Download
1 / 15
150 likes | 160 Views
Explore the importance of sequence files in containing genetic and protein data, including their directionality and structure in biological processes.

E N D
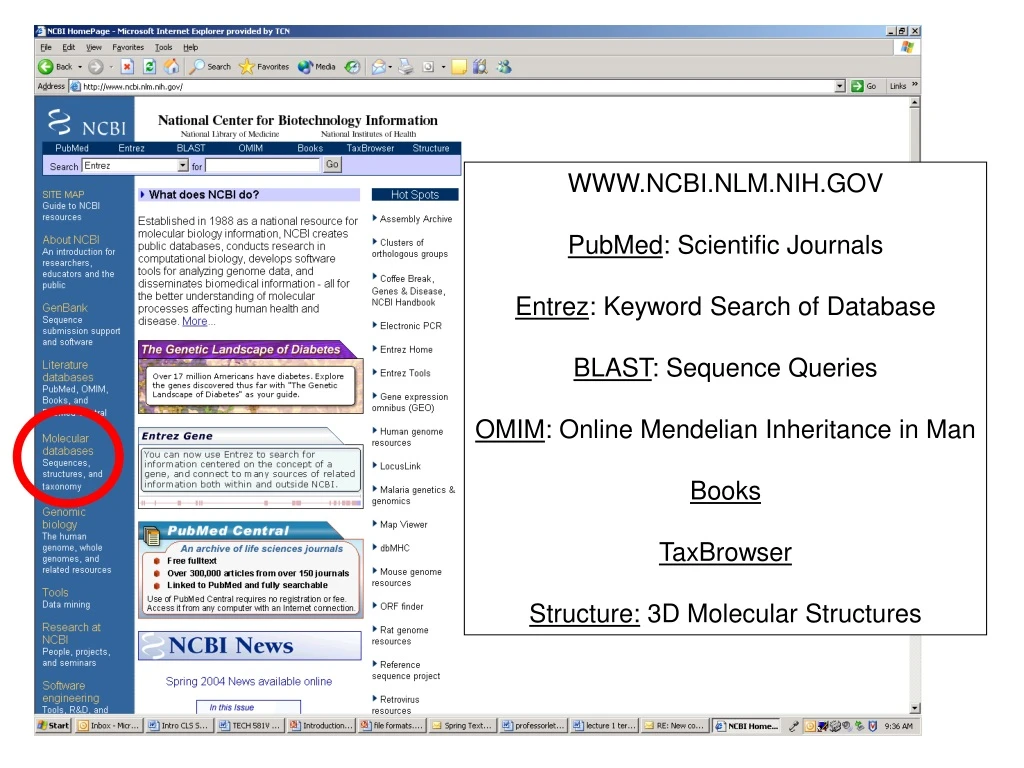
WWW.NCBI.NLM.NIH.GOV PubMed: Scientific Journals Entrez: Keyword Search of Database BLAST: Sequence Queries OMIM: Online Mendelian Inheritance in Man Books TaxBrowser Structure: 3D Molecular Structures
Sequence Files Since the information relevant to biological processes is contained in the gene or protein sequence, all genetic and protein data are contained in “sequence” files. Importantly, there is a “directionality” that exists in nature that is conserved in the sequence file; Nucleic Acids are always written 5’ to 3’ (describing the 5’ or 3’ free hydroxyl group used in the phosphodiesterase bond). nucleic acids (genes): 5’-AGCTCGTGTAGACCATTC-3’ Amino Acids are always written with the free amino (N-terminus) first and the carboxylic acid (C-terminus) last. amino acids (proteins): amino-IPKERYRGQIESIWA-carboxy
DNA is Double Stranded… Anti-parallel Configuration Top strand is ALWAYS written 5’ to 3’ When DNA is written in file, top strand is represented and bottom strand is assumed. 3’ 5’ 5’ 3’ 3’ 5’ 5’ 3’ AGTCGTGATCTGCTAAATGTCTCGAAGTTCGATGCTAG |||||||||||||||||||||||||||||||||||||| TCAGCACTAGACGATTTACAGAGCTTCAAGATACGATC Courier font is preferred for writing sequence data since letter spacing is independent of character content.
