Download

1 / 23
230 likes | 376 Views
XML Document Object Model (DOM). http://www.w3schools.com/dom / Dr. Galip AYDIN. DOM. DOM bir W3C ( World Wide Web Consortium ) standardıdır XML ve HTML gibi dokümanlara erişim için standart bir yol tanımlar

E N D
XML DocumentObject Model (DOM) http://www.w3schools.com/dom/ Dr. Galip AYDIN
DOM DOM bir W3C (World Wide Web Consortium) standardıdır XML ve HTML gibi dokümanlara erişim için standart bir yol tanımlar "The W3C Document Object Model (DOM) is a platform and language-neutral interface that allows programs and scripts to dynamically access and update the content, structure, and style of a document."
DOM • DOM standart modeller tanımlayan 3 farklı parça/seviye içerir • Core DOM: Herhangi bir yapısal doküman için • XML DOM: XML dokümanları için • HTML DOM: HTML Dokümanları için
XML DOM • XML için • standart bir nesne modeli • Standart bir programlama arayüzü • Platform ve dilden bağımsız • XML DOM bütün XML elementleri için nesne ve özellikleri ve bunlara erişim için gerekli metodları (arayüzler) tanımlar • Diğer bir deyişle DOM, XML elementlerine erişim, değiştirme, ekleme, silme gibi işlemler için bir standart sağlar.
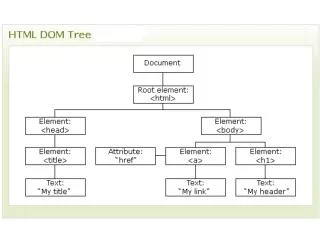
DOM Node • DOM açısından XML içindeki herşey bir düğümdür (node) • Dokümanın kendisi doküman düğümüdür • Her bir xml elementi bir element düğümüdür • XML elementlerinin içindeki yazılar yazı düğümüdür (textnode) • Herbir nitelik (attribute) nitelik düğümüdür • Yorum düğümleri de bulunabilir
DOM Ağacı Düğüm ağacındaki her bir düğümün diğerleriyle hiyerarşik bir ilişkisi vardır Bu ilişkileri anlatmak için ebeveyn, çocuk ve kardeş (parent, children, siblings) terimleri kullanılır Ebeveyn düğümlerin çocukları vardır Aynı seviyedeki çocuklar kardeş (kız veya erkek) olarak adlandırılırlar
Düğüm Ağacında İlişkiler Bir düğüm ağacında en tepedeki düğüme kök denir Kök düğüm hariç her düğümün sadece bir ebeveyni vardır Bir düğümün sınırsız sayıda çocuğu olabilir Çocuğu olmayan düğümlere yaprak denir Aynı ebeveyne sahip, aynı seviyedeki düğümlere kardeş denir
XML DOM Parser XML dokümanlarını ayrıştırmak için kullanılan çeşitli uygulamalar (parser) yazılmıştır XML DOM modeli elemanlara erişim, değiştirmek, silmek veya eklemek için metotlar içerir ancak öncelikle dokümanın DOM nesnesine yüklenmesi gerekir
JavaScript DOM Parser if (window.XMLHttpRequest) {xhttp=new XMLHttpRequest(); }else // IE 5/6 {xhttp=new ActiveXObject("Microsoft.XMLHTTP"); }xhttp.open("GET","books.xml",false);xhttp.send();xmlDoc=xhttp.responseXML;
DOM Properties x.nodeName– x düğümünün ismi x.nodeValue - x düğümünün değeri x.parentNode - x düğümünün ebeveyn düğümü x.childNodes-x düğümünün çocukları olan düğümler x.attributes - x düğümünün nitelikleri
XML DOM Metotları x.getElementsByTagName(name) – verilen isimdeki bütün elementleri getir x.appendChild(node) – x düğümüne bir çocuk düğüm ekle x.removeChild(node) – x düğümünden verilen düğümü sil
<script type="text/javascript"> xmlDoc=loadXMLDoc("books.xml"); x=xmlDoc.getElementsByTagName("book")[0].childNodes; y=xmlDoc.getElementsByTagName("book")[0].firstChild; for (i=0;i<x.length;i++) { if (y.nodeType==1) {//Process only element nodes (type 1) document.write(y.nodeName + "<br />"); } y=y.nextSibling; } </script>
