Download
1 / 32
330 likes | 731 Views
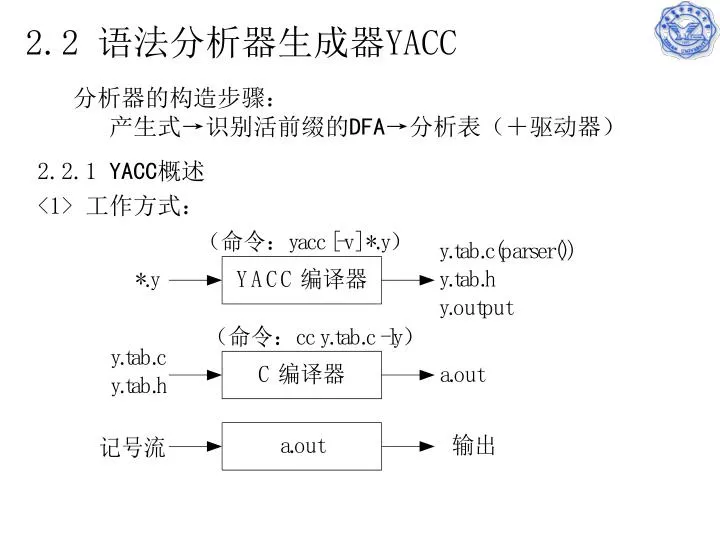
2.2 语法分析器生成器 YACC. 分析器的构造步骤: 产生式→识别活前缀的 DFA → 分析表(+驱动器). 2.2.1 YACC 概述 <1> 工作方式:. ( 1 )声明与定义 ( 2 )分析表 ( 3 )分析表的驱动器( parser() ) ( 4 )用户定义子程序. 2 . YACC 生成的语法分析器框架. 2.2.1 YACC 概述. 利用 YACC 进行语法分析器设计的关键,也是如何编写 YACC 源程序。

E N D
2.2 语法分析器生成器YACC 分析器的构造步骤: 产生式→识别活前缀的DFA→分析表(+驱动器) 2.2.1 YACC概述 <1> 工作方式:
(1)声明与定义 (2)分析表 (3)分析表的驱动器(parser()) (4)用户定义子程序 2.YACC生成的语法分析器框架 2.2.1 YACC概述 利用YACC进行语法分析器设计的关键,也是如何编写YACC源程序。 下边首先介绍YACC源程序的基本结构,然后着重讨论YACC的产生式、YACC解决产生式冲突的方法、以及YACC对语义的支持和对错误的处理等。 2.2.2 YACC源程序的基本结构 [声明(declarations)] %% 翻译规则(translation rules) [%% 用户定义子程序(user defined routines)] 与LEX的区别: 至少一条翻译规则
例2.10简单的YACC源程序。 2.2.2 YACC源程序的基本结构(续1) %% int yylex() { int c; while ((c=getchar())==' '); if (isdigit(c)) { ungetc(c, stdin); scanf(yytext,"%d";$yylval); return num; } return c} main(){ parser(); } %{ #include <ctype.h> #include <stdio.h> %} %token num %left '-' %left '*' %% LS :LS E '\n' { printf("%d\n",$2);} | E '\n' { printf("%d\n",$1);} ; E :E '-' E { $$=$1-$3;} | E '*' E { $$=$1*$3;} | num ; 用户编写的词法分析器应与LEX产生的词法分析器有相同的界面,以供语法分析器使用,它们包括:yylex()、yylval、yytext和yyleng等。
2.2.2.1 声明 • <1> C语言部分 "%{" ...... "%}" • <2> Yacc的说明部分 目的是为翻译规则服务。 • 文法的开始符号: • %start n_name (默认第一个产生式的左部是开始符号) • 终结符: • 直接表示:'-'和'*'等; (无需说明) • 名字: %token t_name(内部编码,LEX中使用) • 说明终结符的优先级与结合性:(非终结符下节讨论) • 结合性: • 左结合-%left • 右结合-%right • 无结合性-%nonassoc • 优先级:从上到下依次递增 • %left '+' '-' • %left '*' '/' • 重新定义语义栈类型(下节讨论)。
2.2.2.2 用户定义子程序 • 这部分与LEX的第三部分作用相同,所有语义动作中的C源程序均可定义在此。如例2.10中的yylex(),若采用LEX生成yylex(),则可编写LEX源程序如下: • %% • [ \n\t]; • [0-9]+ { scanf(yytext,"%d",&yylval); return NUMBER;} • . { return yytext[0];} • 而例2.10中yylex()的定义相应改为#include "lex.yy.c"即可。
2.2.2.3 翻译规则 规则 → 非终结符 ‘:’候选项集 ‘;’ 候选项集 → ε | 候选项 | 候选项集 ‘|’候选项 候选项 → 文法符号序列 右部语义动作 文法符号序列 → ε | 文法符号序列 文法符号 文法符号 → 终结符 | 非终结符 | 嵌入语义动作 右部语义动作 → ε |‘{’C语言语句序列‘}’ 嵌入语义动作 →‘{’C语言语句序列‘}’ E :E '-' E { $$=$1-$3;} | E '*' E { $$=$1*$3;} | num ;
