Download

1 / 117
1.18k likes | 1.36k Views
AM18 ASA INTERNALS: QUERY EXECUTION AND OPTIMIZATION. GLENN PAULLEY, DEVELOPMENT MANAGER paulley@ianywhere.com AUGUST 2005. Contents. Query Execution Overview Discussion of join methods, and other relational operators Subquery/function memoization Access plan caching Query optimization

E N D
AM18ASA INTERNALS: QUERY EXECUTION AND OPTIMIZATION GLENN PAULLEY, DEVELOPMENT MANAGER paulley@ianywhere.com AUGUST 2005
Contents • Query Execution • Overview • Discussion of join methods, and other relational operators • Subquery/function memoization • Access plan caching • Query optimization • Overview • Semantic query optimization • New in 9.0: cost-based query rewrite optimization • Selectivity estimation • New techniques for estimating LIKE selectivity • Improvements to histogram maintenance • Join enumeration and index selection • ASA Index Consultant • Forthcoming features in Jasper and beyond
Optimizer overview: role of the optimizer • Select an efficient access plan for the given DML request • Typically queries, but UPDATE and DELETE statements also require optimization • Try to do so in an efficient amount of time • Requires tradeoffs between optimization and execution time • Finding the ‘optimal’ plan a misnomer; we typically only desire an adequate strategy, hence the goal is to avoid selecting poor strategies • Simple DML statements bypass the cost-based optimizer altogether • Uses heuristics for index selection
Optimizer overview: role of the optimizer • For the most part, the 9.0 optimizer makes its decisions based on minimizing a query’s overall resource consumption • In 7.x and prior releases, default was to try and minimize response time • Controlled by the OPTIMIZATION_GOAL connection option • Default is ALL-ROWS • FIRST-ROW setting available via option, or per query using the WITH FASTFIRSTROW table hint • FIRST-ROW assumed if query contains SELECT FIRST or TOP 1 • Desired cursor semantics (SENSITIVE, DYNAMIC, INSENSITIVE, KEYSET-DRIVEN) also play a role • Query syntax independent • At least, that’s the goal – but optimization is an intractable problem • However: optimization is independent of table or predicate order in the original statement
Underlying assumptions • Adaptive Server Anywhere is designed to operate with minimal administration • Assumption: relevant statistics are available • Saved from the execution of previous queries, or • Captured during LOAD TABLE statement, or • Captured with explicit CREATE STATISTICS • Virtual memory is often a scarce resource • Most access plan operators have alternative low-memory strategies • Some operators (recursive joins, hash inner join) have adaptive strategies to revert to index nested loop join when conditions warrant • Cache requirements may be greater than those of older ASA releases
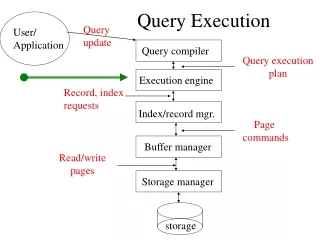
Query execution in 9.0.2: Overview • ASA 9.0.2 supports different physical implementations of various relational operators • Various extensions over those available in 8.x • Optimizer chooses amongst the applicable operators depending on cost, application semantics, amount of cache available • More complex rewritings performed, now based on cost analysis • Offers significant performance improvements over previous releases
Query execution enhancements in ASA 9.0.1 • Improved sequential and index scan performance • Minimize latching of rows at isolation levels 0 and 1 • Reduce the latency for reading a row into memory • Locking can be performed in a scan node, rather than only in a LOCK node • Predicate evaluation pushed into data store whenever possible on sequential scans • Predicates can now appear in SCAN nodes in a graphical plan, rather than in a FILTER node • Improved performance of processing simple LIKE predicates • New WINDOW relational operator
Query execution enhancements in ASA 9.0.1 • Improved hash join performance with better memory management – reduce the number of writes to temporary storage • Sorting combined with SELECT TOP in a single operator • Pinned_cursor_percent_of_cache option • public-only; default of 10% • Introduced in 8.0.1
Query execution enhancements in 9.0.1 • Adaptive query optimization techniques: • Low-memory strategies for sort and hash-based operators, including hash join, recursive hash join, hash DISTINCT, hash GROUP BY, hash INTERSECT and hash EXCEPT join operators • Reimplemented to support partially-pipelined hash, sort • Nested-loop adaptive strategy for RECURSIVE UNION • Used when inputs are small and an index can be exploited • Nested-loop alternative strategy for inner and left-outer hash joins • Used when the “build” side is small, and the probe side is a base table with a suitable index