>gi|1924939|emb|X98411.1|HSMYOSIE Homo sapiens partial mRNA for myosin-IF CAGGAGAAGCTGACCAGCCGCAAGATGGACAGCCGCTGGGGCGGGCGCAGCGAGTCCATCAATGTGACCC TCAACGTGGAGCAGGCAGCCTACACCCGTGATGCCCTGGCCAAGGGGCTCTATGCCCGCCTCTTCGACTT CCTCGTGGAGGCCATCAACCGTGCTATGCAGAAACCCCAGGAAGAGTACAGCATCGGTGTGCTGGACATT TACGGCTTCGAGATCTTCCAGAAAAATGGCTTCGAGCAGTTTTGCATCAACTTCGTCAATGAGAAGCTGC AGCAAATCTTTATCGAACTTACCCTGAAGGCCGAGCAGGAGGAGTATGTGCAGGAAGGCATCCGCTGGAC TCCAATCCAGTACTTCAACAACAAGGTCGTCTGTGACCTCATCGAAAACAAGCTGAGCCCCCCAGGCATC ATGAGCGTCTTGGACGACGTGTGCGCCACCATGCACGCCACGGGCGGGGGAGCAGACCAGACACTGCTGC AGAAGCTGCAGGCGGCTGTGGGGACCCACGAGCATTTCAACAGCTGGAGCGCCGGCTTCGTCATCCACCA CTACGCTGGCAAGGTCTCCTACGACGTCAGCGGCTTCTGCGAGAGGAACCGAGACGTTCTCTTCTCCGAC CTCATAGAGCTGATGCAGTCCAGTGACCAGGCCTTCCTCCGGATGCTCTTCCCCGAGAAGCTGGATGGAG ACAAGAAGGGGCGCCCCAGCACCGCCGGCTCCAAGATCAAGAAACAAGCCAACGACCTGGTGGCCACACT GATGAGGTGCACACCCCACTACATCCGCTGCATCAAACCCAACGAGACCAAGCACGCCCGAGACTGGGAG GAGAACAGAGTCCAGCACCAGGTGGAATACCTGGGCCTGAAGGAAAACATCAGGGTGCGCAGAGCCGGCT TCGCCTACCGCCGCCAGTTCGCCAAATTCCTGCAGAGGTATGCCATTCTGACCCCCGAGACGTGGCCGCG GTGGCGTGGGGACGAACGCCAGGGCGTCCAGCACCTGCTTCGGGCGGTCAACATGGAGCCCGACCAGTAC CAGATGGGGAGCACCAAGGTCTTTGTCAAGAACCCAGAGTCGCTTTTCCTCCTGGAGGAGGTGCGAGAGC GAAAGTTCGATGGCTTTGCCCGAACCATCCAGAAGGCCTGGCGGCGCCACGTGGCTGTCCGGAAGTACGA GGAGATGCGGGAGGAAGCTTCCAACATCCTGCTGAACAAGAAGGAGCGGAGGCGCAACAGCATCAATCGG AACTTCGTCGGGGACTACCTGGGGCTGGAGGAGCGGCCCGAGCTGCGTCAGTTCCTGGGCAAGAAGGAGC GGGTGGACTTCGCCGATTCGGTCACCAAGTACGACCGCCGCTTCAAGCCCATCAAGCGGGACTTGATCCT GACGCCCAAGTGTGTGTATGTGATTGGGCGAGAGAAGATGAAGAAGGGACCTGAGAAAGGTCCAGTGTGT GAAATCTTGAAGAAGAAATTGGACATCCAGGCTCTGCGGGGGGTCTCCCTCAGCACGCGACAGGACGACT TCTTCATCCTCCAAGAGGATGCCGCCGACAGCTTCCTGGAGAGCGTCTTCAAGACCGAGTTTGTCAGCCT TCTGTGCAAGCGCTTCGAGGAGGCGACGCGGAGGCCCCTGCCCCTCACCTTCAGCGACACACTACAGTTT CGGGTGAAGAAGGAGGGCTGGGGCGGTGGCGGCACCCGCAGCGTCACCTTCTCCCGCGGCTTCGGCGACT TGGCAGTGCTCAAGGTTGGCGGTCGGACCCTCACGGTCAGCGTGGGCGATGGGCTGCCCAAGAACTCCAA GCCTACCGGAAAGGGATTGGCCAAGGGTAAACCTCGGAGGTCGTCCCAAGCCCCTACCCGGGCGGCCCCT GGCGCCCCCCAAGGCATGGATCGAAATGGGGCCCCCCTCTGCCCACAGGGGGGGGCCCCCTGCCCCCTGG AGAAATTCATTTGGCCCAGGGGGCACCCACAGGCCTCCCCGGCCCTCCGTCCACATCCCTGGGATGCCAG CAGACGACCCCGGGCACGTCCGCCCTCAGAGCACAACACAGAATTCCTCAACGTGCCTGACCAGGGGATG