Download

1 / 20
200 likes | 380 Views
Flow Network Models for Sub-Sentential Alignment . Ying Zhang (Joy) Advisor: Ralf Brown Dec 18 th , 2001. Background. Sub-sentential alignment problem Given a bilingual parallel sentence pair, to find the correspondence between source words and target words

E N D
Flow Network Models for Sub-Sentential Alignment Ying Zhang (Joy) Advisor: Ralf Brown Dec 18th, 2001
Background • Sub-sentential alignment problem • Given a bilingual parallel sentence pair, to find the correspondence between source words and target words • One of the major issues in Data-Driven MT (SMT/EBMT) • Some approaches • IBM Model 1 • Smooth Injective Map Recognizer [I. Dan Melamed] Language Technologies Institute School of Computer Sciences Carnegie Mellon University
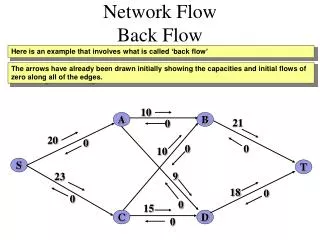
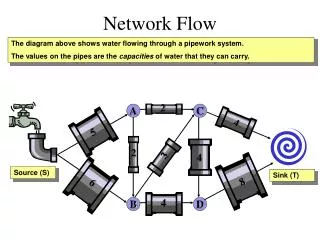
Flow Network • A well-studied area since 1950’s • Used widely in electrical engineering, computer science, social science and economic problems • Any system involving a binary relation can be represented by a network Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Flow Network [Jensen] Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Minimum Cost Flow • One of the basic problems in flow network theory • For a network G= (V,E), Total cost = • Minimum cost problem: given a network, assign the flow for each arc, so that the total cost of the network is minimum Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Alignment as a Flow Network The “abstract concepts” are transformed through this network Flow>=1, if there is alignment between two words, Flow =0. O/W Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Alignment as a Mini-cost Flow Network • Assume the alignment probabilities only lies in the possibilities of words across languages. (Alignments between other words do not have impact on this pair), then • For word pair (si,tj), assign the cost for the arc as -lnp(si,tj), then the mini-cost flow network corresponds to the maximum P(a,s,t) Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Pure Mini-Cost Flow Algorithm • Primal simplex algorithm Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Pure Mini-cost Flow Algorithm (Cont.) [Jensen] Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Pure Mini-cost Flow Algorithm (Cont.) • Two phase algorithm [Jensen] Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Our Model Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Solve the Network – Phase 1 • Phase 1: to get the basis solution (solved on paper) BridgeArc Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Solve the Network – Phase 2 • If not optimal: • Using bridgeArc to calculate the dual values of tgt nodes • If the minimal dual values of arcs in n_0 < 0 Then make this arc to be the new bridge arc; Insert the previous bridgeArc to n_0; • Else If all dual values in n_0 >0 If min(dual values of n_0) < max(dual values of n_1) make this n_1 arc to be the new bridge arc; insert the previous bridgeArc to n_1; Else optimal, stop Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Update the Cost by E.M. • Each sentence pair is represented by a network • After the network is solved, update the counts and probability contribution of the word pairs in the solved network • Update the probability of word association between source and target language • Using Good-Turing smoothing • Does not work very well so far! –High frequency words Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Model Training • Sentence level aligned bilingual corpus (hknews) • Stemmed by Porter stemmer • Building a seed statistical dictionary using Ralf’s method [Brown97] • Combined with the Chinese-English glossary to get a seed dictionary (coverage != 100%) • Solve the network and update the probability until the total cost of the corpus converge Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Performance & Results • Fast (align 10,000 sentence pairs in 2 minutes*) • * words in sentence <=25 • * system ran on PC with 128 RAM • Using only the seed dictionary, tested on 30 sentence pairs: • Recall: 53%~61% • (because of the coverage of the seed dictionary) • Precision: 74%~76% • Expected to achieve a higher recall when E.M. works properly Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Future Work • Currently, the model is no more powerful than IBM model1 • We are planning to integrate the monolingual co-occurrence probability and the bilingual association probability into the model Language Technologies Institute School of Computer Sciences Carnegie Mellon University
References • Éric Gaussier, “Flow Network Models for Word Alignment and Terminology Extraction from Bilingual Corpora”, Proceedings of the 36th Annual Meeting of the association for Computational Linguistics and the 17th International Conference on Computational Linguistics, COLING-ACL'98. Montreal, Canada • Paul A. Jensen and Jonathan F. Bard, “Operations Research Models and Methods”, http://www.me.utexas.edu/~jensen/ORMM/index.html • Ralf D. Brown, "Automated Dictionary Extraction for ``Knowledge-Free'' Example-Based Translation". In Proceedings of the Seventh International Conference on Theoretical and Methodological Issues in Machine Translation, p. 111-118. Santa Fe, July 23-25, 1997. Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Acknowledgement • Many thanks to Jian Zhang, Katharina Probst, and Alicia Tribble for their help ! Language Technologies Institute School of Computer Sciences Carnegie Mellon University
Questions and Comments? Language Technologies Institute School of Computer Sciences Carnegie Mellon University