Download

1 / 131
1.31k likes | 1.34k Views
Explore the evolutionary paths of proteins using codon bias and sequence comparisons to analyze relationships between species. This study delves into the molecular mechanisms of eukaryotes, prokaryotes, and unique genetic codes.

E N D
Molecular Evolution of Proteins and Phylogenetic AnalysisFred R. OpperdoesChristian de Duve Institute of Cellular Pathology (ICP) and Laboratory of Biochemistry, Université catholique de Louvain, Brussels, Belgium
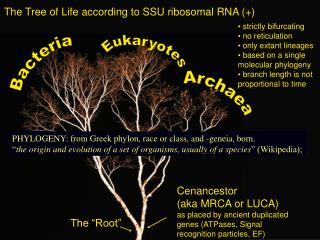
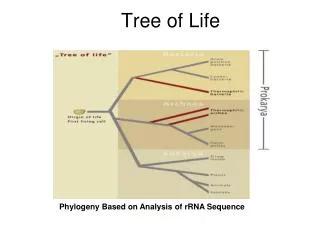
Eukaryota Algae Fungi Cilates Animals Plants Eubacteria Euglena Kinetoplastida Parabasalia Microsporidia Diplomonads Archaebacteria The ‘tree of life’ based on rRNA sequences Mitochondriates Amitochondriates
Eukaryota Algae Fungi Cilates Animals Plants Eubacteria Euglena Kinetoplastida Parabasalia Microsporidia Diplomonads Archaebacteria The fusion hypothesis: the eukaryotic cell is a chimaera of eubacterial and archaebacterial traits Energy metabolism Genetic machinery Root? Common ancestor?
Triosephosphate isomerase Triosephosphate isomerase of eukaryotes is of typical eubacterial origin and probably has entered the eukaryotic cell together with the bacterial endosymbiont that gave rise to the formation of the mitochondrion Root?
Arguments in favour of protein rather than the DNA sequences CODON BIAS : • 64 different possible triplet codes encode 20 amino acids. One amino acid may be encoded by 1 to 6 different triplet codes, and 3 of the 64 codes, called stop (or termination) codons, specify "end of peptide sequence" • The different codons are used with unequal frequency and this distribution of frequency is referred to as "codon usage" • Codon usage varies between species. Amino-acid codons have been degenerated with wobble in the third position.
The universal genetic code First Second Position Third Position ------------------------------------ Position | U(T) C A G | U(T) Phe Ser Tyr Cys U(T) Phe Ser Tyr Cys C Leu Ser STOP STOP A Leu Ser STOP Trp G C Leu Pro His Arg U(T) Leu Pro His Arg C Leu Pro Gln Arg A Leu Pro Gln Arg G A Ile Thr Asn Ser U(T) Ile Thr Asn Ser C Ile Thr Lys Arg A Met Thr Lys Arg G G Val Ala Asp Gly U(T) Val Ala Asp Gly C Val Ala Glu Gly A Val Ala Glu Gly G
Arguments in favour of ... (codon bias 2) • Yeasts, protozoa, and animals have different codon preferences, • This would result in differences in DNA sequence related to codon bias and not to evolution.
