Download
1 / 51
510 likes | 685 Views
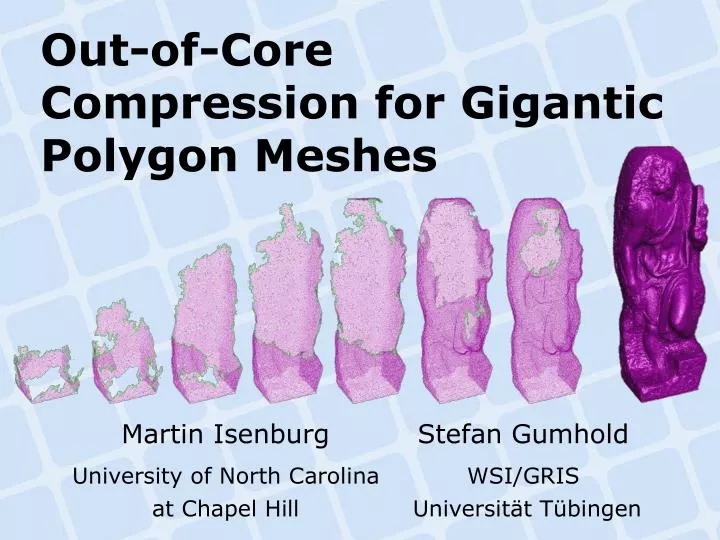
Out-of-Core Compression for Gigantic Polygon Meshes. Martin Isenburg Stefan Gumhold University of North Carolina WSI/GRIS at Chapel Hill Universität Tübingen. Gigantic Meshes. 3D scans. CAD models. isosurfaces. Gigantic Meshes. 3D scans. CAD models. isosurfaces. Gigantic Meshes.

E N D
Out-of-CoreCompression for Gigantic Polygon Meshes Martin Isenburg Stefan Gumhold University of North Carolina WSI/GRIS at Chapel Hill Universität Tübingen
Gigantic Meshes 3D scans CAD models isosurfaces
Gigantic Meshes 3D scans CAD models isosurfaces
Gigantic Meshes 3D scans CAD models isosurfaces
cut into 12 pieces St. Matthew Statue slows down: • transmission • storage • loading • processing 186 million vertices 372 million triangles over 6 Gigabyte
cut mesh into pieces, compress separately, stitch back together “Compressing Large Polygonal Models” [Ho et al. ‘01] Mesh Compression • active research area since ‘95 • many efficient schemes, but ... • mesh has to fit into memory • 2/4 GB limit on common PCs “Geometry Compression” [Deering ‘95]
eliminates number of schemes “Topological Surgery” [Taubin & Rossignac ‘98] “Edgebreaker” [Rossignac ‘99] “Face Fixer” [Isenburg & Snoeyink ‘00] Mesh De-Compression • use 64-bit super computer • but decompress on desktop PC • single pass • small memory foot-print
Contributions • Compressor • minimal access
Contributions • Compressor • minimal access • Out-of-CoreMesh • transparent • caching clusters
Contributions • Compressor • minimal access • Out-of-CoreMesh • transparent • caching clusters • Compact Format • small footprint • streaming
Overview • Related Work • Out-of-Core Mesh • Compression Scheme • Processing Sequences • Conclusion • Current Work
Related Work • Large Mesh Processing • Simplification • Visualization (Multi-Resolution) • Compression • Main Out-of-Core Techniques 1. Mesh Cutting 2. Batch Processing 3. Online Processing
[Hoppe 97] Simplification Visualization [Bernadinietal.99] Compression [Ho et al. 01] 1. Mesh Cutting • cut mesh into smaller pieces • process each piece separately • give special treatment to cuts • stitch result back together
Ho et al. • cut/compress pieces/stitch “Compressing Large Polygonal Models” [Ho et al. ‘01] • artificial discontinuities • special treatment for cuts • compression rates 25% lower • multi-pass decompression • each separately, then stitch • decompression 100 times slower
Simplification [Lindstrom 00] Visualization [Lindstrom 03] + external sorting 2. Batch Processing • work on “polygon soup” • process mesh in increments of single triangles • make no use of connectivity
Simplification [Cignoni et al. 03] Compression [this paper] 3. Online Processing • reorganize mesh data into an external memory structure • allow “random” mesh access • full connectivity available
Cignoni et al. “Octree-based External Memory Mesh” [Cignoni et al. ‘03] • motivation: enable use of high quality simplification • use edge-collapse • simplify in one piece • just like “in-core” • clusters do not storeexplicit connectivity figure courtesy of Paolo Cignoni
half-edge based next struct HalfEdge { Index origin; Index inv; Index next; }; origin inv Out-of-Core Mesh (1) • spatial clustering • stored on disk • cachedclusters
functionality • read only • except for flag per edge mesh.getNext(edge); mesh.getInv(edge);mesh.getOrigin(edge); mesh.isBorder(edge);mesh.isEncoded(edge);mesh.setIsEncoded(edge); mesh.getPosition(vertex); mesh.isManifold(vertex); "isEncoded" Out-of-Core Mesh (2) • cluster index + local index • hide clustering • try to fit in32bits struct IndexPair { int ci : 15; int li : 17; };
