Download

1 / 52
520 likes | 611 Views
Sequence analysis – an overview. A.Krishnamachari chari@mail.jnu.ac.in. Definition of Bioinformatics. Systematic development and application of Computing and Computational solution techniques to biological data to investigate biological process and make novel observations.

E N D
Sequence analysis – an overview A.Krishnamachari chari@mail.jnu.ac.in
Definition of Bioinformatics • Systematic development and application of Computing and Computational solution techniques to biological data to investigate biological process and make novel observations
Research in Biology General approach Bioinformatics era Organism Functions Cell Chromosome DNA Sequences
Information Explosion • GENOME • PROTEOME • TRANSCRIPTOME • METABOLOME
Databases • Literature • Sequences • Structure • Pathways • Expression ratios
Databases • Textual • Symbolic (manipulation possible) • Numeric (computation possible) • Graphs (visualization )
Nucleic Acids Research January Issue
Integrated Database Search Engines http://www.ncbi.nlm.nih.gov/Entrez/ http://srs.ebi.ac.uk http://www.genome.ad.jp/dbget/
Important Databases COG Locus link Uni Gene Human – Mouse Map
Analysis Expression data Primary sequences Structures Pathways DNA Protein Genome 108 Gene 1000
Analysis • Individual sequences • Between sequences • Within a genome • Between genomes
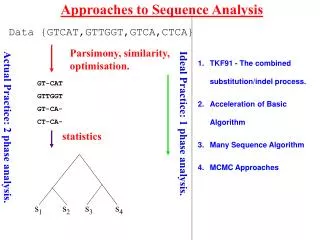
Sequence Analysis • Sequence segments which has a functional role will show a bias in composition , correlation • Computational methods tries to capture bias, regularities, correlations • Scale invarient properties
Sequence Analysis • Sequence comparison • Pattern Finding –repeats, motifs,restriction sites • Gene Prediction • Phylogenetic analysis
Genome Sequence intergenic TSS RBS CDS TF -10 -35 TF -> Transcription Factor Sites TSS->Transcription Start Sites RBS -> Ribosome Binding sites CDS - > Coding Sequence (or) Gene
Protein-DNA interactions • Biological functions • Regulation or Modulation • Specific binding (Specified DNA pattern)
DNA binding sites • Promoter • Splice site • Ribosome binding site • Transcription Factor sites • Restriction Enzymes sites
D I M E R The dimer is constructed such that it has bifoldsymmetry allowing the recognition helix of the second protein sub-unit to make the same groove binding interactions as the first. The distance between the recognition helices is 34 angstroms which corresponds to one turn of the B-DNA double helix. This means that when the recognition helix of one sub-unit binds in the groove of a specific region of DNA, the second sub-units' helix can also bind in the DNA groove, one turn along from the first helix
Odd Symetric Even
DNA binding sites - Model Experimental methods • Foot print expts. (Dnase ) • Methylation Interference • Immuno precipitation assay • Compilation and Model building
TF1 TF1 TF2 TF1 TF3 -145 -120 -40 Design Oligos covering these regions for studying promoter activity Carry out EMSA Carry out Reporter assay Carry out in-vivo experiments Make Observations
Binding site activity BS1 Reporter Gene BS2 -56 -30 -15 -105 BS2 Reporter Gene BS1 -150 -100 -50 BS1 Measure Expression
Statement of the problem • Given a collection of known binding sites, develop a representation of those sites that can be used to search new sequences and reliably predict where additional binding sites occur.
Ribosome Binding sites : Alignment Reference
Variability becomes inherent in biological sequences • manifesting at various length scales • Statistical and probabilistic framework is ideal for studying these characteristics
Sequence Analysis AND Prediction Methods • Consensus • Position Weight Matrix (or) Profiles • Computational Methods • Neural Networks • Markov Models • Support Vector Machines • Decision Tree • Optimization Methods
Strict consensus - TATA Loose consensus - (A/T)R(G/C)YG Weight matrix OR profile
Describing features using frequency matrices • Goal: Describe a sequence feature (or motif) more quantitatively than possible using consensus sequences • Need to describe how often particular bases are found in particular positions in a sequence feature
Describing features using frequency matrices • Definition: For a feature of length m using an alphabet of ncharacters, a frequency matrixis an n by m matrix in which each element contains the frequency at which a given member of the alphabet is observed at a given position in an aligned set of sequences containing the feature
Frequency matrices (continued) • Three uses of frequency matrices • Describe a sequence feature • Calculate probability of occurrence of feature in a random sequence • Calculate degree of match between a new sequence and a feature
Frequency Matrices, PSSMs, and Profiles • A frequency matrix can be converted to a Position-Specific Scoring Matrix (PSSM) by converting frequencies to scores • PSSMs also called Position Weight Matrixes (PWMs) or Profiles
Methods for converting frequency matrices to PSSMs • Using log ratio of observed to expected where m(j,i) is the frequency of character j observed at position i and f(j) is the overall frequency of character j (usually in some large set of sequences)
Finding occurrences of a sequence feature using a Profile • As with finding occurrences of a consensus sequence, we consider all positions in the target sequence as candidate matches • For each position, we calculate a score by “looking up” the value corresponding to the base at that position
Positions (Columns in alignment) V1 x12 + x21 + x33 + x44 + x52 TAGCT AGTGC if is above a threshold it is a site V1
Building a PSSM Set of Aligned Sequence Features PSSM builder PSSM Expected frequencies of each sequence element
Searching for sequences related to a family with a PSSM Set of Aligned Sequence Features PSSM builder Expected frequencies of each sequence element PSSM Sequences that match above threshold PSSM search Threshold Positions and scores of matches Set of Sequences to search
Consensus sequences vs. frequency matrices • consensus sequence or a frequency matrix which one to use? • If all allowed characters at a given position are equally "good", use IUB codes to create consensus sequence • Example: Restriction enzyme recognition sites • If some allowed characters are "better" than others, use frequency matrix • Example: Promoter sequences
Consensus sequences vs.frequency matrices • Advantages of consensus sequences: smaller description, quicker comparison • Disadvantage: lose quantitative information on preferences at certain locations
Shannon Entropy • Expected variation per column can be calculated • Low entropy means higher conservation • Entropy yields amount of information per column
Entropy Or Uncertainty • The entropy (H) for a column is: • a: is a residue, • fa: frequency of residue a in a column, • fa Pa as N becomes large
Information • Information Gain(I)= H before – H after • H before = Genomic composition
Information Content • Maximum Uncertainty = log2 n • For DNA, log2 4 = 2 • For Protein log2 20 Information content I(x) I (x) = Maximum Uncertainty – Observed Uncertainty Note : Observed Uncertainty = Observed Uncertainty – small size sample correction
Ribosome Binding Site Translation start site Shine-Dalgarno Spacer
Binding site regions comprises of both signal(s)(binding site) and noise (background). Studies have shown that the information content is above zero at the exact binding site and in the vicinity the it averages to zero The important question is how to delineate the signal or binding site from the background. One possible approach is to treat the binding site (signal) as an outlier from the surrounding (background) sequences.
Assumption of independence • Prediction models assumes independence • Markov models of higher order require large data sets • This require better data mining approaches