Download

1 / 72
720 likes | 733 Views
This article discusses the principle of locality of program behavior and its impact on cache memory. It explains the different types of locality (temporal, spatial, and sequentiality) and how memory hierarchy is implemented to take advantage of this principle. The article also covers basic notions of cache performance, cache organization, and the different types of cache mappings (direct mapped and set associative).

E N D
Cache Memory Caches work on the principle of locality of program behaviour. This principle states that programs access a relatively small portion of their address space at any instant of time. There are three different types of locality.
Temporal Locality References tend to repeat. If an item is referenced then it will tend to be referenced soon again. If a sequence of references X1, X2, X3, X4 have recently been made then it is likely that the next reference will be one of X1, X2, X3, X4
Spatial Locality If an item is referenced then there is high probability that items whose addresses are close by will be referenced soon References tend to cluster into distinct regions ( working Sets)
Sequentiality It is a restricted type of spatial locality and can be called a subset of it. It states that given a reference been made to a particular location ‘S’ then there is high probability that with in the next several references a reference to location ‘S+1’ will be made.
Locality in Programs • Locality in programs arise from simple and natural program structures . • For example ‘Loops’ – where instructions and data are normally accessed sequentially. • Instructions are normally accessed sequentially. • Some data accesses like elements of an array show high degree of spatial locality.
Memory Hierarchy • Taking advantage of this principle of locality of program behavior , The memory of computer is implemented as memory hierarchy. • It consists of multiple levels of memory with different access speeds and sizes • The faster memory levels have high cost of per bit storage, so they tend to be smaller in size
Memory Hierarchy • This implementation helps in creating an illusion for the user that he can access as much memory as available in cheapest technology, while getting the access times of faster memory.
Basic Notions HIT: Processor references that are found in the cache are called ‘Cache Hits’. Cache Miss: Processor references not found in cache are called ‘cache miss’. On a cache miss the cache control mechanism must fetch the missing data from main memory and place it in the cache. Usually the cache fetches a spatial locality (Set of contiguous words) called ‘Line’ from memory
Basic Notions Hit Rate: Fraction of memory references found in cache. References found in cache / Total memory References. Miss Rate: ( 1-Hit Rate) Fraction of memory references not found in cache. Hit Time: Time to service memory references found in cache( Including the time to determine Hit or Miss.
Basic Notions Miss Penalty: Time required to fetch a block into a level of memory hierarchy from a lower level . This includes time to access the block, transmit it across to higher level, and insert it in level that experienced the miss The primary measure of cache performance is Miss Rate. In most processor designs the CPU stalls or ceases activity on cache Miss.
Processor cache Interface It can be characterized by a number of parameters. • Access Time for a reference found in cache (A Hit)- Depends on cache size and organisation. • Access Time for a reference not found in cache (A Miss) – Depends on memory organisation.
Processor cache Interface • Time to compute a real address from a virtual address ( Not in TLB time)- Depends on address translation facility. From cache’s point of view the processor behavior that affects design is • No of requests or references per cycle • The physical word size or the transfer unit between CPU and Cache.
Cache Organization • The cache is organized as a directory to locate the data item and a data array to hold the data item • Cache can be organized to fetch on demand or to prefetch data. • Fetch on demand ( Most common) brings a new line to cache only when a processor reference is not found in current cache contents. (A cache Miss).
Cache Organization There are three basic types of cache organisations. • Direct Mapped • Set associative Mapped • Fully associative Mapped
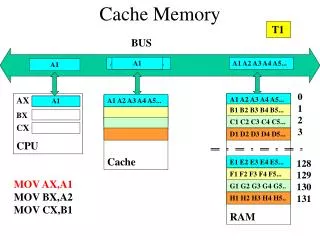
Direct Mapped Cache • In this organization each memory location is mapped to exactly one location in the cache. • Cache Directory consists of number of lines (entries) with each line containing a number of contiguous words. • The Cache Directory is Indexed by lower order bits and higher order bits are stored as Tag Bits.
Direct Mapped Cache The 24 bit real address is partitioned into following for cache usage. Tag (10 Bits) Index (8 Bits) W/L (3 Bits) B/W (3 Bits) • A 16 KB Cache having a line of 8 words of 8 bytes each. • Total 256 ( 16KB/64 ) Lines or Entries in cache Directory. • Total 10 bits of Tag (Higher order bits) to differentiate various addresses mapping to same line number.