Different species use different codons Homo sapiens [gbmam]: 1 CDS's (389 codons) ---------------------------------------------------------------------------- fields: [triplet] [frequency: per thousand] ([number]) ---------------------------------------------------------------------------- UUU 20.6( 8) UCU 5.1( 2) UAU 7.7( 3) UGU 7.7( 3) UUC 12.9( 5) UCC 20.6( 8) UAC 30.8( 12) UGC 0.0( 0) UUA 10.3( 4) UCA 18.0( 7) UAA 0.0( 0) UGA 0.0( 0) UUG 10.3( 4) UCG 0.0( 0) UAG 2.6( 1) UGG 15.4( 6) Saccharomyces cerevisiae [gbpln]: 9295 CDS's (4586264 codons) ---------------------------------------------------------------------------- fields: [triplet] [frequency: per thousand] ([number]) ---------------------------------------------------------------------------- UUU 25.9(118900) UCU 23.6(108308) UAU 18.7( 85651) UGU 8.0( 36624) UUC 18.3( 83880) UCC 14.3( 65421) UAC 14.7( 67599) UGC 4.6( 21255) UUA 26.3(120698) UCA 18.7( 85618) UAA 1.0( 4476) UGA 0.6( 2742) UUG 27.2(124967) UCG 8.5( 39137) UAG 0.4( 2058) UGG 10.4( 47694)
Differences between the “Universal” and Mitochondrial Genetic Codes Codon Universal code mitochondrial code UGA Stop Trp AGA Arg Stop AGG Arg Stop (or Lys*) AUA Ile Met Modified from: Li and Graur, 1991, Fundamentals of Molecular Evolution , Sinauer Publ. * Only in arthropod mitochonria (Abascal et al., PLoS Biol 4, e127 (2006))
Arguments in favour... (codon bias) • Also, the protozoa use the codons UAA and UGA to encode glutamine, rather than STOP • The inclusion of unique codons in a subset of the sequences will tend to make that subset appear more divergent than they really are
Arguments in favour... (codon bias 2) • High GC content of DNA seems to be associated with aerobiosis in prokaryotes (Naya et al., 2002) • In all major groups both organisms with AT rich and GC rich DNA can be found. • The inclusion of unique codons in a subset of the sequences will tend to make that subset appear more divergent than they really are
GC content of DNA in aerobic and anaerobic prokaryotes Anaerobic Aerobic From Naya et al., J. Mol. Evol. 55 (2002) 260-264
The use of protein sequences in phylogeny requires knowledge of the properties of the amino acids and their single letter codes
The use of protein sequences in phylogeny requires knowledge of the properties of the amino acids and their single letter codes Alanine A Leucine L Arginine R Lysine K Asparagine N Methionine M Aspartic acid D Phenylalanine F Cysteine C Proline P Glutamic acid E Serine S Glutamine Q Threonine T Glycine G Tryptophane W Histidine H Tyrosine Y Isoleucine I Valine V
Arguments in favour of a phylogenetic analysis of the corresponding protein rather than the DNA LONG TIME HORIZON : When comparing sequences that have diverged for possibly a billion years or more, it is very likely that the wobble bases in the codons will have become randomized. By excluding the wobble bases (a general technique), one is actually looking at amino acid sequences.So why not taking a protein sequence directly?
Advantages of the translation of DNA into protein (1) • DNA is composed of only four kinds of unit: A, G, C and T • If gaps are not allowed, on the average, 25% of residues in two randomly chosen aligned sequences would be identical • If gaps are allowed, as much as 50 % of residues in two randomly chosen aligned sequences can be identical. Such a situation may obscure any genuine relationship that may exist. Especially when comparing distantly related or rapidly evolving gene sequences • Moreover, it is easier to translate a gene sequence into its corresponding protein than to remove the third wobble base from each of the codons in the gene • All open reading frames have alreday been translated in to their corresponding peptide sequences (GenPept and Uniprot databases)
Alignment of two random DNA sequences Without indels 19% identity Indels allowed 56%identity
Advantages of the translation of DNA into protein (2) • Translation of DNA into 21 different types of codon (20 amino acids and a terminator) allows the information to sharpen up considerably. Wrong frame information is set aside • Third-base degeneracies are consolidated • After insertion of gaps to align two random protein sequences it can be expected that they are between 10-20% identical • As a result of the translation procedure the protein sequences with their 20 amino acids are much more easy to align than the corresponding DNA sequences with only 4 nucleotides
Alignment of two random protein sequences Without indels 7% identity Indels allowed 22% identity
Advantages of the translation of DNA into protein (3) • If, after this, you still want to align distantly related gene sequences, you better prepare first a protein alignment and then base yourself on this alignment for the alignment of the gene sequences and the precise placement of indels in the aligned sequences (use EMBOSS’ tranalign). • Conclusion: The signal to noise ratio is greatly improved when using protein sequences over DNA sequences!
TBLASTX • The blast algorithm TBLASTX allows the use of translated nucleic acid sequence information to search for distant relationships between genes • A translated protein sequence is compared with all the translated sequences from a nucleotide database
Nature of Sequence Divergence in Proteins • The observed sequence difference of two diverging sequences takes the course of a negative exponential. This is the result of the fact that each position is subject to reverse changes ("back mutations") and multiple hits • Thus the observed percentage of difference between the protein sequences is not proportional to the actual evolutionary difference between two homologous sequences • The evolutionary distance between two proteins is expressed in PAM units. PAM (Dayhoff and Eck, 1968) stands for "accepted point mutation"
Relation between % distance and PAM distance PAM Distance value (%) 80 50 100 60 200 75 250 85 Twilight zone 300 92 (From Doolittle, 1987, Of URFs and ORFs, University Science Books) As the evolutionary distance increases, the probability of super-imposed mutations becomes greater resulting in a lower observed percent difference.