2.2.3.1 YACC解决冲突的方法(二义文法时产生的冲突) 2.2.3 YACC程序设计 • 分析表中的两类冲突 • 移进/归约冲突:在一个状态中,面对相同的下一文法符号,可以同时有移进和归约两个动作与其匹配; • 归约/归约冲突:在一个状态中,面对相同的下一文法符号,有两个或两个以上的产生式可以进行归约。 • YACC的默认解决方案 • 移进/归约冲突时,执行移进动作,即移进先于归约; • 归约/归约冲突时,用YACC源程序中第一个出现的产生式进行归约。 • 用户解决方案:规定优先级和结合性
%left '+' '-' %left '*' '/' %right uminus E :E '+' E { $$=$1+$3;} | E '-' E { $$=$1-$3;} | E '*' E { $$=$1*$3;} | E '/' E { $$=$1/$3;} | '-' E %prec uminus { $$=-$2;} | num { $$=$1;} ; 例2.11 对于如下产生式: 产生式的优先级和结合性与产生式右部最右边的终结符一致。若不一致时,采用占位符(place holder)的方法解决。如上边的%prec uminus。 如果不说明%prec uminus,则产生式E:'-'E对于输入序列-3*6,处理结果是-(3*6),即在-的情况下遇到*时先移进。而说明之后,处理结果是(-3)*6。
2.2.3.2 YACC对语义的支持 分析器工作原理: 语义栈对语法制导翻译提供直接支持。语义栈的类型决定了文法符号的属性,语义栈类型表示能力的强弱决定了YACC的能力。
<1> YACC默认的语义值类型 YACC语义栈与yylval同类型,并以终结符的yylval值作为栈中的初值。因为yylval的默认类型为整型,所以,当用户所需文法符号的语义类型是整型时,无需定义它的类型。如在下述表达式的产生式中: E :E '+' E { $$=$1+$3;} | E '*' E { $$=$1*$3;} | num ;
<2> 所需语义值不是整型 用 #define YYSTYPE new_type冲去默认的int类型,然后通过YACC所生成分析器中的变量声明语句使yylval获得新的类型。例如: YYSTYPE yylval; 使得yylval具有new_type类型。 例2.11 #define YYSTYPE treeptr typedef struct tnode { int data; struct tnode *left; struct tnode *right; } treenode,*treeptr; E :E '+' E { $$ = node('+',$1,$3);} | E '*' E { $$ = node('*',$1,$3);} | num { $$ = leaf($1);} ; 就会为E构造一棵语法树
<3> 所需语义值不止一个类型 • YACC源程序中文法符号的语义值往往需要具有不止一种类型,通过C语言提供的union机制来解决这一问题。 • 定义不同的语义值类型: • %union { • int ival; • double dval; • treeptr tval; • } • 在声明文法符号的同时说明它们的语义值类型: • %token <ival> num • %token <dval> real • %token <tval> id • %type <ival> E (非终结符的说明用%type) 注意:%type用于说明非终结符的语义值类型 %prec用于说明非终结符的优先级与结合性
2.2.3.3 YACC源程序的一般书写习惯 • 设计YACC的产生式时,尽量采用左递归形式。由于左递归意味着归约先于移进,所以左递归产生式构造的分析器可以使移进/归约分析栈的内容总是保持最少,而右递归意味着移进先于归约,所以右递归产生式构造的分析器,在极端的输入情况下,会使分析栈溢出。 • 充分利用优先级和结合性,而不是引进非终结符来解决文法中的冲突,以减少产生式个数。特别是尽量避免形如E→T的单非产生式,以提高分析速度。 • 终结符和非终结符在书写上最好有明确区分,例如分别用大、小写来表示非终结符和终结符,以便于程序的阅读。 lex与yacc实例(看演示)
