteer • Sentence Splitter • Part of Speech Tagger • produces a part-of-speech tag as an annotation on each word or symbol. • Semantic Tagger • OrthoMatcher Coreference Module
ANNIE Component: Tokenizer • Token Types • word, number, symbol, punctuation, and spaceToken. • A tokenizer rule has a left hand side and a right hand side.
Tokenizer Rule • Operations used on the LHS: • | (or) • * (0 or more occurrences) • ? (0 or 1 occurrences) • + (1 or more occurrences) • The RHS uses ’;’ as a separator, and has the following format: {LHS} > {Annotation type};{attribute1}={value1};...;{attribute n}={value n}
Example Tokenizer Rule • "UPPERCASE_LETTER" "LOWERCASE_LETTER"* > Token;orth=upperInitial;kind=word; • The sequence must begin with an uppercase letter, followed by zero or more lowercase letters. This sequence will then be annotated as type “Token”. The attribute “orth” (orthography) has the value “upperInitial”; the attribute “kind” has the value “word”.
ANNIE Component: Gazetteer • The gazetteer lists used are plain text files, with one entry per line. • Each list represents a set of names, such as names of cities, organizations, days of the week, etc.
Example Gazetteer List • A small section of the list for units of currency: • …… Ecu European Currency Units FFr Fr German mark German marks New Taiwan dollar New Taiwan dollars NT dollar NT dollars ……
ANNIE Component: Semantic Tagger • Based on JAPE language, which contains rules that act on annotations assigned in earlier phases. • Produce outputs of annotated entities.
ANNIE Component: Sentence Splitter • Segments the text into sentences. • This module is required for the tagger. • The splitter uses a gazetteer list of abbreviations to help distinguish sentence-marking full stops from other kinds.
ANNIE Component: OrthoMatcher • Adds identity relations between named entities found by the semantic tagger, in order to perform coreference. • Does not find new named entities, but it may assign a type to an unclassified proper name.
Create a New Resource • Write a Java class that implements GATE’s beans model. • Compile the class, and any others that it uses, into a Java Archive (JAR) file. • Write some XML configuration data for the new resource. • Tell GATE the URL of the new JAR and XML files.
Example: Create a New Component Called GoldFish • GoldFish: • Is a processing resource • Look for all instances of the word “fish” in the document • Add an annotation of type “GoldFish”
GoldFish: default files created • The default Java code created for the GoldFish resource looks like: • GoldFish.java • The default XML configuration for GoldFish looks like: • resource.xml
Create an Application with PRs • Applications model a control strategy for the execution of PRs. • Currently only pipeline execution is supported. • Simple pipelines: group a set of PRs together in order and execute them in turn. • Corpus pipelines: open each document in the corpus in turn, set that document as a runtime parameter on each PR, run all the PRs on the corpus, then close the document
Additional Facilities • JAPE • a Java Annotation Patterns Engine, provides regular-expression based pattern/action rules over annotations. • The file “Main.jape” contains a list of the grammars to be used for for Named Entity Recognition, in the correct processing order. • Used in ANNIE.
Additional Facilities • The ‘annotation diff’ tool in the development environment • implements performance metrics such as precision and recall for comparing annotations. • GUK (the GATE Unicode Kit) • fills in some of the gaps in the JDK’s support for Unicode.
Embedding ANNIE • Create a stand alone ANNIE extraction system. • Example code that will embed ANNIE in an application that takes URLs as inputs and produces named entities as outputs.
Additional Features • Add support for a new document format • Create a new annotation schema • Write your own algorithm to dump results to file • Work with Unicode • Work with Oracle and PostgreSQL
Other VR can be Used in GATE • Ontogazetteer • makes ontologies “visible” in GATE. • Protégé • makes use of developed Protégé ontologies in GATE, and also take advantage of being able to read different format ontology files in Protégé.
Link to GATE web page • http://gate.ac.uk • Documentation and download
GATE Demo • GATE graphical development environment • Do information extraction with ANNIE • Create and run an application • .....