85 80 75 70 65 60 55 50 45 40 35 30 25 20 15 10 5 0 100 200 300 400 Relation between % distance and PAM distance Distance % Twilight zone Pam value
The Kimura correction for multiple substitutions • The formula used to correct for multiple hits is from Motoo Kimura (Kimura, M. The neutral Theory of Molecular Evolution, Camb.Univ.Press, 1983, page 75) : • K = -Ln(1 - D - (D.D)/5) where D is the observed distance and K is corrected distance. • This formula gives mean number of estimated substitutions per site and, in contrast to D (the observed number), can be greater than 1 i.e. more than one substitution per site, on average. For example, if you observe 0.8 differences per site (80% difference; 20% identity), then the above formula predicts that there have been 2.5 substitutions per site over the course of evolution since the 2 sequences diverged. • This can also be expressed in PAM units by multiplying by 100 (mean number of substitutions per 100 residues).
Proteins evolve at highly different rates Rate of Change Theoretical PAMs / 108 yrs Lookback Time Pseudogenes 400 45 x 106 yrs Fibrinopeptides 90 200 " Lactalbumins 27 670 " Lysozymes 24 850 " Ribonucleases 21 850 " Haemoglobins 12 1500 " Acid proteases 8 2300 " Cytochrome c 4 5000 " Glyceraldehyde-P dehydrogenase 2 9000 " Glutamate dehydrogenase 1 18000 " PAM = number of Accepted Point Mutations per 100 amino acids. Useful lookback time = 360 PAMs
Some Important Dates in History Event Number of years ago Origin of the Universe 15 ± 4 109 yrs Formation of the Solar System 4.6 " First Self-replicating System 3.5 ± 0.5 " Prokaryotic-Eukaryotic Divergence 2.0 ± 0.5 " Plant-Animal Divergence ~1.0 " Invertebrate-Vertebrate Divergence 0.5 " Mammalian Radiation Beginning ~ 0.1 " From Doolittle, Of URFs and ORFs, 1987
Construction of a phylogenetic tree from phosphoglycerate kinase sequences
Arguments in favour of a protein rather than a DNA sequence (3) INTRONS : • A study of the evolution of a protein using its DNA sequence should only include coding sequences • This requires that in every DNA sequence all the introns are being edited out. This may be cumbersome and time consuming • An easier approach would be the direct translation of the cDNA sequence into its corresponding protein sequence
Typical structure of a eukaryotic gene Exon 2 Flanking region Exon 1 Exon 3 Flanking region 3' 5' Intron II Intron I TATA Initiation Stop Poly (A) box codon codon addition site Transcription AATAA initiation
Arguments in favour of a protein rather than a DNA sequence (4) MULTIGENE FAMILIES : • Organisms may contain many highly similar genes, while only one peptide sequence can be identified (e.g. histones, tubulins and GAPDH in humans). • Using these DNA sequences, it would be difficult to decide which are expressed and which not and thus which genes to include in the analysis. • Moreover, if all the genes that are expressed encode the same protein, then DNA differences are not significant
Arguments in favour of a protein rather than a DNA sequence (5) PROTEIN IS THE UNIT OF SELECTION : • For protein-encoding genes, the object on which natural selection acts is the protein itself. • The underlying DNA sequence reflects this process in combination with species-specific pressures on DNA sequence (like the need for aerophiles to have DNA that is GC richer). • If function demands that a protein maintains a specific sequence, there still is room for the DNA sequence to change.
Arguments in favour of a protein rather than a DNA sequence (6) RNA EDITING : • The DNA sequence doesn't always translate into amino acid sequence. • In post-translational editing non-coded amino acids are added or coded amino acids are removed in the editing process. • This could lead to major differences in DNA sequence (sometimes more than 50%) that nevertheless leads to roughly the same protein sequence after final editing
Pan-editing of mitochondrial RNA in Kinetoplastida UCCuAuuA*AuUUUUUGuUA**UAu AGuuuuuuAA*UGUUGuuuGGuGuA *uuuuuuuAuUG*UGuuuAGuuuuG uuuuGuuGuuGuuuGuuuG****GU GuGuuAuuG**UUUUGAGAuuGuuG note that the mature mRNA would not be able to hybridise with the gene present in the kinetoplast DNA and thus cannot be detected as such.