Direct Mapped Cache TLB 10 8 3 3 Tag Bits Index Bits W/L B/w 8 B Data Array 2K X 8 B Dirty Bit Valid Bit Ref Bit 2K 10 Tag Bits COMP To Processor
Set Associative Cache • The set associative cache operates in a fashion similar to direct mapped cache. • Here we have more than one choice to locate the line. • If there are ‘n‘ such locations the cache is said to be n way set associative. • Each Line in memory maps to a unique Setin cache and it can be placed in any element of the set.
Set Associative Cache • This improves locality ( Hit Rate ) since now line may lie in more than one location. Going from one way to two way decreases miss rate by 15 % • The reference address bits are compared with all the entries in the set to find a match. • If there is a hit, then that particular sub cache array is selected and outgated to processor.
Set Associative Cache Disadvantages: • Requires more comparators and stores more tag bits per block • Additional compares and multiplexing increases cache access time
Set Associative Cache 11 7 3 3 Tag Bits Index Bits W/L B/w Data Array 1K x 8B Valid Bit Dirty Bit Ref Bit Set 1 1K x 8B Set 2 11 Tag Bits 11 Tag Bits MUX
Fully Associative Cache • It’s the extreme case of Set associative mapping. • In this mapping Line can be stored in any of the directory entries. • Referenced address is compared to all the entries in the directory. (High H/W Cost) • If a match is found the corresponding location is fetched and returned to processor. • Suitable for small caches only.
Fully Associative Mapped Cache TLB 10 8 3 3 Tag Bits W/L B/w 8 B Data Array 2K X 8 B Dirty Bit Valid Bit Ref Bit 2K 18Tag Bits To Processor
Write Policies • There are two strategies to update the memory on a write. • The Write through cache stores both into cache and main memory on each write. • In Copy back cache write is done in cache only and Dirty bit is set. Entire line is stored in main memory on replacement. (If dirty bit is set)
Write Though • A write is directed at both the cache and main memory for every CPU store. • Advantage of maintaining a consistent image in main memory. • Disadvantage of increasing memory traffic in case of large caches.
Copy Back • A write is directed only at cache on CPU store, and dirty bit is set. • The entire line is replaced in main memory only when this line is replaced with another line. • When a read miss occurs in cache, the old line is simply discarded if dirty bit is not set, else old line is first written out and then new line is accessed and written to cache.
Write Allocate • If a cache miss occurs in Store write, the new line can be Allocated to the cache and the store write can then be performed in cache. • This policy of “Write allocate” is generally used with copy back caches • Copy back caches result in lower memory traffic with large caches.
No Write Allocate • If a cache miss occurs in Store write, then cache may be bypassed and write is performed in main memory only. • This policy of “No write allocate “ is generally used with write through caches. • So we have two types of caches. • CBWA – copy back write allocate • WTNWA – write through no write allocate.
Line Replacement Strategies • If the reference is not found in the directory, a cache miss occurs. • This requires two actions to be taken promptly • The line having missed reference must be fetched from the main memory. • One of the current line must be designated for replacement by the new line
Fetching a Line • In a write through cache, concern is only accessing the new line. The replaced line is simply discarded ( Written Over). • In copy back cache , we must first determine if line to be replaced is dirty. If the line is clean it can be written over, otherwise it should first be written back to memory. • A write buffer can speed up the process.
Fetching a Line • The access of the line can begin at the start of the line or at the faulted word. • The second approach is called fetch bypass or wraparound load. • This can minimize miss time penalty as CPU can resume processing while the rest of line is being loaded in the cache. • This can result in contention for cache as both CPU and memory may need cache simultaneously
Fetching a Line • Potentially fastest approach is Non blocking or prefetching cache. • This cache has additional control hardware to handle cache miss while the processor continues to execute. • This strategy works when miss is handling data not currently required by the processor. • So this can work with compilers that provide adequate prefetching of lines in anticipation.
Line Replacement • There are three replacement policies that determine which line to replace on cache miss. • Least Recently Used (LRU) • First in First Out (FIFO) • Random Replacement (Rand) The LRU is generally regarded as the ideal policy as it closely corresponds to concept of temporal locality. But it involve additional h/w control and complexity.
Effects of writes on Memory Traffic An integrated cache with two references per instruction (One I reference, one D reference) has following details. The data references are divided 68% Reads, 32 % writes. 30% Dirty Lines 8B Physical Word 64 B Line 5% Read Miss Rate Compute the memory traffic for a 5 % miss rate for both types of caches.
