Download
1 / 27
1.28k likes | 3.83k Views
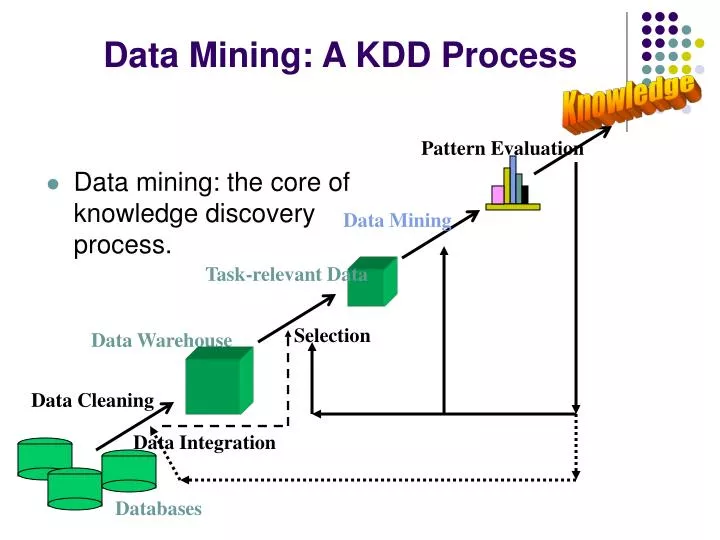
Data Mining: A KDD Process. Knowledge. Pattern Evaluation. Data mining: the core of knowledge discovery process. Data Mining. Task-relevant Data. Selection. Data Warehouse. Data Cleaning. Data Integration. Databases. Steps of a KDD Process. Learning the application domain:

E N D
Data Mining: A KDD Process Knowledge Pattern Evaluation • Data mining: the core of knowledge discovery process. Data Mining Task-relevant Data Selection Data Warehouse Data Cleaning Data Integration Databases
Steps of a KDD Process • Learning the application domain: • relevant prior knowledge and goals of application • Creating a target data set: data selection • Data cleaning and preprocessing: (may take 60% of effort!) • Data reduction and transformation: • Find useful features, dimensionality/variable reduction, invariant representation. • Choosing functions of data mining • summarization, classification, regression, association, clustering. • Choosing the mining algorithm(s) • Data mining: search for patterns of interest • Pattern evaluation and knowledge presentation • visualization, transformation, removing redundant patterns, etc. • Use of discovered knowledge
Architecture of a Typical Data Mining System Graphical user interface Pattern evaluation Data mining engine Knowledge-base Database or data warehouse server Filtering Data cleaning & data integration Data Warehouse Databases
Data Mining: Confluence of Multiple Disciplines Database Technology Statistics Data Mining Machine Learning Visualization Information Science Other Disciplines
Major Issues in Data Mining (1) • Mining methodology and user interaction • Mining different kinds of knowledge in databases • Interactive mining ofknowledge at multiple levels of abstraction • Incorporation of background knowledge • Data mining query languages and ad-hoc data mining • Expression and visualization of data mining results • Handling noise and incomplete data • Pattern evaluation: the interestingness problem • Performance and scalability • Efficiency and scalability of data mining algorithms • Parallel, distributed and incremental mining methods
Major Issues in Data Mining (2) • Issues relating to the diversity of data types • Handling relational and complex types of data • Mining information from heterogeneous databases and global information systems (WWW) • Issues related to applications and social impacts • Application of discovered knowledge • Domain-specific data mining tools • Intelligent query answering • Process control and decision making • Integration of the discovered knowledge with existing knowledge: A knowledge fusion problem • Protection of data security, integrity, and privacy
OLAP-Online Analytical Processing • Data ware house enables OLAP to help decision support. • Organize and format data in various format. • OLTP-Online Transaction Processing • It uses Operational datatbases. • Data w/h is kept separate from Operational DB. • It covers day to day operations of an org. • Such as purchase, inventory, manufacturing, banking, payroll, accounting.
OLTP applications typically automate clerical data processing tasks Data warehouses, in contrast, are targeted for decision support The transactions require detailed, up-to-date data, and read or update a few (tens of) records accessed typically on their primary keys Historical, summarized and consolidated data is more important than detailed, individual records Operational databases tend to be hundreds of megabytes to gigabytes in size Enterprise data warehouses are projected to be hundreds of gigabytes to terabytes in size Consistency and recoverability of the database are critical, and maximizing transaction throughput is the key performance metric Query throughput and response times are more important than transaction throughput OLTP vs OLAP
OLAP-characteristics • Use multi dimensional data analysis techniques. • Provide advance data base support. • Provides easy to use end user interfaces. • Support client/server architecture.