clustering input computingconnectivity Construction geometry passes compute bounding box create clustering sort vertices into clusters connectivity passes sort edges into clusters match inverse half-edges link border edges marknon-manifoldvertices
4 9 5 6 8 1 6 3 7 7 7 7 8 9 7 1 8 7 7 9 7 3 7 2 7 7 7 6 7 7 8 4 7 8 7 8 7 9 9 6 6 9 8 2 2 5 Clustering Input compute bounding box create clustering • counter grid • nearest neighbors • graph partitioning sort vertices into clusters
4 9 5 6 8 1 6 3 7 7 7 7 8 9 7 1 8 7 7 9 7 3 7 2 7 7 7 6 7 7 8 4 7 8 7 8 7 9 9 6 6 9 8 2 2 5 Clustering Input compute bounding box create clustering • counter grid • nearest neighbors • graph partitioning sort vertices into clusters
Clustering Input compute bounding box create clustering • counter grid • nearest neighbors • graph partitioning sort vertices into clusters
inv next inv next Computing Connectivity sort edges into clusters matchinverse half-edges • border edges • non-manifold edges are cut link borders non-manifold vertices
871 MB 1.7 GB 11.2 GB on-disk size 96 MB 192 MB 384 MB in-core limit 128 MB 19 min 35 min 7 hours build 49 min 14 min 4 hours compression 5 min 11.0 1.3 2.1 cache misses 2.1 Example Timings
Popular Schemes “Topological Surgery” [Taubin & Rossignac ‘98] “Triangle Mesh Compression” [Touma & Gotsman ‘98] “Triangle Mesh Compression” [Touma & Gotsman ‘98] “Cut-Border Machine” [Gumhold & Strasser ‘98] “Dual Graph Approach” [Li & Kuo ‘98] “Edgebreaker” [Rossignac ‘99] “Face Fixer” [Isenburg & Snoeyink ‘00] “Spectral Compression” [Karni & Gotsman ‘00] “Angle Analyzer” [Lee, Alliez & Desbrun ‘02]
prev next origin edge across Data Structure not yet encoded struct BoundaryEdge { BoundaryEdge* prev; BoundaryEdge* next; Index edge; Index origin_idx; int origin[3]; int across[3]; int slots; bool border; }; already encoded
23 bit ofprecision 23 bit ofprecision 23 bit ofprecision Quantization • precision of 32-bit float? • largestexponentleastprecise 0 4 8 16 32 64 128 x - axis -4.095 190.974
327 1311 20cm 97 388 2.7 m 1553 5 86 22 195 m Samples per Millimeter 16 bit 18 bit 20 bit 22 bit 24 bit
508 MB 1 GB 6.7 GB original 37 MB 61 MB 344 MB compressed 15 sec 27 sec 174 sec load-time 1.5 MB 2.8 MB 9.4 MB foot-print Results
original compressed load-time foot-print 285 MB 28 MB 1 MB 9 sec 1.8 GB 180 MB 63 sec 1 MB Results power plant double eagle
2 GB 4 GB Mesh Formats • indexed meshes • bad for large data sets • polygon soup • efficientprocessing • no connectivity • external memory mesh • seamless connectivity • slow to build & use
Processing Sequences seamless connectivity during fixed traversal
Large Mesh Simplification processed region bufferedregion original method output boundary input boundary unprocessed region using processing sequences “Large Mesh Simplification using Processing Sequences”[Isenburg, Lindstrom, Gumhold, Snoeyink Visualization ‘03]
Summary • Compressor • minimal access • Out-of-CoreMesh • transparent • caching clusters • Compact Format • small footprint • streaming
Issues • lengthofcompressionboundary • possible • but we use only local heuristics • may require too many clusters • causes thrashing O(n) [Bar-Yehuda & Gotsman ‘96] • external memory mesh • expensive to build & use • avoid using it?
streaming small memory footprint Small Footprint Streaming • vertices & triangles interleaved • knowledge when vertex is nolonger needed • concept: “Streaming Meshes”
vertices finalized(not used bysubsequenttriangles) Streaming Meshes • interleave vertices & triangles • “finalize” vertices v 1.32 0.12 0.23v 1.43 0.23 0.92v 0.91 0.15 0.62f 1 2 3done 2 v 0.72 0.34 0.35f 4 1 3done 1 ⋮ ⋮ ⋮ ⋮
out-of-coremesh compressedstreamingmesh streamingmesh compressedstreamingmesh some kindofprocessing compressedstreamingmesh Streaming Compression application indexedmesh