Download
1 / 50
500 likes | 670 Views
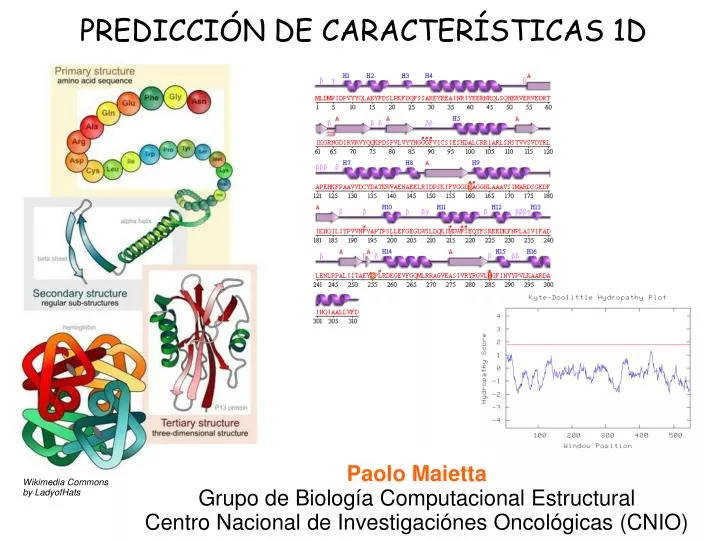
PREDICCIÓN DE CARACTERÍSTICAS 1D. Paolo Maietta Grupo de Biología Computacional Estructural Centro Nacional de Investigaciónes Oncológicas (CNIO). Wikimedia Commons by LadyofHats. Estructura Secundaria. Desorden structural. Accesibilidad al solvente. Elementos transmembrana.

E N D
PREDICCIÓN DE CARACTERÍSTICAS 1D Paolo Maietta Grupo de Biología Computacional Estructural Centro Nacional de Investigaciónes Oncológicas (CNIO) Wikimedia Commons by LadyofHats
Estructura Secundaria Desorden structural Accesibilidad al solvente Elementos transmembrana Otras características 1D Metodología: Implementación de un predictor SUMARIO Definición de características 1D Estructuras de proteínas Predicción de características 1D
Estructura Secundaria Desorden structural Accesibilidad al solvente Elementos transmembrana Otras características 1D Metodología: Implementación de un predictor SUMARIO Definición de características 1D Estructuras de proteínas Predicción de características 1D
Definición características 1D • Todas aquellas que puedan ser representadas por un único valor asociado a casa aminoácido (B. Rost) • Estos valores suelen tomar la forma de etiquetas de estado (ej: estructura secundaria: H → hélice, L → lámina, C → giro). También pueden ser relativos (ej: la accesibilidad al solvente puede representarse en porcentajes) • En algunos métodos, las asignaciones van acompañadas de un valor de fiabilidad
Estructura Secundaria Desorden structural Accesibilidad al solvente Elementos transmembrana Otras características 1D Metodología: Implementación de un predictor SUMARIO Definición de características 1D Estructuras de proteínas Predicción de características 1D
De los aminoácidos …. Cada aminoácido tiene unas características físico - químicas distintas; Estas influyen en el plegamiento de la proteína
>Estructura Primaria ASKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTT GKLPVPWPTLVTTFSYGVQCFSRYPDHMKRHDFFKSAMPEGYVQERTIFF KDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNV YIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHY LSTQSALSKDPNEKRDHMVLLEFVTAAGITHGMDELYK De los aminoácidos …. Cada aminoácido tiene unas características físico - químicas distintas; Estas influyen en el plegamiento de la proteína Y además los aminoácidos están conectados entre si en una cadena ….
Pro Gly … a la Estructura Diagramas de Ramachandran Matthews/Van Holde Biochemistry, 2nd edition
α helices El esqueleto de la proteína adopta una conformación de hélice y en cada giro entran 3.6 residuos. Los enlaces de hidrógenos entre los grupos carboxilo del residuo n y el grupo amino del residuo n+4 estabilizan la estructura. Las hélices son flexibles y las cadenas laterales miran hacia fuera.
a p β strands Los β strands se juntan para generar β sheets gracias a la energía de estabilización de los enlaces de hidrógeno entre las diferentes láminas.
