Download
1 / 1
10 likes | 211 Views
T-05-MU. 2012/07/27(Fri.). 畳み込み非負値行列因子分解を用いた 音声パターンの教師無し学習と音素分類 Unsupervised learning of speech patterns and phone classifi-cation using Convolutive Non-negative Matrix Factorization. M2 in Chikayama Lab. 37-106488 Wataru Hariya. Introduction

E N D
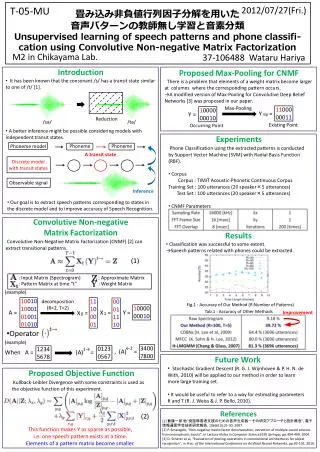
T-05-MU 2012/07/27(Fri.) 畳み込み非負値行列因子分解を用いた 音声パターンの教師無し学習と音素分類 Unsupervised learning of speech patterns and phone classifi-cation using Convolutive Non-negative Matrix Factorization M2 in ChikayamaLab. 37-106488 WataruHariya • Introduction • It has been known that the consonant /s/ has a transit state similar to one of /t/ [1]. Proposed Max-Pooling for CNMF There is a problem that elements of a weight matrix become larger at columns where the corresponding pattern occurs. →A modified version of Max-Pooling for Convolutive Deep Belief Networks [3]was proposed in our paper. Max-Pooling 11000 00011 10000 00010 Y = Y = mp Reduction /sa/ /ta/ Existing Point Occurring Point • A better inference might be possible considering models with independent transit states. • Experiments • Phone Classification using the extracted patterns is conducted by Support Vector Machine (SVM) with Radial Basis Function (RBF). • Corpus • Corpus : TIMIT Acoustic-Phonetic Continuous Corpus • Training Set : 100 utterances (20 speaker×5 utterances) • Test Set : 100 utterances (20 speaker×5 utterances) • CNMF Parameters Phoneme Phoneme Phoneme model Convolutive Non-negative MatrixFactorization Convolutive Non-Negative Matrix Factorization (CNMF) [2] can extract transitional patterns. A transit state Discrete model with transit states Observable signal Inference (1) • Our goal is to extract speech patterns corresponding to states in the discrete model and to improve accuracy of Speech Recognition. : Input Matrix(Spectrogram) : Approximate Matrix : Pattern Matrix at time “t” : Weight Matrix (example) • Results • Classification was successful to some extent. • →Speech patterns related with phones could be extracted. 10010 10001 01001 01010 11 10 00 01 00 01 11 10 decomposition (R=2, T=2) 10000 00010 A = X = Y = X = 1 0 • Operator (example) 3400 7800 0123 0567 1234 5678 ←2 1→ , (A) = When A = (A) = Proposed Objective Function Kullback-Leibler Divergence with some constraints is used as the objective function of this experiment. Fig.1 : Accuracy of Our Method (R:Number of Patterns) Tab.1 : Accuracy of Other Methods Improvement • Future Work • Stochastic Gradient Descent (R. G. J. Wijnhoven & P. H. N. de With, 2010) will be applied to our method in order to learn more large training set. • It would be useful to refer to a way for estimating parameters R and T (R. J. Weiss & J. P. Bello, 2010). This function makes Y as sparse as possible, i.e. one speech pattern exists at a time. Elements of a pattern matrix become smaller. (2) References [1] 藪謙一郎 他“発話障害者支援のための音声生成器-その研究アプローチと設計概念", 電子情報通信学会技術研究報告, 106(613):25-30, 2007. [2] P. Smaragdis, "Non-negative matrix factor deconvolution; extraction of multiple sound sources from monophonic inputs", in Lecture Notes in Computer Science3195 Springer, pp.494-499, 2004. [3] D. Scherer et al, "Evaluation of pooling operations in convolutional architectures for object recognition", in Proc. of the International Conference on Artificial Neural Networks, pp.92-101, 2010.