GCCGGCATGCAGAGGAAGCGCAGCGTGGGGCAACGGCCAGTGCCTGTGGGCCGACCCAAGCCCCAGCCTC GGACACATGGTCCCAGGTGCCGGGCCCTATACCAGTACGTGGGCCAAGATGTGGACGAGCTGAGCTTCAA CGTGAACGAGGTCATTGAGATCCTCATGGAAGATCCCTCGGGCTGGTGGAAGGGCCGGCTTCACGGCCAG GAGGGCCTTTTCCCAGGAAACTACGTGGAGAAGATCTGAGCTGGGCCCTGGGATACTGCCTTCTCTTTCG CCCGCCTATCTGCCTGCCGGCCTGGTGGGGAGCCAGGCCCTGCCAATGAAAGCCTCGTTTACCTGGGCTG CAATAGCCTAAAAGTCCAATCCTTTGGCCTCCAGTCCTTGCCCAGGCCCTGGGTCACCAGGTCACTGGTG CAGCCCCCGCCCCTGGGCCCTGGTTTTCCTCCAACATCACACCTGCTGCCCATTGTCCAAAACTGTGTGT GTCAAAGGGGACTAACAGCAGAATTTACCTCCCAACTGCCATGTGATTAAGAAATGGGTCTTGAGTCCTG TGCTGTTGGCAAAGTTCCAGGCACAGTTGGGGAGGGGGGGCCGGAATCCGC FASTA File Format
FASTA File Format • A sequence in FASTA format begins with a single-line description, followed by lines of sequence data. • 1) The description line starts with a greater than symbol (">"). • 2) The word following the greater than symbol (">") immediately is the "ID" (name) of the sequence, the rest of the line is the description. The "ID" and the description are optional. • 3) All lines of text should be shorter than 80 characters. • 4) The sequence ends if there is another greater than symbol (">") symbol at the beginning of a line and another sequence begins.
FASTA File Format The following example contains two protein sequences (Example1, Example2): >Example1 envelope protein ELRLRYCAPAGFALLKCNDADYDGFKTNCSNVSVVHCTNLMNTTVTTGLLLNGSYSENRT QIWQKHRTSNDSALILLNKHYNLTVTCKRPGNKTVLPVTIMAGLVFHSQKYNLRLRQAWC HFPSNWKGAWKEVKEEIVNLPKERYRGTNDPKRIFFQRQWGDPETANLWFNCHGEFFYCK MDWFLNYLNNLTVDADHNECKNTSGTKSGNKRAPGPCVQRTYVACHIRSVIIWLETISKK TYAPPREGHLECTSTVTGMTVELNYIPKNRTNVTLSPQIESIWAAELDRYKLVEITPIGF APTEVRRYTGGHERQKRVPFVXXXXXXXXXXXXXXXXXXXXXXVQSQHLLAGILQQQKNL LAAVEAQQQMLKLTIWGVK >Example2 synthetic peptide HITREPLKHIPKERYRGTNDTLSPQIESIWAAELDRYKLVKTNCSNVS
FASTA File Format • Sequences are expected to be represented in the standard IUB/IUPAC amino acid and nucleic acid codes, with these exceptions: • Lower-case letters are accepted and are mapped into upper-case • A single hyphen or dash can be used to represent a gap of indeterminate length • In amino acid (protein) sequences, U and * are acceptable letters. • “N” for unknown nucleic acid residue; or “X” for unknown amino acid residue. • mRNA is often listed as cDNA, and the U is replaced with T The nucleic acid codes supported are: A adenosine M A C (amino) C cytidine S G C (strong) G guanine W A T (weak) T thymidine B G T C U uridine D G A T R G A (purine) H A C T Y T C (pyrimidine) V G C A K G T (keto) N A G C T (any) “-” gap of indeterminate length