Más β strands and turns ... Los β sheets pueden estar plegados o torcidos pero no son flexibles !! Los β sheets pueden contener láminas paralelas, anti-paralelas o una mezcla de ambas.
Más β strands and turns ... Los β sheets pueden estar plegados o torcidos pero no son flexibles !! En un giro π (i → i+5) En un giro α (i → i+4) En un giro β (i → i+3) En un giro γ (i → i+2) En un giro δ (i → i+1) Los β sheets pueden contener láminas paralelas, anti-paralelas o una mezcla de ambas.
Se puede predecir la estructura ? • Para muchos tipos de proteinas se ha comprobado que su estructura 3D (es decir su plegamiento) viene determinada esencialmente por la especificidad de la secuencia. • La obtención de valores suficientemente precisos para la determinación de los parámetros físicos fundamentales para la resolución de la estructura es un problema dificil. • El cálculo pormenorizado de la influencia que ejerce cada uno de los resíduos en el resto de los aminoácidos de la secuencia, así como en la accesibilidad al solvente es computacionalmente intratable.
Importancia características 1D • Porque estamos interesados en estas propiedades ?? • Basicamente porque proporcionan información útil para caracterizar funcionalmente y estructuralmente una proteína: • Peptidos señal y regiones transmembrana → localización celular, y también función • Las modificaciones post-transcripcionales → procesos biológicos como la regulación • Los métodos de predicción de estructura basados en el reconocimiento del plegamiento, se nutren de estas técnicas Muchos métodos de predicción de estructura utilizan predicción de estructura secundaria y otras predicciones 1D. Esto es muy importante para Fold Recognition y es esencial para métodos ab-initio.
Estructura Secundaria Desorden structural Accesibilidad al solvente Elementos transmembrana Otras características 1D Metodología: Implementación de un predictor SUMARIO Definición de características 1D Estructuras de proteínas Predicción de características 1D
1 ASKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTT TTGGGGSSEEEEEEEEEEEETTEEEEEEEEEEEETTTTEEEEEEEETT 51 GKLPVPWPTLVTTFSYGVQCFSRYPDHMKRHDFFKSAMPEGYVQERTIFF SS SS GGGGHHHHSSS GGGBGGGGGGHHHHTTTT EEEEEEEEE 101 KDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNV TTS EEEEEEEEEEETTEEEEEEEEEEE TTSTTTTT B S EEE 151 YIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHY EEEEEGGGTEEEEEEEEEEEETTS EEEEEEEEEEEESSSS SEE 201 LSTQSALSKDPNEKRDHMVLLEFVTAAGIT HGMDELYK EEEEEEEE TT SSEEEEEEEEEEES Estructura secundaria (DSSP) • DSSP estudia la estructura secundaria en archivos de coordenadas atómicas basándose en patrones que tienen en cuenta: • Geometría • Puentes de Hidrógeno T = giro estabilizado por P de H H = α-helice, ~4 aa por vuelta G = helice 310, ~3 aa por vuelta I = helice phi, ~5 aa por vuelta B = conformacion β E = conformacion β formando lamina S = giro (sin P de H) Kabsch and Sander (1983) Biopolymers 22, 2577-2637
Historia de los métodos Primera generación Métodos estadísticos basados simplemente en la tendencia de cada aminoácido a formar cada uno de los elementos de estructura secundaria Chou y Fasman en 1974, propusieron el primero de estos métodos. Emplearon estadísticas extraídas de las 15 estructuras resueltas por cristalografía de rayos-X en aquella época. Estas probabilidades fueron calculadas para cada resíduo por separado. Más adelante este método mostró una exactitud del 57% sobre 62 proteínas. Garnier (1978). Estimó las probabilidades para interacciones de pares de resíduos significativas, obteniendo una mayor fiabilidad (~60%).