2.2.3.4 YACC对语法错误的处理 没有处理语法错误功能的语法分析器对含有语法错误的输入序列进行分析时,遇到第一个语法错误时分析器就会停止分析。这给用户带来极大不便,同时也是不实用的。因此,YACC提供处理语法错误的机制,它采用的方法是所谓的出错产生式方法。 <1> 不引入出错产生式的情况 在没有适当的语法错误处理的情况下,YACC生成的语法分析器对输入序列进行分析时,遇到语法错误时会由于在栈顶形不成该语言的活前缀(形不成产生式的右部),而找不到适当的产生式与之匹配,从而造成栈中元素被连续弹出,直到栈被弹空,迫使分析过程终止。
一条没有出错处理机制的产生式 %left ‘+’ %% E : E ‘+’ E | num; (b) 分析表的正文形式 (c) 图形表示的DFA (d) 在DFA上分析3++5 栈顶内容 剩余输入 分析器动作 # 0 3++5# 移进num,转向state 2 # 0 num 2 ++5# 按(2) “E : num”归约,goto state 1 # 0 E 1 ++5# 移进 +,转向3 # 0 E 1 + 3 error+5# 输入序列中插入error,弹出state 3 # 0 E 1 error+5# 弹出state 1 # 0 error+5# 弹出state 0 # error+5# ?
<2> 引入出错产生式的情况 为了解决这一问题,YACC引入了对特殊终结符error的处理,利用它在适当的地方加入若干"出错产生式",即含有特殊终结符error的产生式。 加入出错产生式:E : E ‘+’ E | num | error; 图形表示的DFA: 此时有了error的状态转移!
引入出错产生式的情况(续) 再分析3++5 栈顶内容 剩余输入 分析器动作 # 0 3++5# 移进 num,转向state 3 # 0 num 3 ++5# 按(2)“E : num”归约,goto State 1 # 0 E 1 ++5# 移进 +,转向State 4 # 0 E 1 + 4 error+5# 移进error,转向 state 2 # 0 E 1 + 4 error 2 +5# 按(3)“E : error”归约,goto State 5, # 0 E 1 + 4 E 5 +5# 按(1)“E : E‘+’E”归约,goto State 1 # 0 E 1 +5# 移进 +,转向State 4 # 0 E 1 + 4 5# 移进 num,转向 State 3 # 0 E 1 + 4 num 3 # 按(2)“E : num”归约,goto State 5 # 0 E 1 + 4 E 5 # 按(1)“E : E‘+’E”归约,goto State 1 # 0 E 1 # 接受
<3> YACC生成的分析器处理错误的一般原则 • 当认为当前有错时(栈顶不匹配,即找不到下一个可匹配的终结符),就插入一个error到输入中,并从栈中弹出若干状态对(也可能无需弹出),直到找到含有项目 [A →. error α]的状态(如状态4),此时移进 error α(α可能为空,例如状态4下E→. error);(移进) • 按A→error α.归约后,抛弃若干输入字符(可能无需抛弃,最多可能抛弃3个),直到发现一个能回到正常分析的终结符(称为同步记号)为止。(归约) • 是否弹栈和是否抛弃若干输入,视输入序列而定。 • 一般模式: • 出错→插入error在当前输入→弹出栈中若干对(也可能不弹出),直到与error匹配→归约后抛弃若干输入(也可能不抛弃)→分析继续进行。
<3> YACC生成的分析器处理错误的一般原则(续1) 4. 分析5 5+5,既从栈中弹出若干状态对,又在归约后抛弃若 干字符。 栈顶内容 剩余输入 分析器动作 # 0 5 5+5# s2 # 0 num 2 5+5# r2,goto State 1 # 0 E 1 error 5+5# pop(E, 1) # 0 error 5+5# s2 # 0 error 2 5+5# r3,goto State 1 # 0 E 1 5+5# 抛弃5 # 0 E 1 +5# s4 # 0 E 1+4 5# s3 # 0 E 1+4 num 3 # r2, goto state 5 # 0 E 1+4 E 5 # r1, goto state 1 # 0 E 1 # $end, accept