FASTA File Format For those programs that use amino acid (protein) query sequences (e.g. BLASTP and TBLASTN), the accepted amino acid codes are: A alanine P proline B aspartate Q glutamine C cystine R arginine D aspartate S serine E glutamate T threonine F phenylalanine U selenocysteine G glycine V valine H histidine W tryptophan I isoleucine Y tyrosine K lysine Z glutamine L leucine X any M methionine “*” translation stop N asparagine “-” gap of indeterminate length
>gi|1924939|emb|X98411.1|HSMYOSIE Homo sapiens partial mRNA for myosin-IF CAGGAGAAGCTGACCAGCCGCAAGATGGACAGCCGCTGGGGCGGGCGCAGCGAGTCCATCAATGTGACCC TCAACGTGGAGCAGGCAGCCTACACCCGTGATGCCCTGGCCAAGGGGCTCTATGCCCGCCTCTTCGACTT CCTCGTGGAGGCCATCAACCGTGCTATGCAGAAACCCCAGGAAGAGTACAGCATCGGTGTGCTGGACATT TACGGCTTCGAGATCTTCCAGAAAAATGGCTTCGAGCAGTTTTGCATCAACTTCGTCAATGAGAAGCTGC AGCAAATCTTTATCGAACTTACCCTGAAGGCCGAGCAGGAGGAGTATGTGCAGGAAGGCATCCGCTGGAC TCCAATCCAGTACTTCAACAACAAGGTCGTCTGTGACCTCATCGAAAACAAGCTGAGCCCCCCAGGCATC ATGAGCGTCTTGGACGACGTGTGCGCCACCATGCACGCCACGGGCGGGGGAGCAGACCAGACACTGCTGC AGAAGCTGCAGGCGGCTGTGGGGACCCACGAGCATTTCAACAGCTGGAGCGCCGGCTTCGTCATCCACCA CTACGCTGGCAAGGTCTCCTACGACGTCAGCGGCTTCTGCGAGAGGAACCGAGACGTTCTCTTCTCCGAC CTCATAGAGCTGATGCAGTCCAGTGACCAGGCCTTCCTCCGGATGCTCTTCCCCGAGAAGCTGGATGGAG ACAAGAAGGGGCGCCCCAGCACCGCCGGCTCCAAGATCAAGAAACAAGCCAACGACCTGGTGGCCACACT GATGAGGTGCACACCCCACTACATCCGCTGCATCAAACCCAACGAGACCAAGCACGCCCGAGACTGGGAG GAGAACAGAGTCCAGCACCAGGTGGAATACCTGGGCCTGAAGGAAAACATCAGGGTGCGCAGAGCCGGCT TCGCCTACCGCCGCCAGTTCGCCAAATTCCTGCAGAGGTATGCCATTCTGACCCCCGAGACGTGGCCGCG GTGGCGTGGGGACGAACGCCAGGGCGTCCAGCACCTGCTTCGGGCGGTCAACATGGAGCCCGACCAGTAC CAGATGGGGAGCACCAAGGTCTTTGTCAAGAACCCAGAGTCGCTTTTCCTCCTGGAGGAGGTGCGAGAGC GAAAGTTCGATGGCTTTGCCCGAACCATCCAGAAGGCCTGGCGGCGCCACGTGGCTGTCCGGAAGTACGA GGAGATGCGGGAGGAAGCTTCCAACATCCTGCTGAACAAGAAGGAGCGGAGGCGCAACAGCATCAATCGG AACTTCGTCGGGGACTACCTGGGGCTGGAGGAGCGGCCCGAGCTGCGTCAGTTCCTGGGCAAGAAGGAGC GGGTGGACTTCGCCGATTCGGTCACCAAGTACGACCGCCGCTTCAAGCCCATCAAGCGGGACTTGATCCT