Name P(a) P(b) P(turn) f(i) f(i+1) f(i+2) f(i+3) Alanine 142 83 66 0.06 0.076 0.035 0.058 Arginine 98 93 95 0.070 0.106 0.099 0.085 Aspartic Acid 101 54 146 0.147 0.110 0.179 0.081 Asparagine 67 89 156 0.161 0.083 0.191 0.091 Cysteine 70 119 119 0.149 0.050 0.117 0.128 Glutamic Acid 151 037 74 0.056 0.060 0.077 0.064 Glutamine 111 110 98 0.074 0.098 0.037 0.098 Glycine 57 75 156 0.102 0.085 0.190 0.152 Histidine 100 87 95 0.140 0.047 0.093 0.054 Isoleucine 108 160 47 0.043 0.034 0.013 0.056 Leucine 121 130 59 0.061 0.025 0.036 0.070 Lysine 114 74 101 0.055 0.115 0.072 0.095 Methionine 145 105 60 0.068 0.082 0.014 0.055 Phenylalanine 113 138 60 0.059 0.041 0.065 0.065 Proline 57 55 152 0.102 0.301 0.034 0.068 Serine 77 75 143 0.120 0.139 0.125 0.106 Threonine 83 119 96 0.086 0.108 0.065 0.079 Tryptophan 108 137 96 0.077 0.013 0.064 0.167 Tyrosine 69 147 114 0.082 0.065 0.114 0.125 Valine 106 170 50 0.062 0.048 0.028 0.053 Historia de los métodos (2) Chou-Fasman Glu, Met y Ala : fuerte tendencia a generar hélices. Val, Ile y Tyr: fuerte tendencia a generar láminas. Pro: fuerte tendencia a no formar hélices ni láminas Gly: alto grado de libertad, favorece la formación de giros
Historia de los métodos (3) Segunda generación • La principal característica de estos métodos es la utilización de ventanas de resíduos adyacentes en secuencia, incluyendo así información de contexto a la predicción. • Un gran número de algoritmos de predicción se usaron en esta generación de métodos: • Redes Neuronales Artificiales • Teoría de Grafos • Métodos basados en reglas • Estadística multivariable • … Esta innovación mejoró la predicción de estructura secundaria aumentando la fiabilidad a veces por encima del 70%.
Historia de los métodos (4) Limitaciones • Fiabilidad (predicciones 3-estados ~ 70%) • Se obtienen bajas fiabilidades para cadenas-β • La hélices y láminas predichas tienden a ser demasiado cortas. Debido a: • El número de estructuras disponibles sigue siendo demasiado pequeño para extrapolar al espacio de secuencias. Existiendo en algunos casos diferencias entre cristales para la misma secuencia. • NO se tienen en cuenta los efectos provocados por resíduos situados a grandes distancias en secuencia (pero no en el espacio)
Historia de los métodos (5) Tercera generación Iniciada por Levin en 1993 (~69%) y Rost y Sander en 1994 (PHD 72%) • La principal innovación de esta tercera generación es la inclusión de información evolutiva adicional en forma de alineamientos múltiples (Levin, 1993). • Además, se resuelve el sesgo en las predicciones de cadenas-β balanceando el conjunto de entrenamiento (dado que las estructuras contienen más hélices que láminas; Rost y Sander, 1994) Red neuronal PHD Información de secuencia de la familia de la proteína Perfil derivado del alineamiento múltiple para una ventana de resíduos adyacente. Rost et al. (1997) J. Mol. Biol. 270: 471-480
Historia (6) y Fiabilidad • Varios métodos han seguido estrategias similares a PHD, mejorando sus resultados a través del prefiltrado de los alineamientos de entrada y la extensión de los perfiles mediante PSIBLAST introducido por David Jones en la primera versión de PSIPRED (1999) con fiabilidades próximas al 77% o mediante HMMs usados por Kevin Karplus et al. en SAMT99sec (1999). • Otros métodos siguen una estrategia diferentes, buscando el consenso de diferentes métodos, como es el caso de Jpred2 (Cuff y Barton, 2000). Métodos de Primera generación: • Chou & Fasman, Lim, GORI Métodos de Segunda generación: • Schneider, ALB, GORIII Métodos de Tercera generación: • LPAG, COMBINE, S83, NSSP, PHD Y la fiabilidad ?