Back End Tools and Utilities • Data Cleaning Tools: Tools that help to detect data anomalies and correct them • E.g. To correct Inconsistent field lengths, inconsistent descriptions, inconsistent value assignments, missing entries and violation of integrity constraints • Types: Data migration tools e.g. Warehouse Manager from Prism Data scrubbing tools e.g. Integrity Data auditing tools: such tools may be considered as variants of data mining tools
Back End Tools and Utilities (Contd.) • Load: After extracting, cleaning and transforming, data must be loaded into the warehouse. e.g., RedBrick Table Management Utility Additional preprocessing may still be required for: checking integrity constraints; sorting; summarization, aggregation and other computation to build the derived tables stored in the warehouse; building indices and other access paths; and partitioning to multiple target storage areas. Methods: Batch load utilities Pipelined and partitioned parallelism To insert only updated table
Back End Tools and Utilities (Contd.) • Refresh: Done only if some OLAP queries need current data • Most contemporary database systems provide replication servers that support incremental techniques for propagating updates from a primary database to one or more replicas. • Techniques: Data shipping and Transaction shipping Transaction shipping has the advantage that it does not require triggers, which can increase the workload on the operational source databases
Conceptual Model and Front End Tools • A popular conceptual model that influences the front-end tools, database design, and the query engines for OLAP is the multidimensionalview of data in the warehouse.
Front End Tools • The spreadsheet is still the most compelling front-end application for OLAP • Popular operations that are supported by the multidimensional spreadsheet: rollup(increasing the level of aggregation) drill-down(decreasing the level of aggregation or increasing detail) along one or more dimension hierarchies slice_and_dice(selection and projection) pivot(re-orienting the multidimensional view of data).
Front End Tools • Other Applications : Traditional analysis by means of a managed query environment These applications often use raw data access tools and optimize the access patterns depending on the back end database server. E.g. there are query environments (e.g., Microsoft Access) that help build ad hoc SQL queries by “pointing-and-clicking”
Database Design Methodology • The database designs recommended by ER diagrams are inappropriate for decision support systems where efficiency in querying and in loading data (including incremental loads) are important • Schema used to represent the multidimensional data model are: Star schema Snowflake schemas Fact constellations
Warehouse Servers • Data warehouses may contain large volumes of data Thus, improving the efficiency of scans is important • Index Structures and their Usage: Warehouse servers can use bit map indices, which support efficient index operations (e.g., union, intersection). • Materialized Views and their Usage: strategy for using a materialized view is to use selection on the materialized view, or rollup on the materialized view by grouping and aggregating on additional columns • Transformation of Complex SQL Queries: “unnesting” complex SQL queries containing nested subqueries • Parallel Processing
Warehouse Servers (Contd.) • Server Architectures for Query Processing: • Specialized SQL Servers: The objective here is to provide advanced query language and query processing support for SQL queries over star and snowflake schemas in read-only environments. e.g. Redbrick • ROLAP Servers: These are intermediate servers that sit between a relational back end server (where the data in the warehouse is stored) and client front end tools e.g. Microstrategy. • MOLAP Servers: These servers directly support the multidimensional view of data through multidimensional storage engine e.g. Essbase (Arbor)
Warehouse Servers (Contd.) • SQL Extensions: Extended family of aggregate functions: rank, percentile, mean, mode, median Reporting Features: moving average Multiple Group-By: Cube and Rollup Comparisons
Metadata and Warehouse Management • Administrative metadata includes: Descriptions of the source databases, back-end and front-end tools; definitions of the warehouse schema, derived data, dimensions and hierarchies, predefined queries and reports; data mart locations and contents; physical organization such as data partitions; data extraction, cleaning, and transformation rules; data refresh and purging policies; and user profiles, user authorization and access control policies Business metadata includes: Business terms and definitions, ownership of the data, and charging policies Operational metadata includes: Information that is collected during the operation of the warehouse: the lineage of migrated and transformed data; the currency of data in the warehouse (active, archived or purged); and monitoring information such as usage statistics, error reports, and audit trails.
Metadata and Warehouse Management (Contd.) • A metadata repository is used to store and manage all the metadata associated with the warehouse. E.g. Platinum Repository and Prism Directory Manager • Warehouse management tools (e.g., HP Intelligent Warehouse Advisor, IBM Data Hub, Prism Warehouse Manager) are used for monitoring a warehouse • System and network management tools (e.g., HP OpenView, IBM NetView,Tivoli) are used to measure traffic between clients and servers, between warehouse servers and operational databases • Workflow management tools been considered for managing the extract-scrub-transform-load-refresh process
Conclusion • There are substantial technical challenges in developing and deploying decision support systems • While many commercial products and services exist, there are still several interesting avenues for research related to the different aspects in designing and maintaining a data warehouse.
References: • Surajit Chaudhuri Umeshwar Dayal Microsoft Research, Redmond, Umeshwar Dayal, Hewlett-Packard Labs, Palo Alto, An Overview of Data Warehousing and OLAP Technology • Inmon, W.H., Building the Data Warehouse. John Wiley, 1992. • Athanasios Vavouras, Stella Gatziu, Klaus R. Dittrich, Modeling and Executing the Data Warehouse Refreshment Process, Technical Report 2000.01, January 2000
















![Knowledge Discovery in Data [and Data Mining] (KDD)](https://cdn2.slideserve.com/4256051/knowledge-discovery-in-data-and-data-mining-kdd-dt.jpg)