GACGCCCAAGTGTGTGTATGTGATTGGGCGAGAGAAGATGAAGAAGGGACCTGAGAAAGGTCCAGTGTGT GAAATCTTGAAGAAGAAATTGGACATCCAGGCTCTGCGGGGGGTCTCCCTCAGCACGCGACAGGACGACT TCTTCATCCTCCAAGAGGATGCCGCCGACAGCTTCCTGGAGAGCGTCTTCAAGACCGAGTTTGTCAGCCT TCTGTGCAAGCGCTTCGAGGAGGCGACGCGGAGGCCCCTGCCCCTCACCTTCAGCGACACACTACAGTTT CGGGTGAAGAAGGAGGGCTGGGGCGGTGGCGGCACCCGCAGCGTCACCTTCTCCCGCGGCTTCGGCGACT TGGCAGTGCTCAAGGTTGGCGGTCGGACCCTCACGGTCAGCGTGGGCGATGGGCTGCCCAAGAACTCCAA GCCTACCGGAAAGGGATTGGCCAAGGGTAAACCTCGGAGGTCGTCCCAAGCCCCTACCCGGGCGGCCCCT GGCGCCCCCCAAGGCATGGATCGAAATGGGGCCCCCCTCTGCCCACAGGGGGGGGCCCCCTGCCCCCTGG AGAAATTCATTTGGCCCAGGGGGCACCCACAGGCCTCCCCGGCCCTCCGTCCACATCCCTGGGATGCCAG CAGACGACCCCGGGCACGTCCGCCCTCAGAGCACAACACAGAATTCCTCAACGTGCCTGACCAGGGGATG GCCGGCATGCAGAGGAAGCGCAGCGTGGGGCAACGGCCAGTGCCTGTGGGCCGACCCAAGCCCCAGCCTC GGACACATGGTCCCAGGTGCCGGGCCCTATACCAGTACGTGGGCCAAGATGTGGACGAGCTGAGCTTCAA CGTGAACGAGGTCATTGAGATCCTCATGGAAGATCCCTCGGGCTGGTGGAAGGGCCGGCTTCACGGCCAG GAGGGCCTTTTCCCAGGAAACTACGTGGAGAAGATCTGAGCTGGGCCCTGGGATACTGCCTTCTCTTTCG CCCGCCTATCTGCCTGCCGGCCTGGTGGGGAGCCAGGCCCTGCCAATGAAAGCCTCGTTTACCTGGGCTG CAATAGCCTAAAAGTCCAATCCTTTGGCCTCCAGTCCTTGCCCAGGCCCTGGGTCACCAGGTCACTGGTG CAGCCCCCGCCCCTGGGCCCTGGTTTTCCTCCAACATCACACCTGCTGCCCATTGTCCAAAACTGTGTGT GTCAAAGGGGACTAACAGCAGAATTTACCTCCCAACTGCCATGTGATTAAGAAATGGGTCTTGAGTCCTG TGCTGTTGGCAAAGTTCCAGGCACAGTTGGGGAGGGGGGGCCGGAATCCGC FASTA File Format
>gi|1924940|emb|CAA67058.1| myosin-IF [Homo sapiens] QEKLTSRKMDSRWGGRSESINVTLNVEQAAYTRDALAKGLYARLFDFLVEAINRAMQKPQEEYSIGVLDI YGFEIFQKNGFEQFCINFVNEKLQQIFIELTLKAEQEEYVQEGIRWTPIQYFNNKVVCDLIENKLSPPGI MSVLDDVCATMHATGGGADQTLLQKLQAAVGTHEHFNSWSAGFVIHHYAGKVSYDVSGFCERNRDVLFSD LIELMQSSDQAFLRMLFPEKLDGDKKGRPSTAGSKIKKQANDLVATLMRCTPHYIRCIKPNETKHARDWE ENRVQHQVEYLGLKENIRVRRAGFAYRRQFAKFLQRYAILTPETWPRWRGDERQGVQHLLRAVNMEPDQY QMGSTKVFVKNPESLFLLEEVRERKFDGFARTIQKAWRRHVAVRKYEEMREEASNILLNKKERRRNSINR NFVGDYLGLEERPELRQFLGKKERVDFADSVTKYDRRFKPIKRDLILTPKCVYVIGREKMKKGPEKGPVC EILKKKLDIQALRGVSLSTRQDDFFILQEDAADSFLESVFKTEFVSLLCKRFEEATRRPLPLTFSDTLQF RVKKEGWGGGGTRSVTFSRGFGDLAVLKVGGRTLTVSVGDGLPKNSKPTGKGLAKGKPRRSSQAPTRAAP GAPQGMDRNGAPLCPQGGAPCPLEKFIWPRGHPQASPALRPHPWDASRRPRARPPSEHNTEFLNVPDQGM AGMQRKRSVGQRPVPVGRPKPQPRTHGPRCRALYQYVGQDVDELSFNVNEVIEILMEDPSGWWKGRLHGQ EGLFPGNYVEKI FASTA File Format <?xml version="1.0"?