Download

1 / 23
240 likes | 548 Views
HDFS write/read flow and performance optimization. 2/20/2014 Chen weicheng. Outline. Background HDFS write/read flow Some test results Write Pipeline Analyze. Background. The age of Big Data is coming Big data computing become cheaper. Background for Intel. China Rack Project

E N D
HDFS write/read flow and performance optimization 2/20/2014 Chen weicheng
Outline • Background • HDFS write/read flow • Some test results • Write Pipeline Analyze
Background • The age of Big Data is coming • Big data computing become cheaper
Background for Intel • China Rack Project • Powerful hardware • IDH(Intel Hadoop)
Our team • Small team under DCSG • One manager • Two interns • Focus on HDFS write/read • Zero technology accumulation
Why HDFS? • Foundation of Hadoop (importance) • More chance to optimize (possibility)
What We Should Do • Read HDFS Source Code • Understand Write/Read Flow • Looking for opportunity to optimize • Source code level • Hardware level
Outline • Background • HDFS write/read flow • Some test results • Write Pipeline Analyze
Related Conceptions File hierarchy in HDFS Roles in HDFS
NameNode 2:create Distributed FileSystem HDFS Client 1:create HDFS Write Flow 3:write 7:complete FSData OutputStream 6:close Client 4:write packet 5:ack packet 4 4 Pipeline of datanodes DataNode1 DataNode2 DataNode3 5 5
Client related 1.Request HDFS Client 2.Create DistributedFileSystem FS put 3.Create DFSClient 4.Create 7.Write data DFSOutputStream Write() Buffer 5.Start Write1() DataStreamer Chunk notify 6.Start checksum add ResponseProcessor WriteChunk() dataqueue DFSOutputStream
DataNode related HDFS Client 3.DataInputStream 1.Request DataXceiver DataXceiverServer 2.Create 4.OP_WRITE_BLOCK DataXceiver.writeBlock() Block 5.Create streams PacketResponder BlockReceiver. receiveBlock() 6.Create thread 7.while(true) BlockReceiver. receivePacket() Packet DataNode
HDFS Read Flow NameNode Distributed FileSystem HDFS Client 1:open 2:get block location 3:Read FSData InputStream 6:close Client 5:read 4:read DataNode DataNode DataNode
Outline • Background • HDFS write/read flow • Some test results • Write Pipeline Analyze
Test Configurations Per server • 2x E5-2680 • 32GB DIMM or more • 3x 2TB SATA (7200 RPM) • Network—1GbE, IP over infiniband (IPoIB) • Hadoop Versions—1.1.2, 2.0.5, 2.1.0 Intel Confidential
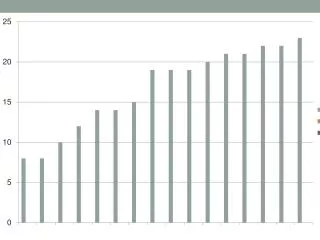
Put Time Time(s) packet
Packet transfer efficiency Intel Confidential
Conclusion(packet) • File put time different on different packet sizes due to the different transfer efficiency in stream. • Best performance of packet size • 128k for 1GbE • 512k for IPoIB • For the 1st block of a file, Hadoop v2.1.0 Initialization spends longer time than v1.0 Intel Confidential
Outline • Background • HDFS write/read flow • Some test results • Write Pipeline Analyze
Write-Read Flow: Write-Read Flow(Packet) of HDFS Client DN1 DN2 DN3 Write-Read Flow(Packet) of HDFS (With DataQueue) Client DN1 DN2 DN3