Statistics 57% 63%/66% GOR1/GOR3 (1978/1987) 70% DSC (1996) Nearest neighbour methods PREDATOR (1996) 75% NNSSP (1995) 72% Neural Networks Methods 74% PHD (1993) 75.7% PsiPRED (1999) 73% ? JNET (1999) Hidden Markov Models ~76% SAM-T99/SAM-T02 (1999/2002) Fiabilidad Métodos basados en secuencias Accuracy Chow-Fassman (1974) Structure based
Problemas y Limitaciones IMPORTANTE: la fiabilidad sigue dependiendo del número de homólogos !! Fiabilidad de PHD usando un conjunto de proteínas de prueba • NO se tienen en cuenta los efectos provocados por resíduos situados a grandes distancias en secuencia (pero no en el espacio) • Las proteínas con características inusuales deben tratarse con cuidado • Las predicciones siguen cosiderando sólo tres estados • Los malos alineamientos producen malas predicciones
Estructura Secundaria Desorden structural Accesibilidad al solvente Elementos transmembrana Otras características 1D Metodología: Implementación de un predictor SUMARIO Definición de características 1D Estructuras de proteínas Predicción de características 1D Predicción de características 1D
Desorden Estructural Algunas regiones de las secuencias no pueden clasificarse en ninguno de los tipos de estructura secundaria Estas regiones normalmente no son visibles en los cristales y están desordenadas. Las regiones desordenadas son rizos, caracterizados normalmente por elevados niveles de aminoácidos polares junto con bajos de aromáticos o regiones de baja complejidad. Algunas regiones desordenadas cortas, sin importancia funcional aparente, suelen hallarse en los extremos de las cadenas proteicas.
Desorden Estructural Las regiones más largas suelen estar conservadas en posición a lo largo de familias de proteínas. Estas regiones se relacionan con conexión entre dominios, sitios proteolíticos, así como con reconocimiento y unión tanto a ligandos como a otras proteínas. Suelen encontranse en ciertas enzimas, como en aquellas involucradas en el crecimiento y división celular o en fosforilación proteica. Entre ellas estas proteínas se hallan factores y reguladores de transcripción y kinasas entre otras. Ejemplo de proteína desordenada el factor de crecimiento nervioso β (PDB: 1bet), que sólo es estable como dímero
Evaluación de los métodos The CASP experiment ...
Estructura Secundaria Desorden structural Accesibilidad al solvente Elementos transmembrana Otras características 1D Metodología: Implementación de un predictor SUMARIO Definición de características 1D Estructuras de proteínas Predicción de características 1D
Accesibilidad al solvente • Al igual que con las predicciones de estructura secundaria, se puede estudiar la plausibilidad de las estructuras predichas por un método dado mediante el uso de la información de accesibilidad al solvente. • Además esta infomación puede ser de utilidad en otros ámbitos, como la predicción de superficies de interacción entre proteínas o de sitios funcionales. Roßbach et al. BMC Structural Biology 2005 5:7 La mayoría de los métodos reducen el problema a la predicción de dos estados Oculto: acc. Relativa < 16% Expuesto: acc. relativa >= 16%
Accesibilidad al solvente Aunque la accesibilidad es una función de la hidrofobicidad, los métodos basados en perfiles de esta propiedad producen unas predicciones pobres. La predicción de accesibilidad mejora por el uso de ventanas en secuencia. Al igual que ocurre con la estructura secundaria, la accesibilidad al solvente es una propiedad sujeta a fuertes restricciones evolutivas, por lo que su predicción se beneficia del uso de alineamientos múltiples. PHDacc y PROFacc (B. Rost) emplean redes neuronales e infomación de alineamientos múltiples. Son los únicos métodos que predicen valores reales para accesibilidades relativas. JPred2 usa perfiles de PSIBLAST como entrada para sus redes neuronales y devuelve predicciones del tipo oculto/expuesto. Estos métodos tienen una porcentaje de acierto del 70-75%
Estructura Secundaria Desorden structural Accesibilidad al solvente Elementos transmembrana Otras características 1D Metodología: Implementación de un predictor SUMARIO Definición de características 1D Estructuras de proteínas Predicción de características 1D
TMS Ejemplos de elementos transmembrana (TMS) Se estima que un ~ 25/30% del proteoma contiene elementos transmembrana. Si se considera elementos como los péptidos señal, las predicciones indican que el ~ 12% de los genes codifican para los mismos.