> <!DOCTYPE TSeq PUBLIC "-//NCBI//NCBI TSeq/EN" "http://www.ncbi.nlm.nih.gov/dtd/NCBI_TSeq.dtd"> <TSeq> <TSeq_seqtype value="nucleotide"/> <TSeq_gi>1924939</TSeq_gi> <TSeq_accver>X98411.1</TSeq_accver> <TSeq_taxid>9606</TSeq_taxid> <TSeq_orgname>Homo sapiens</TSeq_orgname> <TSeq_defline>Homo sapiens partial mRNA for myosin-IF</TSeq_defline> <TSeq_length>2711</TSeq_length> <TSeq_sequence>CAGGAGAAGCTGACCAGCCGCAAGATGGACAGCCGCTGGGGCGGGCGCAGCGAGTCCATCAATGT…… </TSeq> TinySeq XML
FASTA File Format…(note: U = T) >gi|1234|my name from genetic code in DNA ATGATTTGTCACGCTGAGCTC-AAAGCT AACGAGTAA >gi|1234|my name translated into protein MICHAEL-KANE* A alanine P proline B aspartate Q glutamine C cystine R arginine D aspartate S serine E glutamate T threonine F phenylalanine U selenocysteine G glycine V valine H histidine W tryptophan I isoleucine Y tyrosine K lysine Z glutamine L leucine X any M methionine “*” translation stop N asparagine “-” gap of indeterminate length
Where do we get DNA sequence information? DNA Sequencing Methods -conversion of biological/bioanalytical data into sequence information There are automated, high-throughput sequencing centers that COMPLETELY automate (robotics and information systems) DNA sequencing, preliminary identification and publishing.
A G C T TTTGGTCCGGCTATTCCATGATGTGCTTTTTTT TTGGTCCGGCTATTCCATGATGTGCTTTTTTT TGGTCCGGCTATTCCATGATGTGCTTTTTTT GGTCCGGCTATTCCATGATGTGCTTTTTTT GTCCGGCTATTCCATGATGTGCTTTTTTT TCCGGCTATTCCATGATGTGCTTTTTTT CCGGCTATTCCATGATGTGCTTTTTTT CGGCTATTCCATGATGTGCTTTTTTT GGCTATTCCATGATGTGCTTTTTTT GCTATTCCATGATGTGCTTTTTTT CTATTCCATGATGTGCTTTTTTT TATTCCATGATGTGCTTTTTTT ATTCCATGATGTGCTTTTTTT dATP dCTP dTTP dGTP ddATP32 ddCTP32 ddTTP32 ddGTP32 + DNA Sequencing (old method) 5’-AAACCAGGCCGATAAGGTACTACACGAAAAAAA-3’ TTTTTTT AAACCAGGCCGATAAGGTACTACACGAAAAA | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | Step 1. Extend complementary sequence using “free” nucleotides with limiting amounts of radioactive “terminating” nucleotides. Step 2. Run product out on a electrophoresis gel. Step 3. Place gel against radiographic film, develop.
DNA Sequencing new method) http://users.rcn.com/jkimball.ma.ultranet/BiologyPages/D/DNAsequencing.html
