Download

1 / 59
600 likes | 927 Views
Probabilistic Context Free Grammar. Language structure is not linear. The velocity of seismic waves rises to…. Context free grammars – a reminder. A CFG G consists of - A set of terminals {w k }, k=1, …, V A set of nonterminals {N i }, i=1, …, n A designated start symbol, N 1

E N D
Language structure is not linear The velocity of seismic waves rises to…
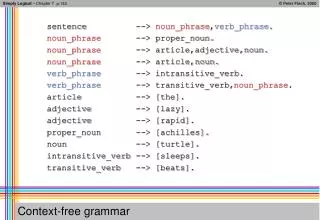
Context free grammars – a reminder • A CFG G consists of - • A set of terminals {wk}, k=1, …, V • A set of nonterminals {Ni}, i=1, …, n • A designated start symbol, N1 • A set of rules, {Niπj} (where πj is a sequence of terminals and nonterminals)
A very simple example • G’s rewrite rules – • SaSb • Sab • Possible derivations – • SaSbaabb • SaSbaaSbbaaabbb • In general, G creates the language anbn
Modeling natural language • G is given by the rewrite rules – • SNP VP • NPthe N | a N • Nman | boy | dog • VPV NP • Vsaw | heard | sensed | sniffed
Recursion can be included • G is given by the rewrite rules – • SNP VP • NPthe N | a N • Nman CP | boy CP | dog CP • VPV NP • Vsaw | heard | sensed | sniffed • CPthat VP | ε
Probabilistic Context Free Grammars • A PCFG G consists of – • A set of terminals {wk}, k=1, …, V • A set of nonterminals {Ni}, i=1, …, n • A designated start symbol, N1 • A set of rules, {Niπj} (where πj is a sequence of terminals and nonterminals) • A corresponding set of probabilities on rules
astronomers saw stars with ears • P(t1) = 0.0009072
astronomers saw stars with ears • P(t2) = 0.0006804 • P(w15) = P(t1)+P(t2) = 0.0015876
Training PCFGs • Given a corpus, it’s possible to estimate rule probabilities to maximize its likelihood • This is regarded a form of ‘grammar induction’ • However the rules of the grammar must be pre-given
Questions for PCFGs • What is the probability of a sentence w1n given a grammar G – P(w1n|G)? • Calculated using dynamic programming • What is the most likely parse for a given sentence – argmaxtP(t|w1n, G) • Likewise • How can we choose rule probabilities for the grammar G that maximize the probability of a given corpus? • The inside-outside algorithm
Chomsky Normal Form • We will be dealing only with PCFGs of the above-mentioned form • That means that there are exactly two types of rules – • NiNjNk • Niwj
Estimating string probability • Define ‘inside probabilities’ – • We would like to calculate • A dynamic programming algorithm • Base step
Estimating string probability • Induction step
Drawbacks of PCFGs • Do not factor in lexical co-occurrence • Rewrite rules must be pre-given according to human intuitions • The ATIS-CFG fiasco • The capacity of PCFG to determine the most likely parse is very limited • As grammars grow larger, they become increasingly ambiguous • The following sentences look the same to a PCFG, although suggest different parses • I saw the boat with the telescope • I saw the man with the scar
PCFGs – some more drawbacks • Have some inappropriate biases • In general, the probability of a smaller tree will be larger than a larger one • Most frequent length for Wall Street Journal sentences is around 23 words • Training is slow and problematic • Converges to a local optimum • Non-terminals do not always resemble true syntactic classes
PCFGs and language models • Because they ignore lexical co-occurrence, PCFGs are not good as language models • However, some work has been done on combining PCFGs with n-gram models • PCFGs modeled long-range syntactic constraints • Performance generally improved
Is natural language a CFG? • There is an on-going debate on the CFG’ness of English • There are some languages that can be shown to be more complex than CFGs • For example, Dutch –
Dutch oddities Dat Jan MariePieterArabischlaatzienschrijven THAT JAN MARIE PIETER ARABIC LET SEE WRITE “that Jan Let Marie see Pieter write Arabic” However, from a purely syntactic view point, this is just – dat PnVn
Other languages • Bambara (Malinese language) has non-CF features, in the form of – AnBmCnDm • Swiss-German as well • However, CFGs seem to be a good approximation for most phenomena in most languages
Grammar Induction With ADIOS (“Automatic DIstillation Of Structure”)
Previous work • Probabilistic Context Free Grammars • ‘Supervised’ induction methods • Little work on raw data • Mostly work on artificial CFGs • Clustering
Our goal • Given a corpus of raw text separated into sentences, we want to derive a specification of the underlying grammar • This means we want to be able to • Create new unseen grammatically correct sentences • Accept new unseen grammatically correct sentences and reject ungrammatical ones
What do we need to do? • G is given by the rewrite rules – • SNP VP • NPthe N | a N • Nman | boy | dog • VPV NP • Vsaw | heard | sensed | sniffed
ADIOS in outline • Composed of three main elements • A representational data structure • A segmentation criterion (MEX) • A generalization ability • We will consider each of these in turn
cat ? node edge where (1) 101 (2) (5) 104 (6) (1) 101 (2) BEGIN is (1) (2) 102 END (6) (5) 104 103 (2) (7) 103 (3) and (1) (6) 104 (4) (3) 102 (4) the (5) 102 101 (3) that a (3) (4) (6) horse (5) (4) dog The Model: Graph representation with words as vertices and sentences as paths. And is that a horse? Is that a dog? Where is the dog? Is that a cat?