Warm Caches • In the multi programmed environment , control passes back to a task that once resided in the cache. • If a cache retains a significant portion of working set from a previous execution its said to be a warm cache • Caches that have no history from prior executions are called a cold cache
Common Types of Cache • Integrated or Unified cache • Split cache I and D. • Sectored Cache • Two Level cache • Write assembly Cache
Split I & D Caches • Separate Instruction and data caches offer the possibility of significantly increased cache bandwidth ( almost twice ) • This comes at some sacrifice of increased miss rate for same size of unified cache. • Caches are not split equally. I caches are not required to manage a processor store. • Spatial locality is much higher in I caches so larger lines are more effective in I caches than in D caches.
Split I And D caches I Reads PROCESSOR I - Cache Invalidate if Found D writes D -Cache D Reads
Split I and D Caches • In some program environments data parameters are placed directly in the program • A program location fetched into I cache may also bring data along • When operand parameter is fetched into D cache, a duplicate line entry occurs. • Two split case policies possible for dealing with duplicate lines.
Duplicate Lines • If miss on I –ref, Line goes to I – cache. • If miss on D – ref, Line goes to D – cache. • On CPU store ref check both directories. - use write policy in D –Cache - Invalidate line in I - Cache
No Duplicate Lines • If miss on I –ref, Line goes to I – cache. and check D cache : invalidate if present. • If miss on D – ref, Line goes to D – cache. and check I- cache : invalidate if present. • On CPU store, difference check both directories
On Chip Caches • On Chip caches have two notable considerations. • Due to pin limitations transfer path to and from memory is usually limited. • The cache organisation must be optimized to make best use of area. So the area of directory should be small , allowing maximum area for data array. This implies large block size ( less entries) and simply organised cache with fewer bits per directory entry.
On Chip Caches • The directory overhead is inversely proportional to the line size and number of bits contained in the entry. • Cache utilization = b / b+v/8 • Where b = No of data bytes per line and v = block line overhead ( No of bits in dir entry) Larger line sizes make more of the area available for data array
Sectored Cache • Use of large blocks specially for small caches causes an increase in miss rate and specially increases Miss Time penalty ( due to large access time for large blocks) • The solution is a Sectored cache. • In a sectored cache each line is broken into transfer units (one access from cache to memory) • The Directory is organised around line size as usual.
Sectored Cache • On a cache miss the missed line is entered in the directory (Address tags etc), but only the transfer unit that is required by the processor is brought into data array. • A valid bit indicates the status of sub lines. • If a subsequent access is required in another sub line of newly loaded line, then that sub line is brought into data array. • This while maintaining temporal locality, greatly reduces the size of directory.
Two Level Caches • First level on chip cache is supported by a larger, (off or on chip) second level cache. • The two level cache improves performance by effectively lowering the first level cache access time and Miss Penalty. • A two level cache system is termed Inclusive if all the contents of lower level cache (L1) are also contained in higher level cache ( L2).
Two Level Caches • Second level cache analysis is done using the principle of inclusion. • A large second level cache includes everything in the first level cache. Thus for purpose of evaluating performance, the first level cache can be presumed not to exist and assuming that processor made all its requests to second level cache. The line size and in fact the overall size of second level cache must be significantly larger than first level cache.
Two Level Caches • For a two level cache system following Miss rates are defined. • Local Miss Rate : No of misses experienced by the cache divided by the number of incoming references • Global Miss Rate: Number of L2 misses divided by the no of references made by the processor. • Solo Miss Rate: The Miss rate the cache would have if it were the only cache in the system. The principle of inclusion specifies that global miss rate will be essentially the same as solo miss rate
Two Level Caches • True or logical inclusion where All the contents of L1 reside also in L2, have number of requirements. • L1 cache must be Write Through ( L2 may not be). • No of L2 Sets >= Number of L1 Sets • L2 associativity >= L1 associativity. Cache size = Line Size * Associativity * No of sets.
Two Level Caches • Example: a certain processor has two level cache. L1 is 4 KB direct mapped WTNWA. L2 is 8KB direct mapped CBWA. Both have 16 Byte lines with LRU replacement. • Is it always true that L2 includes all lines of L1. • If L2 is now 8KB 4 way set associative does L2 include all lines at L1. • If L1 is 4 way set associative (CBWA) and L2 is direct mapped, does L2 includes all lines of L1.