Download
1 / 1
20 likes | 245 Views
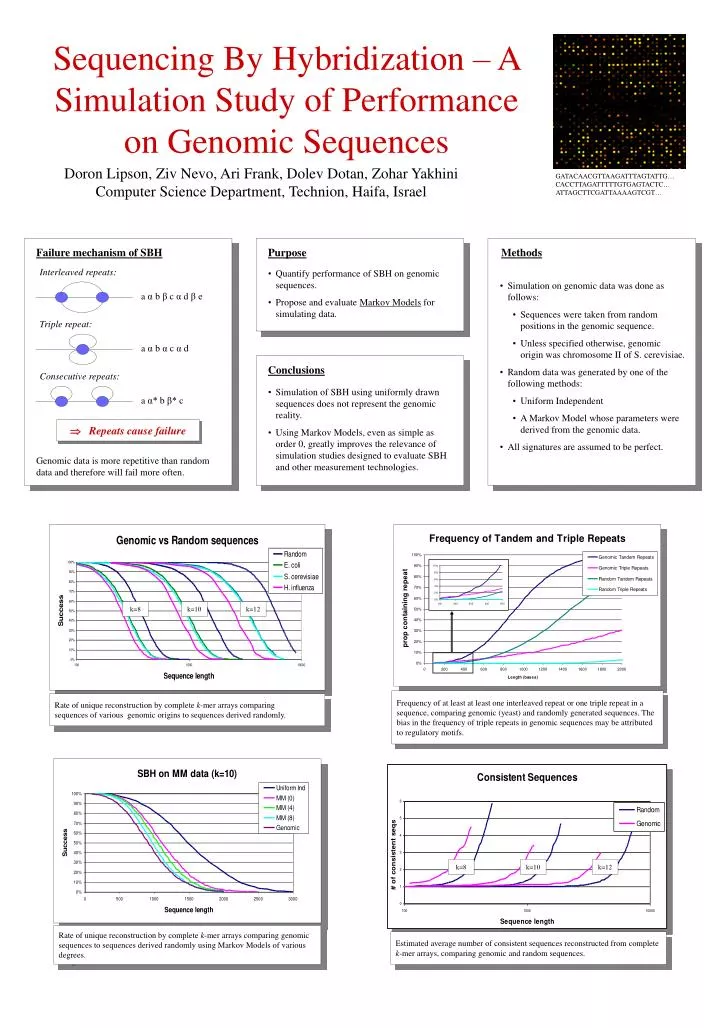
Failure mechanism of SBH. Methods. Interleaved repeats:. Simulation on genomic data was done as follows: Sequences were taken from random positions in the genomic sequence. Unless specified otherwise, genomic origin was chromosome II of S. cerevisiae.

E N D
Failure mechanism of SBH Methods Interleaved repeats: • Simulation on genomic data was done as follows: • Sequences were taken from random positions in the genomic sequence. • Unless specified otherwise, genomic origin was chromosome II of S. cerevisiae. • Random data was generated by one of the following methods: • Uniform Independent • A Markov Model whose parameters were derived from the genomic data. • All signatures are assumed to be perfect. a α b β c α d β e Triple repeat: a α b α c α d Conclusions Purpose • Simulation of SBH using uniformly drawn sequences does not represent the genomic reality. • Using Markov Models, even as simple as order 0, greatly improves the relevance of simulation studies designed to evaluate SBH and other measurement technologies. • Quantify performance of SBH on genomic sequences. • Propose and evaluate Markov Models for simulating data. Consecutive repeats: Repeats cause failure a α* b β* c Genomic data is more repetitive than random data and therefore will fail more often. k=8 k=10 k=12 Frequency of at least at least one interleaved repeat or one triple repeat in a sequence, comparing genomic (yeast) and randomly generated sequences. The bias in the frequency of triple repeats in genomic sequences may be attributed to regulatory motifs. Rate of unique reconstruction by complete k-mer arrays comparing sequences of various genomic origins to sequences derived randomly. k=8 k=10 k=12 Rate of unique reconstruction by complete k-mer arrays comparing genomic sequences to sequences derived randomly using Markov Models of various degrees. Estimated average number of consistent sequences reconstructed from complete k-mer arrays, comparing genomic and random sequences. Sequencing By Hybridization – A Simulation Study of Performance on Genomic Sequences Doron Lipson, Ziv Nevo, Ari Frank, Dolev Dotan, Zohar Yakhini Computer Science Department, Technion, Haifa, Israel GATACAACGTTAAGATTTAGTATTG…CACCTTAGATTTTTGTGAGTACTC…ATTAGCTTCGATTAAAAGTCGT…