Y ¿En el PDB? PDBTM Fuente: http://pdbtm.enzim.hu/?m=stat
¿Cuál es el problema? La obtención de estructuras tridimensionales de proteínas transmembrana es un gran problema, ya que raramente producen cristales y su estudio por NMR es muy complicado. De hecho aún no es posible una predicción de estructuras transmembrana a nivel atómico, aunque se han hecho algunos avances al respecto. Hernanz-Falcon P, Rodriguez-Frade JM, Serrano A, Juan D, del Sol A, Soriano SF, Roncal F, Gomez L, Valencia A, Martinez-A C, Mellado M. Nat Immunol. 2004 Feb;5(2):216-23.
Predicción de topología TM Las mismas restricciones que hacen que obtener cristales de las TMP sea complicado, nos permite pre-fijar unas reglas para predecir segmentos TM, sobretodo hélices. Las regiones de conexión entre hélices del interior del citoplasma tienen una carga positiva mayor que las del exterior. Las hélices transmembrana tienden a tener una logitud de 20-30 resíduos con una hidrofobidad total alta.
Problemas ... Region extracelular Region transmembrana Region citoplasmatica
MEMSAT3 - http://bioinf.cs.ucl.ac.uk/psipred/ Algoritmo de programación dinámica que hace predicciones basadas en tablas estadísticas compiladas de los datos de proteínas de membrana. TopPred2 - http://mobyle.pasteur.fr/cgi-bin/portal.py?#forms::toppred Promedia los valores de hidropatía con una ventana trapezoidal HMMTOP - http://www.enzim.hu/hmmtop/ Se definen 5 estados estructurales y mediante HMMs para generar fragmentos de secuencia que maximizen la frecuencia de cada estado. PHDhtm - http://www.predictprotein.org/ Combina redes neuronales, alineamientos múltiples y programación dinámica (proporciona un índice de fiabilidad). TOPCONS - http://topcons.cbr.su.se/ Es un consenso de varios métodos creados por el grupo de Viklund y Elofsson, todos disponibles por separado (Phobius). TMHMM v2.0- http://www.cbs.dtu.dk/services/TMHMM/ Métodos estadísticos y HMMs que ayudan a mejorar la localización y orientación de hélices trans-membrana. Algunos predictores de TMH
Fiabilidad Los métodos actuales dicen identificar correctamente > 90% de los segmentos trasmembrana y predecir correctamente la topología en > 80% de los casos. Sin embargo, el pequeño tamaño de los conjuntos de entrenamiento (hay poco menos que de 500 estructuras no redundantes conocidas) hacen estas estimaciones poco fiables (¿~70%?) Se sabe que todos los métodos tienden a sobrepredecir proteínas globulares.
Hay predictores de TMB Hace algunos años han aparecido algunos métodos orientados a la predicción de barriles beta en membrana externa de bacterias Gram negativas. Se basan en HMM. • PRED-TMBB • PROF-TMB La escasez de estructuras distintas disponibles (sólo 72 no redundantes …) que además se usan para entrenar los métodos, hace que resulte muy difícil evaluar la calidad de dichos métodos (75-80% pero esta sobrevalorado !!).