Query execution enhancements in 9.0.2 • Derived table operator • Used to implement the materialization of a derived table (or view) to ensure correct semantics, particularly with outer joins • Corrected long-standing problems with constant values in the results of outer joins – now constants are also null-supplied to match ANSI semantics • Note differences here with other systems, including ASE and MS SQL Server
Join methods in SQL Anywhere 9.0 • Nested loop ( JNL ) • Hybrid-hash ( JH ) • Sort-merge ( JM ) • Block-nested-loop ( JNB ) • All have Left Outer Join variants • JNL and JH have semijoin (JE and JHE) and anti-semijoin (JNE and JHNE ) variants • FULL OUTER JOIN supported with nested loop (JNLFO), hash (JHFO), and sort-merge (JMFO) methods • Recursive queries supported with Recursive Hash Join (JHR) • LEFT OUTER JOIN variant is JHRO • Recursive nested-loop join is chosen when advantageous at execution time, depending on the size of the inputs and the availability of an appropriate index
Join methods: Hybrid-hash • Very efficient, especially when cache-constrained • Can only be used for equi-joins (inner or left-outer) • New in 9.0: now requires (only) at least one equijoin predicate, other predicates handled as residuals in a two-phase process • Constructs an in-memory hash table of the smaller of the two inputs • Doesn’t require an index to be efficient • New in 9.0: for large joins, partitions are evicted one at a time • Other input is used to probe the hash table to look for matching rows • Pipelining is possible depending on the operators above the join in the access plan • Materialization (e.g. work table) is necessary for scrollable cursors
Hash join Partition Store JH* Bloom Filter Probe input Build input
Join methods: Sort-merge • More efficient than hash join if inputs are already sorted on the join attribute(s) • As with hash join, can only be used for equi-joins (inner, left-outer, or full-outer) • Requires at least one equijoin predicate • Sorts the two inputs by join attribute (if necessary) • Merges the two inputs in the classical way, back-tracking as necessary when encountering duplicates • Pipelining of merge joins are possible, but materialization (work table) is necessary for scrollable cursors
Sort-merge join JM Sort Work File Sort Work File Sort Sort LHS RHS
Join methods: Block-nested loop • Can be used for inner, left-outer joins with at least one equality predicate • JNB requires an index on the RHS to be worthwhile • Reads a block of rows from the LHS input • Sorts the block by join attribute, eliminating duplicates • Probes the RHS input with each distinct join attribute value • Outputs matching rows • Can be more efficient than plain nested loop, depending on duplication factor of the LHS • LHS input is partly materialized
Block Nested-loop JNB SortBlk RHS LHS
Full Outer Join • Three join methods are supported: • Hash full outer (JHFO) • nested-loop full outer ( JNLFO ) • sort-merge full outer ( JMFO ) • JHFO is more efficient, JMFO is most efficient if the inputs are already sorted • Both require at least one equijoin condition • JNLFO will rarely perform well with large inputs • Operator of “last resort” • LHS input cannot utilize an indexed strategy • only alternative if the ON condition does not contain at least one equijoin condition
Bloom Filters and “star” joins • 9.0.2 optimizer includes plan operators to construct and evaluate Bloom filters • Useful in star-join situations or in join queries that involve correlated subqueries or derived tables • Main idea: prevent the processing and/or materialization of intermediate result set rows that will not satisfy the query’s WHERE clause in any event • Bloom Filters are built using a HashFilter (HF) operator • Tests for a value(s) matching a Bloom Filter are hashmap predicates, typically found in Filter plan nodes
Bloom Filters • A bitmap that represents matching values • Filter size depends on the domain involved • a ‘1’ represents a (possible) match (there can be false positives) • A HashFilter operator may precede any blocking operator (one that reads its entire input before returning a row) • Entire intermediate result must be read to create the Bloom Filter • Subsequent Filter operators in other parts of the plan can introduce hashmap predicates • If the corresponding bit of the bitmap is ‘0’, a match is impossible