title: Everyday Italianauthor: Giada De Laurentiisyear: 2005 <script type="text/javascript"> text="<book>"; text=text+"<title>Everyday Italian</title>"; text=text+"<author>Giada De Laurentiis</author>"; text=text+"<year>2005</year>"; text=text+"</book>"; xmlDoc=loadXMLString(text); // documentElement always represents the root node x=xmlDoc.documentElement.childNodes; for (i=0;i<x.length;i++) { document.write(x[i].nodeName); document.write(": "); document.write(x[i].childNodes[0].nodeValue); document.write("<br />"); } </script>
Java DOM Kütüphaneleri • DOM4J • http://dom4j.sourceforge.net/ • JDOM • http://www.jdom.org/ • Apache XML projeleri • …
DOM4J Örnek import java.net.URL; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.io.SAXReader; public class Foo { public Document parse(URL url) throws DocumentException { SAXReader reader = new SAXReader(); Document document = reader.read(url); return document; } }
Çocuk Düğümlere Erişim public void bar(Document document) throws DocumentException { Element root = document.getRootElement(); // iterate through child elements of root for ( Iteratori = root.elementIterator(); i.hasNext(); ) { Element element = (Element) i.next(); // do something } // iterate through child elements of root with element name "foo" for ( Iteratori = root.elementIterator( "foo" ); i.hasNext(); ) { Element foo = (Element) i.next(); // do something } // iterate through attributes of root for ( Iteratori = root.attributeIterator(); i.hasNext(); ) { Attribute attribute = (Attribute) i.next(); // do something } }
DOM Ağacı Üzerinde Yürüme public void treeWalk(Document document) { treeWalk( document.getRootElement() ); } public void treeWalk(Element element) { for ( inti = 0, size = element.nodeCount(); i < size; i++ ) { Node node = element.node(i); if ( node instanceof Element ) { treeWalk( (Element) node ); } else { // do something.... } } }
Yeni XML Oluşturma import org.dom4j.Document; import org.dom4j.DocumentHelper; import org.dom4j.Element; public class Foo { public Document createDocument() { Document document = DocumentHelper.createDocument(); Element root = document.addElement( "root" ); Element author1 = root.addElement( "author" ) .addAttribute( "name", "James" ) .addAttribute( "location", "UK" ) .addText( "James Strachan" ); Element author2 = root.addElement( "author" ) .addAttribute( "name", "Bob" ) .addAttribute( "location", "US" ) .addText( "Bob McWhirter" ); return document; } }
SAX – Simple API for XML SAX DOM’a alternatif olarak geliştirilmiş bir sıralı erişim ayrıştırıcısıdır (parser). XML dokümanlarını okumak için gerekli araçları sağlar. SAX olay-güdümlü (event-driven) olarak çalışan akışa göre çalışan (stream-parser) bir ayrıştırıcıdır. SAX ayrıştırıcısı karşılaştığı düğümleri sırasıyla işler (event), ve bu işleme dokümanın sonuna kadar devam eder.
SAX vs DOM SAX DOM’a göre daha küçük hafızaya ihtiyaç duyar. Özellikle büyük XML dokümanlarının işlenmesinde bu büyük bir avantajdır. DOM parser tüm XML ağacının hafızaya yüklenmesine gereksinim duyar. Olay-güdümlü yaklaşım dolayısıyla SAX parserDOM’a göre genellikle daha hızlıdır. XSLT ve XPATH gibi bazı teknolojiler tüm XML ağacına ihtiyaç duydukları için SAX parser kullanamazlar.
StAX – XML PullParser Araştırın ! sjsxp Woodstox Aalto