Péptidos Señal Es una complicación anterior a la predicción de hélices transmembranas ... Cadenas peptídicas cortas (3-60 aa) que dirigen el tranporte post-transduccional de una proteína TIPOS: • Señales N-terminal: matriz mitocondrial, retículo endoplasmático, peroxisoma • Señales C-terminal: peroxisoma, RE Transporte al núcleo (NLS) -Pro-Pro-Lys-Lys-Lys-Arg-Lys-Val- Tranporte a RE H2N-Met-Met-Ser-Phe-Val-Ser-Leu- Leu-Leu-Val-Gly-Ile-Leu-Phe- Trp- Ala-Thr-Glu-Ala-Glu-Gln- Leu-Thr-Lys-Cys-Glu-Val-Phe- Gln- Retención en RE -Lys-Asp-Glu-Leu-COOH Transporte a matriz mitocondrial H2N-Met-Leu-Ser-Leu-Arg-Gln-Ser- Ile-Arg-Phe-Phe-Lys-Pro-Ala- Thr- Arg-Thr-Leu-Cys-Ser-Ser- Arg-Tyr-Leu-Leu- Transporte a peroxisoma (PTS1) -Ser-Lys-Leu-COOH Transporte a perosisoma (PTS2) H2N-----Arg-Leu-X5-His-Leu-
Recursos Disponibles 2006 2014 Fuente: http://proline.bic.nus.edu.sg/spdb/stats.html Servidores de predicción: PSORT– predicción de péptidos señal y sitios de localización TargetP– predicción de localización subcelular SignalP– predicción de péptido señal
Estructura Secundaria Desorden structural Accesibilidad al solvente Elementos transmembrana Otras características 1D Metodología: Implementación de un predictor SUMARIO Definición de características 1D Estructuras de proteínas Predicción de características 1D
Otros predictores ... Enlace de interés http://bioinformatics.ca/links_directory/category/protein ChloroP– predicción de péptidos de cloroplasto NetOGlyc– predicción de sitios de O-glicosilación en proteínas de mamífero Big-PI– prediccíon de sitios de modificación por glycosil-phosphatidyl inositol(GPI) DGPI– predicciónde sitios de anclaje y rotura para proteínas modificadas por GPI NetPhos– predicción de sitios de fosforilación (Ser, Thr, Tyr) en eucariotas NetPicoRNA- prediction of cleavage sites for proteases in the picornavirus NMT– predicción de N-miristoilacion en N-terminales Sulfinator– predicción de sitios de sulfatación en tirosinas
Estructura Secundaria Desorden structural Accesibilidad al solvente Elementos transmembrana Otras características 1D Metodología: Implementación de un predictor SUMARIO Definición de características 1D Estructuras de proteínas Predicción de características 1D
Implementación de un predictor 1.- Predicción de estructura secundaria 2.- Conjunto de entrenamiento: Conjunto de proteínas que contenga contenga estructuras con distintos plegamientos (alfa hélices, beta, giros, etc 3.- tipo de aminoácido, hidrofobicidad, ventana de residuos, información evolutiva, carga, etc. 1.- Definición del problema 2.- Extracción de un conjunto de entrenamiento que debe: • representativo de la realidad • ser fiable, poco ruido • estar limpio de redundancias • debe estar equilibrado 3.- Determinar de qué datos disponemos que puedan contener información sobre el problema a resolver.
Implementación de un predictor (2) 4.- Decidir qué método vamos a usar para construir el predictor (Redes Neuronales, Algoritmos genéticos, HMMs, Sistemas basados en reglas, SVM, ...). 5.- Elegir una codificación de la información asociada al problema acorde a éste y compatible con el método elegido. 5.- Todo se puede representar como un vector numérico. ej: el tipo de aminoácido es un vector de 20 dígitos (0,1) donde cada posición representa un tipo.
Implementación de un predictor (3) 6.- Entrenar el sistema, es decir introducir la información sobre el problema, hasta que el método establezca una relación (normalmente compleja e imperfecta) entre ella y la solución del problema. 7.- Comprobar el éxito del predictor generado frente a un conjunto de validación independiente de él de entrenamiento. 6.- La red neuronal se construye acorde con los datos de entrenamiento. Nos valemos de la teoría de aprendizaje automático para alcanzar el aprendizaje óptimo. 7.- El conjunto de validación es de similares características al de entrenamiento, sin embargo el conjunto de datos es distinto.
Fin • Tengo que dar las gracias a: • Gonzalo Lopez por muchas figuras y información • Michael Tress, por lo mismo y por la confianza; • A todo el labo por la ayuda y las sugerencia …. Y por supuesto a vosotros por vuestra atención (espero … ) PREGUNTAS ??