为使分析器尽快从错误中恢复过来,YACC提供一个过程yyerrok,执行它后,分析器不再抛弃输入序列中的终结符,使分析器回到正常操作方式。在使用yyerrok时应注意,如果产生式形如A→error,其后语义动作中加入yyerrok时,会使分析器不再抛弃终结符,而这时分析器也不会移进任何终结符,从而使分析器陷入死循环。 <3> YACC生成的分析器处理错误的一般原则(续2) <4> 如何设计出错产生式 • ① 初学者感觉困难的原因 • 语法错误出现的随机性和文法的复杂性,使得在文法中加入出错产生式去预置对语法错误的处理带有一定的盲目性; • 处理机制没有统一标准; • 过多地加入error会人为造成冲突,使得有些出错产生式不能同时加入。
例2.12 对于下述产生式: <4> 如何设计出错产生式(续1) %% LS :LS E '\n' { printf("%d\n",$2);} | E '\n' { printf("%d\n",$1);} | error { yyerror(“lines: error”); } (从一行中恢复) ; E :E '-' E { $$=$1-$3;} | E '*' E { $$=$1*$3;} | num | error { yyerror(“expr: error”); } (从一个表达式中恢复) ; %% 保留第一个出错产生式,执行的结果为: 711 lines :error lines :error 保留第二个出错产生式,执行的结果为: 711 expr :error 34 expr :error -22 考虑输入序列: 23*34-5-2*3 23*4-23*2+5-6*2 23*4-23*2-6+5*3-4
<4> 如何设计出错产生式(续2) • ② 出错产生式加入的位置与语法分析的关系: • 越接近终结符(如E :error),错误定位越精确; • 越接近开始符号(如LS : error)分析栈越低。 • ③ 加入出错产生式的一般原则: • 避免产生冲突; • 尽量接近文法的开始符号(使分析栈尽可能低); • 尽量接近终结符(使出错定位较精确); • 最好不要加在产生式最右边(即A →α error β中,β最好不为空); • 为关键结构(如条件、循环等)引入出错产生式。 2.2.4 YACC源程序举例(略,可参阅“解答”)
2.3 其他语言识别器生成工具简介 词法分析器生成器和语法分析器生成器,就其真实作用来讲,并不仅仅用于编译器的编写,凡是需要语言识别的应用软件,均可以利用它们来构造。 因此更确切地讲,它们是一类语言识别器生成工具。由于LEX和YACC的广泛应用,似乎给人造成了这样的错觉,语言识别器生成工具就是LEX和YACC及其类似产品。 但实事并不是这样,根据生成器的目标语言、功能需求、基于的文法、以及生成器之间的耦合程度等不同,形成了它们的多样性。程序设计资源网站: http://www.devlib.org/Programming/Compilers/Lexer_and_Parser_Generators 提供了大量这方面的链接,下边讨论中所涉及的各类生成器的详细资料,亦可从该网站查到。 当然被用户广泛接受和应用的仍然是LEX和YACC一族。
<1> 不同的目标语言 • 生成器所能自动生成的识别器仅能识别语言的结构,而对于识别出的语言结构的语义处理,仍然需要用户用某种程序设计语言和借助于生成器提供的某些便利来实现。因此这类生成器的一个共同特点是: • 语义的描述依赖于一种(或若干种)程序设计语言; • 生成的目标代码是这种(或这些)程序设计语言的源程序模块。 由于应用需求和开发环境的多样性,需要生成器支持多种程序设计语言。传统的方法是固定支持一种特定的程序设计语言,如C/C++、Pascal(Delphi)、Java、C#、Python等等。另一种方法是生成一个独立的分析表,然后通过提供不同的分析器引擎(parser engine)来达到支持多种语言环境的目的。 例如GOLD(Grammar Oriented Language Deverloper)就采用这种方法,这种分析表与分析程序分离的形式显然是一种具有发展前景的体系结构。
<2> 词法分析器的功能扩展 扩展正规式。从广义上讲,词法分析器的作用实质上是对以正文形式表示的输入序列进行识别。不但可以识别程序设计语言所需要的、较为简单的记号,也应该可以处理更为复杂的各种类型的模式匹配。为此有些词法分析器生成器对正规式集进行扩展,提供了方便、多样、灵活的匹配模式供用户选择,典型的例子如TLEX中所提供的or与and模式,以及前缀、后缀、子串等多种模式。 另一扩展是支持国际化。随着互连网的广泛应用,需要词法分析器识别不同国家的文字,因此要求词法分析器生成器对字母的处理范围从原来的单字节扩大到双字节。当前绝大多数的词法分析器生成器采取了统一的解决方案,即支持unicode。