ADIOS in outline • Composed of three main elements • A representational data structure • A segmentation criterion (MEX) • A generalization ability
Toy problem – Alice in Wonderland a l i c e w a s b e g i n n i n g t o g e t v e r y t i r e d o f s i t t i n g b y h e r s i s t e r o n t h e b a n k a n d o f h a v i n g n o t h i n g t o d o o n c e o r t w i c e s h e h a d p e e p e d i n t o t h e b o o k h e r s i s t e r w a s r e a d i n g b u t i t h a d n o p i c t u r e s o r c o n v e r s a t i o n s i n i t a n d w h a t i s t h e u s e o f a b o o k t h o u g h t a l i c e w i t h o u t p i c t u r e s o r c o n v e r s a t i o n
Detecting significant patterns • Identifying patterns becomes easier on a graph • Sub-paths are automatically aligned
The Markov Matrix • The top right triangle defines the PL probabilities, bottom left triangle the PR probabilities • Matrix is path-dependent
Rewiring the graph Once a pattern is identified as significant, the sub-paths it subsumes are merged into a new vertex and the graph is rewired accordingly. Repeating this process, leads to the formation of complex, hierarchically structured patterns.
Weight Occurrences Length Weight Occurrences Length conversation 0 . 98 11 11 whiterabbit 1 . 00 22 10 caterpillar 1 . 00 28 10 curious 1 . 00 19 6 interrupted 0 . 94 7 10 hadbeen 1 . 00 17 6 procession 0 . 93 6 9 however 1 . 00 20 6 mockturtle 0 . 91 56 9 perhaps 1 . 00 16 6 beautiful 1 . 00 16 8 hastily 1 . 00 16 6 important 0 . 99 11 8 herself 1 . 00 78 6 continued 0 . 98 9 8 footman 1 . 00 14 6 different 0 . 98 9 8 suppose 1 . 00 12 6 atanyrate 0 . 94 7 8 silence 0 . 99 14 6 difficult 0 . 94 7 8 witness 0 . 99 10 6 surprise 0 . 99 10 7 gryphon 0 . 97 54 6 appeared 0 . 97 10 7 serpent 0 . 97 11 6 mushroom 0 . 97 8 7 angrily 0 . 97 8 6 thistime 0 . 95 19 7 croquet 0 . 97 8 6 suddenly 0 . 94 13 7 venture 0 . 95 12 6 business 0 . 94 7 7 forsome 0 . 95 12 6 nonsense 0 . 94 7 7 timidly 0 . 95 9 6 morethan 0 . 94 6 7 whisper 0 . 95 9 6 remember 0 . 92 20 7 rabbit 1 . 00 27 5 consider 0 . 91 10 7 course 1 . 00 25 5 eplied 1 . 00 22 5 seemed 1 . 00 26 5 remark 1 . 00 28 5 ALICE motifs
ADIOS in outline • Composed of three main elements • A representational data structure • A segmentation criterion (MEX) • A generalization ability
Determining L • Involves a tradeoff • Larger L will demand more context sensitivity in the inference • Will hamper generalization • Smaller L will detect more patterns • But many might be spurious
The ADIOS algorithm • Initialization – load all data into a pseudograph • Until no more patterns are found • For each path P • Create generalized search paths from P • Detect significant patterns using MEX • If found, add best new pattern and equivalence classes and rewire the graph
The Model: The training process 987 234 132 120 567 621 321 2000 132 120 567 621 321 987 234 1203 321 987 234 1203 321 234 1203 321 987 1204 987 234 2001 987 1204 1205
987 234 132 120 567 621 321 2000 132 120 567 621 1203 1203 321 321 1204 2001 987 1204 1205
1205 1204 987 2001 321 1203 321 621 567 120 132 2000 621 567 120 132 234 987 321
Evaluating performance • In principle, we would like to compare ADIOS-generated parse-trees with the true parse-trees for given sentences • Alas, the ‘true parse-trees’ are subject to opinion • Some approaches don’t even suppose parse trees
Evaluating performance • Define • Recall – the probability of ADIOS recognizing an unseen grammatical sentence • Precision – the proportion of grammatical ADIOS productions • Recall can be assessed by leaving out some of the training corpus • Precision is trickier • Unless we’re learning a known CFG
The ATIS experiments • ATIS-NL is a 13,043 sentence corpus of natural language • Transcribed phone calls to an airline reservation service • ADIOS was trained on 12,700 sentences of ATIS-NL • The remaining 343 sentences were used to assess recall • Precision was determined with the help of 8 graduate students from Cornell University