Download
1 / 27
270 likes | 351 Views
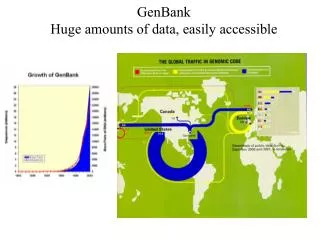
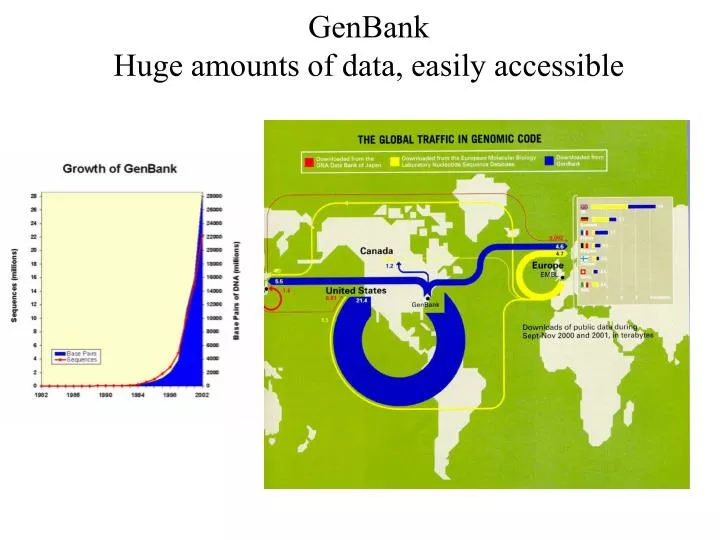
GenBank Huge amounts of data, easily accessible. Rate of growth of phylogenetic knowledge. Number of papers with “molecular” and “phylogeny” in Web of Science. Number of studies in TreeBASE. Why have a phylogeny database?. Archive data and trees (repeat old analyses with new tools)

E N D
Rate of growth of phylogenetic knowledge Number of papers with “molecular” and “phylogeny” in Web of Science Number of studies in TreeBASE
Why have a phylogeny database? • Archive data and trees (repeat old analyses with new tools) • Synthesize new data sets and trees (supermatrices and supertrees) • Big scale questions (tree shape, bias in tree building methods, stability of trees over time) • Hypothesis testing : find all phylogenies for taxa with members in Gondwana -- do they show similar area cladograms, amounts of sequence divergence, etc. • Who knows…(we won’t know until we try)
Obstacles in the way • Ontologies (consistent names for organisms, genes, and other kinds of data) • How to store and query trees (what kind of queries do we want?) • Summarising information in trees (supertrees) and matrices (supermatrices) • Visualising very big trees
Peruvian Diving-petrel(or, what’s in a name?) • ITIS Pelecanoides garnotii • NCBI Pelecanoides garnoti • TreeBASE Pelecanoides garnoti AF076073
TreeBASE Names Projecthttp://darwin.zoology.gla.ac.uk/~rpage/TreeBASE/ • Aim is to map every name in TreeBASE onto a valid taxonomic name (i.e., a name in a database, or in the literature) • Use exact-, substring-, and approximate string matching (+ BLAST) • So far 26819 out of 35084 names mapped
Hemideina maori (weta) 18 TreeBASE names = 1 real name
catodon catadon macrocephalus 3 TreeBASE names = 1 real name Physeter catodon (Sperm Whale)
The case of the Harp seal TreeBASE and GenBank have harp seals under two different names, only ITIS knows that they are the same thing
There are knownknowns, things we know that we know • There are knownunknowns, things we now know we don’t know • But there are also unknownunknowns, things we do not know we don't know
Why taxonomy matters (or vs. )
Searching on “Aves” in TreeBASEfinds 4 studies with birds… • Study #1: Gauthier, J., A.G. Kluge, and T. Rowe. 1988. Amniote phylogeny and the importance of fossils. • Study #2: Harshman, J., C. J. Huddleston, J. P. Bollback, T. J. Parsons, and M. J. Braun. 2003 inpress. True and False Gavials: A Nuclear Gene Phylogeny of Crocodylia. • Hedges, S. B., K. D. Moberg, and L. R. Maxson.1990. Tetrapod phylogeny inferred from 18s and 28s ribosomal RNA sequences and a review of the evidence for amniote relationships. • van Dijk, M. A. M., E. Paradis, F. Catzeflis, and W. de Jong. 1999. The virtues of gaps: Xenarthran (Edentate) monophyly supported by a unique deletion in alphaA-crystallin.
There are 24 bird studies in TreeBASE, but “tree surfing” won’t find them
Arabidopsis rbcL Fig. 1. The `data availability matrix' for green plant protein sequences from GenBank (release 132). A set of 130304 sequences for 14667 species sequences were clustered into 61117 groups of homologous proteins by a combination of BLAST and single-linkage clustering (using the program Blastclust from the NCBI Blast toolkit: http://www.ncbi.nlm.nih.gov/BLAST/ ). A column represents a protein or protein family; a row represents one of the species in the dataset; and a dot indicates the existence of a sequence for that species and protein. Species are sorted vertically by their number of sequences; the most-represented species ( Arabidopsis thaliana ) is at the top. Proteins are sorted horizontally by the number of taxa for which they have been sequenced; the most heavily sequenced gene ( rbcL ) is on the right. This figure shows the most heavily sampled corner of the data availability matrix; the remainder of the matrix is even more sparse.
Seeing the tree (best seen when printed on 1.5 m wide paper…)
Comparing classificationsfor Psocoptera Lienhard & Smithers (2002) [courtesy of Kevin Johnson] 4363 species NCBI (GenBank) 9 species
Bioinformatics envy - GenBank should NOT be our role model www.biomoby.org www.gmod.org
From journal to database… Problem: not enough data and trees in journals make it into databases
Elsevier’s journal Molecular Phylogenetics and Evolution is a criminal waste of our efforts Text, data, trees locked up in paper and PDF
“Oh, the vision thing” George Bush (snr), 1987 … the database is the journal • Data + trees go into database • Text (annotation) added • Automatically generate a report summarising the results • The report is the publication (can have a DOI) • Open Access data and text