GGATCCTGCAAGGAGGGATACAAATTACATACATTTGTCAAAACCCACAGCATGTTGACCACCAGGAGGAGACCCCATGTGACTCCAGGACCCTGGTTGATAACAACGTATCGAGATTCCTCACATGGAACCAGTGCGCTCCTGTGGTGGAGGGTGTACCTGTGTCAGGGCAGGGGGTACGTGGACATTTTCTGCAGTTTTTGATCAATTTTGCAATGAACTAAATCTGTGGTATAAAAATAAAGTCTATTAAAAGAATCCAAGGCTCCCTCTCATCTCACGATAAGATAAAGTCCCCATCCATTTTACTCCTCTCAGCCCTGGAGAAAGGAGAGGCCAGGTCCCACCACCTTCCACCAGCATGGACCCCCAGTCCAGACCCCACGCCTTTTCTCAGCATCCTCAGACCAGCAGGACTTGCAGCAATGGGGAATTAGGCACCTGACTTCTCCTTCATCTACCTTTGGCTGGGGGCCTCCAGCCTTGACCTTCGCTCTGAGAGTCTCAGGCAGGTCCAGAGCCAGTTCTCCCATGACGTGATATGTTTCCAGAGCAGGTTCCTGGGTGAGATAAAAGGATTTGGGCTGAACAGGGTGGAGGGAGCATTGGAATGGCACTCAGGGCAAAGGCAGAGGTGTGCGTGGCAGCGCCCTGGCTGTCCCTGCAAAGGGCACGGGCACTGGGCACTAGAGCCGCTCGGGCCCCTAGGACGGTGCTGCCGTTTGAAGCCATGCCCCAGCATCCAGGCAACAGGTGGCTGAGGCTGCTGCAGATCTGGAGGGAGCAGGGTTATGAGCACCTGCACCTGGAGATGCACCAGACCTTCCAGGAGCTGGGGCCCATTTTCAGGTAAAGCCCTCCCTGGCCCTCGCTGGGAACACCCAGATCCCTGCCCCTGCTGCCCAGGACCCTGCCAGGCACTCAGCACTGCCATTCCCAGCAGGTCCCGGCACTCTGCATCCTTTGGAGGATGGGGAAGGAGTGCAGCACATGCTGGTCTGTGGTGCTGCCAGGGCAGGGGATAGTGCAGAGAAAACCCCAGCTCACTGCAGAGAGGGCAGGACTCAGAAGCACTAAAGTTGAAAGGTTCCAGGGAGCCAGCAGGAGGGCTTTAGCTGTGAAGCCGCTAATCCAGGAGCAGGGAGGGTGGACAGGAGACACTTTGGATTGGGACTGCAGGGTGGGGCCACGAGGGACATGACCCCGTCCAGCAGGGCCTCCTGCTTGGCCCCACAGGTACAACTTGGGAGGACCACGCATGGTGTGTGTGATGCTGCCGGAGGATGTGGAGAAGCTGCAACAGGTGGACAGCCTGCATCCCTGCAGGATGATCCTGGAGCCCTGGGTGGCCTACAGACAACATCGTGGGCACAAATGTGGCGTGTTCTTGTTGTAAGCGGCGAGTTGGGAGCTGAGAGCTGGGAGCAGGGTGGGCAGCCTGGGTGTAGGGGGGAGGCGAGAGAGGTAGGACCCAAAAGCACATCTGCCCTGGGCCCCTGTGGTGGGCAGTGAGGGTGAGCACCCGGCCCAGAGGACGGCCATCCTGTGGGGTCGCGTCTGCACTGTGGGTTGGGGAAGCAGGGCGGTGGTGGAGAAATGGGCACGGGCACCTCTGCAGAGAAGACGCAGAGCAATGAGCCCTTCTGTGTAGTGAGAACCCGCTCTGCACCAACCTCGGCGGCTGCTTTCTCTTGCGGTCTGGGGACTGTCCTTCCCATAGGTCAGAAAACTGAGGCCCTGAGAAGGGGACTTCCACTGGCCCAGGTCACAGGCTGAGTGCTGAGCCTGGTGTTCGCCGGGGCCGCAGCCTCCCTCAGGGCGCTCAGGGTCCCTGCAGTCCTGGCAAACCTTCCTGATGGGGACAGTCCGGGGCAGGAGGCAGGTGGGGACGCAGGTGGCTGGTGGTTCCGTTGTTCTCAGAAGCAAGGCACAAGGTGGGGCGGTTGATGGCACTGGGGAGGATGTTTCCTGGCCCGTGGAGAGGGTGGCGCCTGGTCAGGTGGGCAGGGAGAGGCTGATGCTTGGAGTCGGTCACCTGCAGGGATGTTGTCATTAGGACGGGGGAAGGACTGGATGAGGATGTCACAGTGGTGACAGCCCCCACTCCATGGTAGGAAGGGAACGCTATTGGGAATAGTGGGGTTTAGGTAAAAGGGCACCCGTGGGTCGGGGCCTTCACTGAGGCTGGCCTATAGATGACATCTGGGAGAGAGTCAGGACCCAGGAAGGCAGGTCCAGGAGGATCCTGCAAGGAGGGATACAAATTACATACATTTGTCAAAACCCACAGCATGTTGACCACCAGGAGGAGACCCCATGTGACTCCAGGACCCTGGTTGATAACAACGTATCGAGATTCCTCACATGGAACCAGTGCGCTCCTGTGGTGGAGGGTGTACCTGTGTCAGGGCAGGGGGTACGTGGACATTTTCTGCAGTTTTTGATCAATTTTGCAATGAACTAAATCTGTGGTATAAAAATAAAGTCTATTAAAAGAATCCAAGGCTCCCTCTCATCTCACGATAAGATAAAGTCCCCATCCATTTTACTCCTCTCAGCCCTGGAGAAAGGAGAGGCCAGGTCCCACCACCTTCCACCAGCATGGACCCCCAGTCCAGACCCCACGCCTTTTCTCAGCATCCTCAGACCAGCAGGACTTGCAGCAATGGGGAATTAGGCACCTGACTTCTCCTTCATCTACCTTTGGCTGGGGGCCTCCAGCCTTGACCTTCGCTCTGAGAGTCTCAGGCAGGTCCAGAGCCAGTTCTCCCATGACGTGATATGTTTCCAGAGCAGGTTCCTGGGTGAGATAAAAGGATTTGGGCTGAACAGGGTGGAGGGAGCATTGGAATGGCACTCAGGGCAAAGGCAGAGGTGTGCGTGGCAGCGCCCTGGCTGTCCCTGCAAAGGGCACGGGCACTGGGCACTAGAGCCGCTCGGGCCCCTAGGACGGTGCTGCCGTTTGAAGCCATGCCCCAGCATCCAGGCAACAGGTGGCTGAGGCTGCTGCAGATCTGGAGGGAGCAGGGTTATGAGCACCTGCACCTGGAGATGCACCAGACCTTCCAGGAGCTGGGGCCCATTTTCAGGTAAAGCCCTCCCTGGCCCTCGCTGGGAACACCCAGATCCCTGCCCCTGCTGCCCAGGACCCTGCCAGGCACTCAGCACTGCCATTCCCAGCAGGTCCCGGCACTCTGCATCCTTTGGAGGATGGGGAAGGAGTGCAGCACATGCTGGTCTGTGGTGCTGCCAGGGCAGGGGATAGTGCAGAGAAAACCCCAGCTCACTGCAGAGAGGGCAGGACTCAGAAGCACTAAAGTTGAAAGGTTCCAGGGAGCCAGCAGGAGGGCTTTAGCTGTGAAGCCGCTAATCCAGGAGCAGGGAGGGTGGACAGGAGACACTTTGGATTGGGACTGCAGGGTGGGGCCACGAGGGACATGACCCCGTCCAGCAGGGCCTCCTGCTTGGCCCCACAGGTACAACTTGGGAGGACCACGCATGGTGTGTGTGATGCTGCCGGAGGATGTGGAGAAGCTGCAACAGGTGGACAGCCTGCATCCCTGCAGGATGATCCTGGAGCCCTGGGTGGCCTACAGACAACATCGTGGGCACAAATGTGGCGTGTTCTTGTTGTAAGCGGCGAGTTGGGAGCTGAGAGCTGGGAGCAGGGTGGGCAGCCTGGGTGTAGGGGGGAGGCGAGAGAGGTAGGACCCAAAAGCACATCTGCCCTGGGCCCCTGTGGTGGGCAGTGAGGGTGAGCACCCGGCCCAGAGGACGGCCATCCTGTGGGGTCGCGTCTGCACTGTGGGTTGGGGAAGCAGGGCGGTGGTGGAGAAATGGGCACGGGCACCTCTGCAGAGAAGACGCAGAGCAATGAGCCCTTCTGTGTAGTGAGAACCCGCTCTGCACCAACCTCGGCGGCTGCTTTCTCTTGCGGTCTGGGGACTGTCCTTCCCATAGGTCAGAAAACTGAGGCCCTGAGAAGGGGACTTCCACTGGCCCAGGTCACAGGCTGAGTGCTGAGCCTGGTGTTCGCCGGGGCCGCAGCCTCCCTCAGGGCGCTCAGGGTCCCTGCAGTCCTGGCAAACCTTCCTGATGGGGACAGTCCGGGGCAGGAGGCAGGTGGGGACGCAGGTGGCTGGTGGTTCCGTTGTTCTCAGAAGCAAGGCACAAGGTGGGGCGGTTGATGGCACTGGGGAGGATGTTTCCTGGCCCGTGGAGAGGGTGGCGCCTGGTCAGGTGGGCAGGGAGAGGCTGATGCTTGGAGTCGGTCACCTGCAGGGATGTTGTCATTAGGACGGGGGAAGGACTGGATGAGGATGTCACAGTGGTGACAGCCCCCACTCCATGGTAGGAAGGGAACGCTATTGGGAATAGTGGGGTTTAGGTAAAAGGGCACCCGTGGGTCGGGGCCTTCACTGAGGCTGGCCTATAGATGACATCTGGGAGAGAGTCAGGACCCAGGAAGGCAGGTCCAGGA