Some good advice (1) • It is recommended to prepare the phylogenetic trees both ways (DNA and Protein) and see how they look • For a group of species that are relatively close in time and closely related (like viral proteins or vertebrate enzymes), DNA-based analysis is probably a good way to go, since you avoid problems of codon bias and randomization of wobble bases. But check the protein anyway
Some good advice (2) • Be aware of the problems of multigene families (for instance coding for isoenzymes) • Be careful when you decide to exclude or include such sequences (you may compare paralogous rather than orthologous sequences)
What is required • A DNA or protein sequence • A set of homologous sequences • A good multiple sequence alignment • Several programs to create a phylogenetic tree
What is required • A DNA or protein sequence • A set of homologous sequences • A good multiple sequence alignment • Several programs to create a phylogenetic tree
PAM 250 matrix as used in Clustal C 12, S 0, 2, T -2, 1, 3, P -3, 1, 0, 6, A -2, 1, 1, 1, 2, G -3, 1, 0,-1, 1, 5, N -4, 1, 0,-1, 0, 0, 2, D -5, 0, 0,-1, 0, 1, 2, 4, E -5, 0, 0,-1, 0, 0, 1, 3, 4, Q -5,-1,-1, 0, 0,-1, 1, 2, 2, 4, H -3,-1,-1, 0,-1,-2, 2, 1, 1, 3, 6, R -4, 0,-1, 0,-2,-3, 0,-1,-1, 1, 2, 6, K -5, 0, 0,-1,-1,-2, 1, 0, 0, 1, 0, 3, 5, M -5,-2,-1,-2,-1,-3,-2,-3,-2,-1,-2, 0, 0, 6, I -2,-1, 0,-2,-1,-3,-2,-2,-2,-2,-2,-2,-2, 2, 5, L -6,-3,-2,-3,-2,-4,-3,-4,-3,-2,-2,-3,-3, 4, 2, 6, V -2,-1, 0,-1, 0,-1,-2,-2,-2,-2,-2,-2,-2, 2, 4, 2, 4, F -4,-3,-3,-5,-4,-5,-4,-6,-5,-5,-2,-4,-5, 0, 1, 2,-1, 9, Y 0,-3,-3,-5,-3,-5,-2,-4,-4,-4, 0,-4,-4,-2,-1,-1,-2, 7,10, W -8,-2,-5,-6,-6,-7,-4,-7,-7,-5,-3, 2,-3,-4,-5,-2,-6, 0, 0,17, C S T P A G N D E Q H R K M I L V F Y W
ClustalX distance matrix Non-corrected AROC_LEIMJ 0.000 0.036 0.268 0.268 0.232 AROC_PSEAE 0.036 0.000 0.268 0.268 0.232 AROC_VIBCH 0.268 0.268 0.000 0.089 0.232 AROC_VIBAN 0.268 0.268 0.089 0.000 0.232 AROC_NEIMB 0.232 0.232 0.232 0.232 0.000 Corrected for multiple substitution AROC_LEIMJ 0.000 0.037 0.332 0.332 0.278 AROC_PSEAE 0.037 0.000 0.332 0.332 0.278 AROC_VIBCH 0.332 0.332 0.000 0.095 0.278 AROC_VIBAN 0.332 0.332 0.095 0.000 0.278 AROC_NEIMB 0.278 0.278 0.278 0.278 0.000
Matrices often used for the alignment of proteins • PAM 350 (Dayhoff et al., 1978) • BLOSUM30 (Henikoff-Henikoff, 1992) • JTT (Jones et al., 1992) • mtREV24 (Adachi-Hasegawa, 1996) • GONNET 250 matrix (Gonnet et al., 1992)
Alignment of two protein sequences (1) • For the creation of a phylogenetic tree a good alignment of protein sequences is of vital importance • Only homologous residues should be aligned with each other • Doubtful regions should not be included in the alignment • Aligned sequences should have similar lengths
Alignment of two protein sequences • Alignment requires the user to make assumptions regarding relative costs of substitution versus insertions and deletions (indels). • If substitution cost >> gap penalty: there will be many short gaps and no phylogenetic information. • In general: search for maximum similarity and minimize the number of insertions and deletions. • Exclude regions that cannot be aligned unambiguously!