Download

1 / 6
60 likes | 156 Views
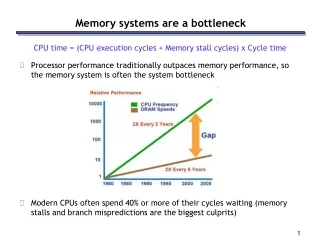
Software Systems Lab Department of Electrical Engineering, Technion. Introduction. Chip Multi Processors are becoming mainstream Cache data access is a major bottleneck in CMPs

E N D
Software Systems Lab Department of Electrical Engineering, Technion Introduction • Chip Multi Processors are becoming mainstream • Cache data access is a major bottleneck in CMPs • NUCA – Non Uniform Cache Access – The physical distances on a chip are becoming relevant • Nahalal architecture speeds up the hit rate and data access time • How can we improve NAHALAL’s performance without increasing the cache sizes? • How can we calculate the working set?
Software Systems Lab Department of Electrical Engineering, Technion Nahalal Architecture • Proposes a layout with one shared cache which is physically close to all the CPUs • Small set of cache lines accounts for a significant portion of memory accesses (80%|20% rule)
Software Systems Lab Department of Electrical Engineering, Technion Dynamic cache allocation • There is a trade off between the cache’s size and hit-time • By dynamically allocating the cache sizes we can overcome this tradeoff • Theoretical potential speed-up compared to original NAHALAL
Software Systems Lab Department of Electrical Engineering, Technion Working set calculation • The working set signature is an n-bit vector formed by mapping working set elements into n-buckets using a randomizing hash function. • The bit-vector is cleared at the beginning of every interval. • Given the fraction of the signature filled, the working set size can be estimated using the relation:
Software Systems Lab Department of Electrical Engineering, Technion JSO algorithm
Software Systems Lab Department of Electrical Engineering, Technion Results and Conclusions • It is possible to improve cache performance by dynamically allocating the shared cache • The working-set signature is sufficiently accurate to estimate the real working set size • Dynamic cache allocation is most efficient when some CPUs are idle Miss rate (smaller is better)