Download
1 / 1
10 likes | 243 Views
a(X ) : nonlinear amplitude scaling (log) g(f) : nonlinear frequency warping (Mel-like function). h(t ) : time “warping” function—non-uniform time resolution. Basis vectors:. Basis vector :.

E N D
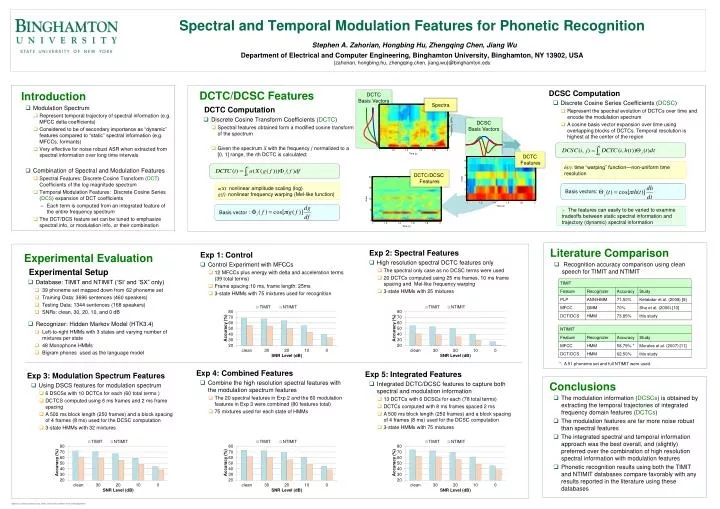
a(X): nonlinear amplitude scaling (log) g(f): nonlinear frequency warping (Mel-like function) h(t): time “warping” function—non-uniform time resolution Basis vectors: Basis vector : Spectral and Temporal Modulation Features for Phonetic RecognitionStephen A. Zahorian, Hongbing Hu, Zhengqing Chen, Jiang Wu Department of Electrical and Computer Engineering, Binghamton University, Binghamton, NY 13902, USA{zahorian, hongbing.hu, zhengqing.chen, jiang.wu}@binghamton.edu DCTC Basis Vectors • DCSC Computation • Discrete Cosine Series Coefficients (DCSC) • Represent the spectral evolution of DCTCs over time and encode the modulation spectrum • A cosine basis vector expansion over time using overlapping blocks of DCTCs. Temporal resolution is highest at the center of the region • DCTC/DCSC Features • DCTC Computation • Discrete Cosine Transform Coefficients (DCTC) • Spectral features obtained form a modified cosine transform of the spectrum • Given the spectrum X with the frequency f normalized to a [0, 1] range, the ith DCTC is calculated: Spectra • Introduction • Modulation Spectrum • Represent temporal trajectory of spectral information (e.g. MFCC delta coefficients) • Considered to be of secondary importance as “dynamic” features compared to “static” spectral information (e.g. MFCCs, formants) • Very effective for noise robust ASR when extracted from spectral information over long time intervals • Combination of Spectral and Modulation Features • Spectral Features: Discrete Cosine Transform (DCT) Coefficients of the log magnitude spectrum • Temporal Modulation Features: Discrete Cosine Series (DCS) expansion of DCT coefficients • Each term is computed from an integrated feature of the entire frequency spectrum • The DCT/DCS feature set can be tuned to emphasize spectral info, or modulation info, or their combination DCSC Basis Vectors DCTC Features DCTC/DCSC Features • The features can easily to be varied to examine tradeoffs between static spectral information and trajectory (dynamic) spectral information • Exp 2: Spectral Features • High resolution spectral DCTC features only • The spectral only case as no DCSC terms were used • 20 DCTCs computed using 25 ms frames, 10 ms frame spacing and Mel-like frequency warping • 3-state HMMs with 25 mixtures • Exp 1: Control • Control Experiment with MFCCs • 12 MFCCs plus energy with delta and acceleration terms (39 total terms) • Frame spacing:10 ms, frame length: 25ms • 3-state HMMs with 75 mixtures used for recognition • Experimental Evaluation • Experimental Setup • Database: TIMIT and NTIMIT (‘SI’ and ‘SX” only) • 39 phoneme set mapped down from 62 phoneme set • Training Data: 3696 sentences (460 speakers) • Testing Data: 1344 sentences (168 speakers) • SNRs: clean, 30, 20, 10, and 0 dB • Recognizer: Hidden Markov Model (HTK3.4) • Left-to-right HMMs with 3 states and varying number of mixtures per state • 48 Monophone HMMs • Bigram phones used as the language model • Conclusions • The modulation information (DCSCs) is obtained by extracting the temporal trajectories of integrated frequency domain features (DCTCs) • The modulation features are far more noise robust than spectral features • The integrated spectral and temporal information approach was the best overall, and (slightly) preferred over the combination of high resolution spectral information with modulation features • Phonetic recognition results using both the TIMIT and NTIMIT databases compare favorably with any results reported in the literature using these databases • Literature Comparison • Recognition accuracy comparison using clean speech for TIMIT and NTIMIT *: A 51-phoneme set and full NTIMIT were used. • Exp 4: Combined Features • Combine the high resolution spectral features with the modulation spectrum features • The 20 spectral features in Exp 2 and the 60 modulation features in Exp 3 were combined (80 features total) • 75 mixtures used for each state of HMMs • Exp 5: Integrated Features • Integrated DCTC/DCSC features to capture both spectral and modulation information • 13 DCTCs with 6 DCSCs for each (78 total terms) • DCTCs computed with 8 ms frames spaced 2 ms • A 500 ms block length (250 frames) and a block spacing of 4 frames (8 ms) used for the DCSC computation • 3-state HMMs with 75 mixtures • Exp 3: Modulation Spectrum Features • Using DSCS features for modulation spectrum • 6 DSCSs with 10 DCTCs for each (60 total terms ) • DCTCS computed using 6 ms frames and 2 ms frame spacing • A 500 ms block length (250 frames) and a block spacing of 4 frames (8 ms) used for the DCSC computation • 3-state HMMs with 32 mixtures