Grouping/duplicate elimination • SQL Anywhere 9.0 supports three different physical implementations: • hash-based: most efficient, but output isn’t sorted • sort-based: cheapest if the input is already sorted • index-based: fastest if all data is cached, uses less memory • Optimizer chooses from these three alternatives based on cost • New in 9.0.1: clustered hash GROUP BY • Uses index characteristics to determine grouping characteristics of the underlying table • Only enabled by setting the option OPTIMIZATION_WORKLOAD • Default is ‘Mixed’ • Clustered hash GROUP BY is considered if set to ‘OLAP’
Sorting • Two implementations: • index-based • Intermediate result is first materialized, then an index built on that work table; rows read in index sequence using a complete index scan • Technique used in all releases prior to 8.0 • disk-based physical sort • Sorting done in memory • If input is too large, sorted runs are formed from individual partitions • Used for • result set ordering • sort-merge join • sort-based group-by, duplicate elimination
Subquery/UDF Memoization • 9.0 memoizes (caches) results of subqueries and user-defined functions on a per-request basis • Prior to each invocation, cache is accessed to determine if the function has been called previously with the same parameters • If hit ratio is lower than 0.0002, then caching is abandoned • Results are saved starting with fourth invocation of the function/subquery • Size of cache is fixed at four pages • An LRU replacement policy ensures most recent invocations are saved • Can significantly improve CPU consumption, cache pressure, overall elapsed time • Caching is not used for NOT DETERMINISTIC functions • Caching is avoided for functions/subqueries with: • any parameter or result value whose declared length is greater than 254 bytes (eg. BLOB strings) • Total size of parameter and result values exceeding 2560 bytes
Access plan caching • Introduced in the 8.0.1 release • Access plans for DML statements within stored procedures may be cached • New in 9.0: plans now cached for queries that return a result set • Improves stored procedure execution time by eliminating time spent during query optimization • Only those statements whose plans do not change during a “training period” are candidates for plan caching • Simple statements: training period is two queries • Other statements: training period is ten queries • Plans are re-tested periodically on a logarithmic scale, initially every 20 invocations and at least every 640 invocations • New in 9.0.1: plans must be *identical* to enable caching
Access plan caching: caveats • Controlled through a new connection option MAX_PLANS_CACHED • default is 20 • Plan caching is turned off if MAX_PLANS_CACHED is set to 0 • Plans are not cached for statements referencing local or global temporary tables • Useful indicators: • SELECT db_property('QueryOptimized'), db_property('QueryBypassed'), db_property('QueryReused')
The query optimization process • Parser converts query syntax into a parse tree representation • New in 9.0: quantified subquery predicates are no longer normalized into EXISTS predicates • facilitates cost-based subquery rewritings • Heuristic semantic (rewrite) optimization • Parse tree converted into a query optimization graph • Selectivity analysis • Join enumeration, group-by, order optimization performed for each subquery • Includes index selection, physical operator choices, cost-based rewrite optimizations, placement of Bloom filter constructors and predicates • Post-processing of chosen plan • Conversion of optimization structures to execution plan • Construct execution plan
Optimizer bypass • Simple DML statements are optimized heuristically, rather than in a cost-based manner • Done for SELECT, UPDATE, DELETE, INSERT • Not done for INSERT FROM SELECT • A simple statement: • Single-table request: no joins, no nested queries • Only for ASA tables with primary keys (not proxy tables) • No complex operators (DISTINCT, UNION, aggregation) • Equality conditions to constants on PK columns • DELETE statements • No triggers or articles of any kind • No ORDER BY (9.0.2 and up) • UPDATE statements • No articles, COMPUTEd columns, CHECK constraints, triggers, ORDER BY • Each occurrence updates the QUERY_BYPASSED statistic
Semantic query optimization • Also known as query rewrite optimization • Goal is to transform the original query into a syntactically different, but semantically equivalent form • Two flavours of rewrite optimizations in 9.0 • Heuristic-based: premise is that the rewritten query will almost always lead to a better access strategy • New in 9.0: cost-based subquery decorrelation
