Download

1 / 41
410 likes | 530 Views
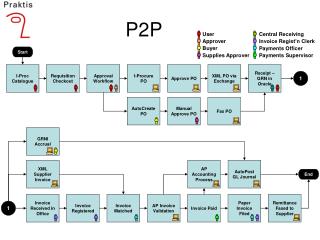
P2P Applications. Andrew Badr Michael Earnhart Feburary 14, 2006. DHTs. DHT Protocols and Applications. Protocols. Applications. Bamboo Bunshin Chord Pastry Tapestry …. OceanStore Codeen PAST Freenet …. Topics. CoDNS - Cooperative DNS lookup PAST - Distributed storage utility

E N D
P2P Applications Andrew BadrMichael Earnhart Feburary 14, 2006
DHTs DHT Protocols and Applications Protocols Applications Bamboo Bunshin Chord Pastry Tapestry … OceanStore Codeen PAST Freenet …
Topics • CoDNS - Cooperative DNS lookup • PAST - Distributed storage utility • OceanStore – persistent storage • SHARP – digital resource economy
CoDNS A Lightweight Cooperative DNS Lookup Service By: K. Park, V. Pai, L. Peterson, and Z. Wang Princeton University
Overview • DNS lookup problems • Nameserver overloading • Resource competition on nameserver • Maintenance problems • Cooperation provides: • Redundancy • Reliability • Performance • Motivation • High variability in lookup times • Significant dependence on extremely reliable DNS
The Current System A collection of DNS Servers Individual DNS Server Failure: A response time greater than 5 seconds including complete failures Healthy: Showing no failures for one minute for the local domain name lookup test
Requirements • Faster more reliable DNS lookups • Incrementally deployed • Minimum resource commitment • Minimum overhead • Essentially DNS insurance • Get help when needed and provide help when needed
Implementation of CoDNS • PlanetLab nodes running CoDeeN • Alter the delay requirement to adjust the number of remote queries • Latency boundaries define proximity, and availability • Heartbeat messages define liveliness • Highest Random Weight (HRW) is used to preserve locality • Hash the node name with lookup name
Experimentation • 5 - 7 Million DNS queries daily from 7 - 12 thousand clients • 95 CoDeeN nodes • 22,208 average lookups per node • Average response time of 60 - 221ms • An improvement of 1.37 - 5.42 times better than Local DNS
Experimentation Data Live Traffic for One Week
Analysis of CoDNS Requirements • Reliability and Availability • Increased by an additional ‘9’ • Resource Commitment • A single added sight yields more that 50% cut in response time with only 38% more DNS lookups • Nearly all are realized with just 10 extra nodes • Overhead • Only 3.25% - 5.0% extra out-bound query traffic • Nearly all “winning” answered within 2 peers • Total average overhead traffic 7.5MB/day
Alternatives • Private Nameservers • Maintenance • Resource consumption • Secondary Namerservers • LAN failures • TCP Queries • Only benefit if UDP packet loss is high • Significant overhead
Problems • Filtering?
