Download

1 / 38
380 likes | 473 Views
Distributed Cluster Repair for OceanStore. Irena Nadjakova and Arindam Chakrabarti Acknowledgements: Hakim Weatherspoon John Kubiatowicz. OceanStore Overview. Data Storage Utility Robustness Security Durability High availability Global-scale. Where our project fits in. Durability

E N D
Distributed Cluster Repair for OceanStore Irena Nadjakova and Arindam Chakrabarti Acknowledgements: Hakim Weatherspoon John Kubiatowicz
OceanStore Overview Data Storage Utility • Robustness • Security • Durability • High availability • Global-scale Distributed Cluster Repair for OceanStore
Where our project fits in Durability • Automatic version-management • Highly redundant erasure-coding • Massive dissemination of fragmentson machines with highly uncorrelated availability. Distributed Cluster Repair for OceanStore
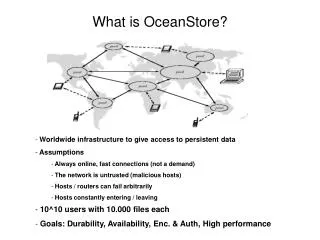
The internet Distributed Cluster Repair for OceanStore
Choosing locations for storing a fragment Distributed Cluster Repair for OceanStore
Choosing locations for storing a fragment Distributed Cluster Repair for OceanStore
Choosing locations for storing a fragment Distributed Cluster Repair for OceanStore
Clustering Distributed Cluster Repair for OceanStore
Clustering Distributed Cluster Repair for OceanStore
OceanStore solution • Availability of each machine tracked over time. • Machines that have very little availability are not used for fragment storage. • Distance between each pair of machines computed. (high mutual information ) close) • Cluster the machines into chunks based on this distance using normalized cuts. • All the computation is done on one central computer (Cluster Server). Distributed Cluster Repair for OceanStore
OceanStore solution • Machines that are highly correlated in availability are in same cluster. • Machines in separate clusters have low correlation in availability. • When a node needs to store replica fragments, it requests cluster information from the cluster server and uses it to send each fragment to k nodes: one from each of k different clusters. Distributed Cluster Repair for OceanStore
Cluster creation • Needs centralized computation. • Can we do it in a distributed manner ? • NCuts is one stumbling block. It seems to need the entire graph. • Having to pull the cluster info from one central cluster server: single point of failure • Can we have a “Distributed NCuts” algo to look at subgraphs ? How to make subgraphs? Do we need to know the entire graph to decide how to divide it into pieces ? Distributed Cluster Repair for OceanStore
Distributed clustering Distributed Cluster Repair for OceanStore
Distributed clustering Distributed Cluster Repair for OceanStore
Distributed clustering Distributed Cluster Repair for OceanStore
Distributed clustering Distributed Cluster Repair for OceanStore
Distributed clustering Distributed Cluster Repair for OceanStore
Initial idea • We run the centralized algorithm once for some time period (chose 73 days) to generate some initial clustering (expensive!) • We distribute the machines among some f cluster servers • Each has a smaller subset of size num of the initial machines • Keeping the initial clustering proportions for each node • Each machine occurs in approximately equal number of cluster servers Distributed Cluster Repair for OceanStore
Initial idea (cont) • Now we can afford to recluster the machines on each server frequently to keep up with the network changes. • Chose to do it once every 30 days for the simulation purposes, but can easily be done a lot more often Distributed Cluster Repair for OceanStore
Evaluation • To see how well this does, we want to compare it with the original global algorithm, run in the same time period. • Metric – the average mutual information I(x,y) = P(x,y) log P(x,y)/P(x)P(y) • Average MI for a single server is just the average of the mutual information between pairs of machines in different clusters on the server • On multiple servers, we compute the above on every server, then average among servers Distributed Cluster Repair for OceanStore
Simulating Network Evolution Dynamics • We have availability data for 1000 machines for a period of 73 days. • We use it to simulate the behavior of a network with 1000 machines over a period of 730 days = 2 years. • We simulate networks with varying evolution characteristics to evaluate the robustness of our distributed cluster repair algorithm. Distributed Cluster Repair for OceanStore
Simulating Network Evolution Dynamics Qualities of a good network: • Maybe server availability (AV) should not vary drastically in the future ? • Maybe average server repair time (MTTR) should not vary drastically ? • Maybe mean time to failure (MTTF) should not vary drastically ? • Maybe failure correlations (FCOR) should also not vary drastically ? Distributed Cluster Repair for OceanStore
NS Algo 1: Sanity Check 1 Global déjà vu • Maintains AV, MTTF, MTTR, FCOR • Simulates a well-behaved network. • Our distributed update algorithm should do very well on this. Distributed Cluster Repair for OceanStore
NS Algo 2: Acid Test 1 Local déjà vu • Maintains AV, MTTF, MTTR, but not FCOR. Distributed Cluster Repair for OceanStore
NS Algo 3: Acid Test 2 Births and Deaths • Maintains AV, MTTF, MTTR, and FCOR, but only for some nodes, and for some time. • Nodes are taken off (die) the network or are addedto (born) the network at certain times. When they are actually on the network, they maintain their AV, MTTF, MTTR, FCOR. Distributed Cluster Repair for OceanStore
NS Algo 4: Acid Test 3 Noisy Global déjà vu • Maintains AV, MTTF, MTTR, FCOR to a large extent, but adds some Gaussian noise, representing the variations that may be observed in a real network. Distributed Cluster Repair for OceanStore
NS Algo 5: Acid Test 4 Noisy Local déjà vu • Maintains AV, MTTF, MTTR, but not FCOR, and also adds some Gaussian noise representing the variations that may be observed in a real network. • Does our algorithm do well in this situation ? If yes, how robust is it to noise ? Distributed Cluster Repair for OceanStore
Still problems • Initial clustering is expensive • What happens if we don’t use it? Distributed Cluster Repair for OceanStore
How to fix this? • Randomly distribute machines to the servers • Perform local clustering • Find the ‘unwanted’ elements (highest mutual information with the rest on this node) • Exchange them with ‘unwanted’ elements of another cluster to which the first ones are least correlated • Communication overhead is low; most computation can proceed without a lot of communication Distributed Cluster Repair for OceanStore
Under development… • What we have so far is a scheme that • picks a server at random • finds a few unwanted elements • exchanges those with the same number of unwanted elements of another server – picked at random, or having the best correlation with the unwanted elements of the first server • The percentage improvement is small so far – 0.4%-1.5% for the first 5 or so runs. It falls off afterwards. Distributed Cluster Repair for OceanStore
How to improve • Exchange more than 1 machines ? • Run for several generations ? • It may be even better to just randomly exchange machines, as long as the overall average mutual information of the distributed cluster decreases. Distributed Cluster Repair for OceanStore
Summary of achievements • Towards getting rid of expensive centralized cluster creation • Scalable distributed cluster management scheme Distributed Cluster Repair for OceanStore
Thanks for listening ! Acknowledgements: Hakim Weatherspoon John Kubiatowicz Distributed Cluster Repair for OceanStore