conversion of outer to inner joins inner join elimination MIN()/MAX() optimization OR, IN-list optimization LIKE optimizations unnecessary ‘distinct’ elimination subquery unnesting predicate normalization, inference and subsumption analysis predicate pushdown in UNION or GROUPed views Semantic query optimization Heuristic rewrite optimizations performed by Adaptive Server Anywhere 9.0
Unnecessary distinct elimination • Eliminates any unnecessary duplicate elimination (DISTINCT) from a query • Based on analysis of derived functional dependencies and candidate keys • Analysis involves computing the transitive closure of conjunctive equality conditions in the WHERE clause and in ON conditions
Unnecessary distinct elimination • ‘Distinct’ is eliminated from the main query block, subquery blocks, views, and derived tables • Series of Distinct query expressions (UNION, EXCEPT, INTERSECT) are optimized and reduced where possible • Examples: • select distinct * from product p • select distinct o.id, o.quantity, o.cust_id • from sales_order o, customer c • where o.cust_id = c.id and c.state = ‘NY’
Subquery unnesting • Heuristic rewrite of nested queries as joins • Done to avoid nested iteration execution strategies, and take advantage of highly selective conditions in the subquery’s where clause • Three cases to consider: • Subquery theta-comparisons of the form ‘column q (subquery)’ • Exists subqueries that can match at most one row from the outer block • Exists subqueries that can match more than one row
Subquery theta-comparisons • e.g. T.x = ( select R.x from R join S where …) • Conversion to join performed only if table constraints can guarantee that the subquery can produce at most one row for each row in the outer block • Otherwise the server must generate a run-time error (SQLSTATE 21W01), cardinality violation
select p.* from product p, sales_order_items s where p.id = s.prod_id and s.id = 2001 and s.line_id = 1 select * from product p where p.id = (select s.prod_id from sales_order_items s where s.id = 2001 and s.line_id = 1) Subquery theta-comparisons PLAN: p<seq>: s<sales_order_items> PLAN: s<sales_order_items> JNB p<product>
Exists subqueries (1 row) • If table constraints can guarantee that a conjunctive exists subquery can produce at most one row for each row in the outer block • Then it is converted to a (simple) inner join (and possibly simplified further) • Example: select * from sales_order_items s where exists (select * from product p where s.prod_id = p.id and p.id = 300) select s.* from product p, sales_order_items s where p.id = s.prod_id and p.id = 300 PLAN: s<seq> PLAN: s<seq>: p<seq>
Exists subqueries (> 1 row) • If table constraints cannot guarantee that a conjunctive exists subquery can produce more than one row • Then it is converted to an inner join combined with duplicate elimination • Example: select distinct p.* from product p, sales_order_items s where p.id = s.prod_id and s.id = 2001 select * from product p where exists (select * from sales_order_items s where s.prod_id = p.id and s.id = 2001) PLAN: DistH[ p<seq> JH* s<sales_order_items> ] PLAN: p<seq>: s<product>
Exists subqueries (> 1 row) • Transformation of subqueries to joins tries to exploit highly selective predicates in the subquery’s where clause (or ON condition) • if additional tuples could be generated, introduce duplicate elimination above the join • Server can use row identifiers, if necessary, if primary keys are unavailable to distinguish between row • in cases where the additional tuples are generated by a join to the inner table, can consider using a semi-join to avoid generating the duplicates • Operator chosen will either be JE (nested loops) or JHE (hash semi-join), depending on estimated execution costs
Inner join elimination • Adaptive Server Anywhere’s optimizer will eliminate a FK-PK or PK-PK inner join if the primary table does not contribute any meaningful expressions to the query • Designed to assist the optimization of queries over views • Not performed for updateable cursors • Example: Select s.* From sales_order_items s, product p Where s.prod_id = p.id PLAN: s<seq> JNB p<product> Select s.* From sales_order_items s Where s.prod_id is not NULL PLAN: s<seq>