<3> 不同文法的语法分析器生成器 语法分析器分为两大类:基于LL文法系列的自上而下分析和基于LR文法系列的自下而上分析。两类分析器均可自动生成,并且都得到了广泛的应用。 基于LR文法系列的生成器的典型代表就是LEX/YACC类,也是应用最为普遍的一类。包括:Bison、CUP、Yacc++、Bison++、YaYacc、Thinkage YAY、TP Yacc、Elkhound、Rie等等。这些成果大多集中于北美。 基于LL文法系列的生成器有:Coco/R、CppCC、Grammatica、LLgen、PCCTS、PRECC、Spirit、SLK等等。这方面的研究大多集中于欧洲。
松耦合与紧耦合 • 紧耦合举例:(一个简化了的Coco/R源程序 ) <4> 词法分析与语法分析的耦合程度 COMPILER Demo CHARACTERS letter = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrtsuvwxyz". digit = "0123456789". EOL = '\t'. TOKENS ident = letter {letter | digit}. number = digit {digit}. COMMENTS FROM "/*" TO "*/" NESTED IGNORE EOL PRODUCTIONS Demo = Statement {";" Statement}. Statement (. string x; int y; .) = Ident "=" Number (.CodeGen.Assign(x, y); .). Ident = ident (. x = t.val; .). Number= number (. n = Convert.ToInt32(t.val); .). END Demo.
语言识别器生成器始于上个世纪70年代,发展于80年代、成熟于90年代。 <5> 现状与发展 • 文法与分析方法 • 将LALR(1)文法扩展为GLR(Gnenralized LR)文法,与LALR(1) ,GLR消除了两条限制:无限制的lookahead和支持二义文法。 • 将LL(1)文法扩展扩展为LL(K)文法,支持无限制的lookahead。 • 语义扩展 • 通过引入属性文法,提供对语义处理的更多支持。一些生成器已可以自动构造抽象语法树并提供内置的符号表处理机制,从而降低编译器的构造强度。 • 开发与应用环境 • 开发手段的进步表现在提供可视化与集成环境,应用环境的进步表现在所生成的软件独立于平台和程序设计语言、支持程序再入与多线程、支持软件重用、提供预定义的类和跟踪调试工具等。但这大多是商业化产品。
分析表的正文形式 state 0 $accept : .E // 项目E'→.E。 num shift 2 // 遇到num,转向状态2 . error // 其它任何均为error E goto 1 // 遇到E,转向状态1 state 1 $accept : E. // 项目E'→E. E : E.+ E // 项目E→E.+E $end accept // 遇到结束标志,正确结束 + shift 3 // 遇到+,转向状态3 . error // 其它任何均为error state 2 E : num. (2) // 项目E→num.(2)表示第二个产生式 . reduce 2 // 按第二个产生式归约
n + $end E 0 s2 1 1 s3 acc 2 r2 r2 r2 3 4 4 r1 r1 r1 分析表的正文形式(续) state 3 E : E +.E // 项目E→E+.E num shift 2 // 遇到num,转向状态2 . error // 其它任何均为error E goto 4 // 遇到E,转向状态4 state 4 E : E.+ E // 项目E→E.+E E : E + E. (1) // 项目E→E+E. (1)表示第一个产生式 . reduce 1 // 按第一个产生式归约 返回