PAST A Large-Scale, Persistent Peer-to-Peer Storage Utility By: A. Rowstron, and P. Druschel Microsoft Research and Rice University
Overview • Layered on top of Pastry • Provides underlying distributed functions • Operations • Insert(name, owner-credentials, k, file) • Lookup(fileId) • Reclaim(fileId, Owner-credentials) • Motivation • To provide geographically independent redundant variably reliable storage
Pastry • Leaf Set • l nearby nodes based on proximity in nodeId space • Neighborhood Set • l nearby nodes based on network proximity metric • Not used for routing • Used during node addition/recovery 16-bit nodeId space l = 8, b = 2 Leaf Set Entries 10233102 Slide by: Niru UCLA 2001
Pastry Set of nodes with |L|/2 smaller and |L|/2 larger numerically closest NodeIds Prefix-based routing entries |M| “physically” closest nodes
Features • Fair use • Credit system • Security • Public key encryption • Randomized Pastry routing • File certificates • Storage management
Storage Management • Per-node storage • Every node’s capacity must be within 2 orders of magnitude • Split larger nodes • Refuse smaller nodes • Replica diversion • File diversion • Caching
Replica Diversion • Function • Place files at different nodes in a leaf due to storage requirements • Failure complications • Policies (SD/FN > t) SD = Size of File D FN = Free storage space remaining on node N • Place into local store (tpri) • Select a diverted store (tdiv) tpri > tdiv • Resorting to file diversion
9.0 MB 9.0 MB 9.0 MB 9.0 MB 9.0 MB 9.0 MB 9.0 MB 85% 4 1 Insert A set of 6 numerically close nodes (a leaf) An individual nodes storage utilization The file to be stored File name: Cheney_shoots.mpg File Size: 9.0 MB Replica (k): 3 ID: 110101xx Characteristics 1.0 GB Disks tpri = 0.1 tdiv = 0.05 85% 95% 95% 90% 90% 80%
File Diversion • Function • If Replica Diversion fails • Return a negative-ack requiring a insertion • Policies • Max retries = 4
Decreased tpri Higher failure rate More Files inserted ExperimentationVarying tpri Optimal ratios: tpri: 0.1 tdiv: 0.05
Results - Replica Diversion tpri = 0.1, tdiv = 0.05
Results - File Diversion tpri = 0.1, tdiv = 0.05
Problems • Reclaim != Delete • How to Reclaim cached information • Replica diversion complications • Churn rate … Migrating replicas • “gradually migrated to the joining node as part of a background operation”
OceanStore An Architecture for Global-Scale Persistent Storage By: John Kubiatowicz, David Bindel, Yan Chen, Steven Czerwinski, Patrick Eaton, Dennis Geels, Ramakrishna Gummadi, Sean Rhea, Hakim Weatherspoon, Westley Weimer, Chris Wells, and Ben Zhao – Berkeley
OceanStore • There are nodes • Data flows freely between nodes • like water • in the oceans.
Framework • The motivation: transparent, persistent data storage • The model: monthly fees, like for electricity • Assumption: untrusted infrastructure • Data location: data can be cached anywhere at any time
Data Objects • GUID • Updates • Archive • Fragments • Erasure codes • Hash trees
Access Control • Reader restriction: data is encrypted, and keys given OOB • In the protocol, can ‘revoke’ a file, but this obviously can’t be guaranteed • Writer restriction: all files come with an ACL, and writes come with a signature to match against it
Routing • Try a fast algorithm: attenuated Bloom filters • If that doesn’t work, use the slow but guaranteed algorithm: DHT-style
Introspection • Cluster recognition: Recognizes correlations between multiple files • Replica management: controls how many copies of a single file are created and where they are stored.
Results • It’s mostly theoretical • But a lot of people are working hard on actually building it.
SHARP An Architecture for Secure Resource Peering By: Fun Yu, Jeffrey Chase, Brent Chun, Stephen Schwab, and Amin Vahdat – Duke, Berkeley, and NAL
What’s the big idea? • Sharing and distributing resources in a way that is: • Scalable • Secure • Main example: sharing computer time among many Internet-connected agents
Sharing is Caring • Maybe I’ll need two computers later, and you need two right now. • SHARP’s core functionality is to implement transactions of digital resources, like how we’d want to negotiate the above scenario. • But imagine it on a large scale – a whole economy of computing power
There are a few types of actors: • Site Authorities: abstraction for one administratively unified computational resource. In other words, this agent originates the rights to use a computer, or cluster, or group of clusters… • Agents: mediate between site authorities and resource consumers
Leases You can get a lease to a resource, but that doesn’t guarantee you the resource. • The server might fail • Agents might be dishonest • The consumer might bail • Computation is a perishable commodity
Trade and Economics • Agents can trade leases • All leases come with a cryptographic chain of signatures, so you can trace it back to the origin • This lets site authorities detect misbehaving agents • In the PlanetLab test, this meant bartering of computer resources, but a “digital cash” economy could be worked in
Results • The resource finding (SRRP) and transaction systems worked in PlanetLab test • The crypto and XML makes things slow • Oversubscription greatly improves utilization %, especially when agents fail