Predicate analysis and inference • Converts search conditions to CNF if feasible • Otherwise, appends useful implicates (usually atomic predicates) to the original expression • Eliminates trivial tautologies (1=1) and contradictions (1=0) • Transforms or eliminates syntactic sugar: • X+0 = Y becomes X = Y • ISNULL(X,X) becomes X • X = X becomes X IS NOT NULL • generates transitive equality conditions: • e.g. X = Y and Y = Z implies X = Z
Predicate analysis and inference • Additional improvements over those in SQL Anywhere 8.0.0: • algorithm now generates useful inequality conditions • eliminates IS NULL and IS NOT NULL predicates when they are redundant • performs predicate subsumption analysis to eliminate/transform sets of inequalities • e.g. X < 5 and X < 10 X < 5 • e.g. X < 5 or X > 3 X IS NOT NULL (if X is nullable), otherwise predicate is simply eliminated altogether • subsumption analysis works with both predicates involving literal constants and predicates containing host variables
Example: TPC-H Query 19 • SELECT SUM(L_EXTENDEDPRICE * (1 - L_DISCOUNT) ) AS REVENUE • FROM LINEITEM, PART • WHERE • ( P_PARTKEY = L_PARTKEY and P_BRAND = ‘BRAND#12’ • and P_CONTAINER in (‘SM CASE’, ‘SM BOX’, ‘SM PACK’, ‘SM PKG’) • and L_QUANTITY >= 1 and L_QUANTITY <= 1 + 10 and P_SIZE between 1 and 5 • and L_SHIPMODE in (‘AIR’, ‘AIR REG’) and L_SHIPINSTRUCT = ‘DELIVER IN PERSON’ ) • or • ( P_PARTKEY = L_PARTKEY and P_BRAND = ‘BRAND#23’ • and P_CONTAINER in (‘MED BAG’, ‘MED BOX’, ‘MED PKG’, ‘MED PACK’) • and L_QUANTITY >= 10 and L_QUANTITY <= 10 + 10 and P_SIZE between 1 and 10 • and L_SHIPMODE in (‘AIR’, ‘AIR REG’) and L_SHIPINSTRUCT = ‘DELIVER IN PERSON’ ) • or • ( P_PARTKEY = L_PARTKEY and P_BRAND = ‘BRAND#34’ • and P_CONTAINER in ( ‘LG CASE’, ‘LG BOX’, ‘LG PACK’, ‘LG PKG’) • and L_QUANTITY >= 20 and L_QUANTITY <= 20 + 10 and P_SIZE between 1 and 15 • and L_SHIPMODE in (‘AIR’, ‘AIR REG’) and L_SHIPINSTRUCT = ‘DELIVER IN PERSON’ );
Example: TPC-H Query 19 • Inferred additional conditions: • and P-Partkey = L-Partkey • and L-Shipinstruct = ‘DELIVER IN PERSON’ • and L-Shipmode in (‘AIR’, ‘AIR REG’) • and L-Quantity <= 30 • and P-Container in ( ‘MED BAG’, ‘MED BOX’, ‘MED PKG’, ‘MED PACK’, ‘SM CASE’, ‘SM BOX’, ‘SM PACK’, ‘SM PKG’, ‘LG CASE’, ‘LG BOX’, ‘LG PACK’, ‘LG PKG’) • and P-Brand in (‘BRAND#23’,‘BRAND#12’,‘BRAND#34’) • and P-Size between 1 and 15
Predicate pushdown • Idea is to push predicates past a Group-by or Union operation • Reduces the cardinality of the inputs, thereby reducing the computation necessary to compute the result • Enables alternative access strategies • Can pay handsome dividends with queries over views
Predicate pushdown • Example: Create View V (prod_id, total) as (Select prod_id, count(*) From sales_order_items s Group by s.prod_id); Select * from V Where prod_id = 300; • Predicate pushdown duplicates the condition in the query’s WHERE clause to an equivalent clause in the view • Can be thought of as modifying the view definition on-the-fly for this specific invocation • Reduces the number of rows input to the GROUP-BY operation
Outer join conversion • Outer joins are automatically converted to inner joins when conditions in the query make an inner join semantically equivalent • Enlarges the class of join strategies available for selection by the optimizer • Again, targetted towards applications that utilize complex views • Example: select e.*, o.cust_id, o.order_date from employee e left outer join sales_order o on e.emp_id = o.sales_rep where o.order_date > ‘1999-04-04’ PLAN: o<order_date> JNL e<employee>
Min()/Max() optimization • The optimizer will convert a simple aggregation query over a single table to an indexed retrieval of a single row • Example: SELECT min(quantity) FROM product is converted to: SELECT min(quantity) FROM (SELECT FIRST quantity FROM product ORDER BY quantity ASC) as temp(quantity)
Rewriting IN-lists • Predicates of the form • T.X in (C1, C2, …, Cn) or • T.X = C1 or T.X = C2 or T.X = Cn … • ...can be converted to a join of a single-column virtual table whose rows consist of each value Cj • Requires the presence of an appropriate index on table T with X as the leading column • Permits indexed retrieval of rows in T through an index on column X
Rewriting LIKE predicates • if a LIKE pattern consists solely of ‘%’ • rewritten as IS NOT NULL, eliminated if column or expression is not nullable • if a LIKE pattern contains no wildcards • converted to an equality predicate • estimate selectivity as usual for equality conditions • if a LIKE pattern has a prefix of non-wildcard characters • add an equivalent BETWEEN predicate • Retain the LIKE predicate • estimate selectivity through an index probe or the column’s histogram if available