Download

1 / 47
470 likes | 663 Views
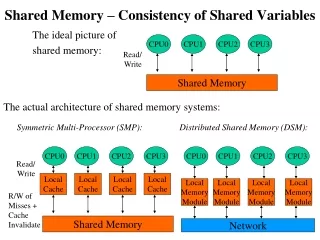
Shared Memory Consistency Models. Quiz (1). Let’s define shared memory. We often use figures like this…. But perhaps shared memory is not about how CPUs/memory are wired…. CPU. CPU. CPU. CPU. memory. Is this shared memory?. CPU. CROSSBAR SWITCH. CPU. CPU. CPU. memory module.

E N D
Quiz (1) • Let’s define shared memory
We often use figures like this… • But perhaps shared memory is not about how CPUs/memory are wired… CPU CPU CPU CPU memory
Is this shared memory? CPU CROSSBAR SWITCH CPU CPU CPU memory module memory module memory module
And we have a cache, too • Is this still a “shared” memory? CPU CPU CPU CPU $ $ $ $ memory
Observation • Defining shared memory in terms of how CPUs and memory are physically organized does not seem feasible • Moreover, it is not necessary either, at least from programs’ point of view
From programs’ point of view • What matters is the behavior of memory observed by programs • Vaguely, if a value written by a process is seen by another process, theyshare a memory • no matter how this behavior is implemented • We try to define shared memory along this idea
Defining shared memory by its behavior • We try to define “possible behaviorsoutcome of read operationsof memory system” in the presence of processes concurrently accessing them • We call such behaviors “consistency model” of shared memory
But why are we bothered? (1) • Otherwise we can never (formally) reason about the correctness of shared-memory programs • Implementation of a shared memory (either by HW or SW) needs such a definition too • draw the boundary between legitimate optimizations and illegal ones
But why are we bothered? (2) • What we (most of us) consider “the natural definition” of shared memory turns out very difficult to implement efficiently • we have caches (replicas) that make implementation far from trivial • many optimizations violate the natural behavior • Most part of most shared memory programs can work with more relaxed behaviors
But why are we bothered? (3) • Therefore many definitions of consistency models have been invented and implemented • They are called relaxed consistency models, relaxed memory models, etc.
Sequential consistency • The first “formally defined” behavior of shared memory by Lamport • Lamport, "How to Make a Multiprocessor Computer that Correctly Executes Multiprocess Programs," IEEE Trans. Computers, Vol. C-28, No. 9, Sept. 1979, pp. 690-691. • Presumably most of us consider it natural • Before defining it, let’s see how natural it is
Quiz (2) • What are possible outputs? List all. Initially: x = 0; y = 0; Q: y = 1; printf(“x = %d\n”, x); P: x = 1; printf(“y = %d\n”, y);
(0, 0) seems impossible… • P : x = 1; read y; • Q : y = 1; read x; • Possible orderings • x = 1; read y; y = 1; read x; (1, 0) • x = 1; y = 1; read y; read x; (1, 1) • x = 1; y = 1;read x; read y; (1, 1) • y = 1; x = 1;read y; read x; (1, 1) • y = 1; x = 1; read x; read y; (1, 1) • y = 1;read x; x = 1;read y; (0, 1)
Or more concisely, • P : x = 1; read y; • Q : y = 1; read x; • if P reads zero, then y = 1 by Q comes after read y. The only possible sequence in this case is: • x = 1; read y; y = 1; read x Q reads 1 • Thus (x, y) = (0, 0) cannot happen
By the way, • This is the basic of a classical mutual exclusion algorithm found in OS textbooks /* Entry section for P1 */Q1 := True; TURN := 1; wait while Q2 and TURN = 1; /* Exit section for P1 */ Q1 := False; /* Entry section for P2 */Q2 := True; TURN := 2; wait while Q1 and TURN = 2; /* Exit section for P2 */ Q2 := False;
Somewhat outdated material • no longer works in relaxed models • today’s CPUs has supports more straightforward ways to implement mutual exclusion (compare-swap, LL/SC, etc.)
Back to the subject • The assumption underlying the above discussion is the very definition of “sequential consistency”
Definition of sequential consistency (preliminary) • Processes access memory, by issuing:a = x /* write x to variable a */a /* read from variable a */ • An execution of a program generates events of the following two kinds: • WRITEP(a, x) /* P writes x to variable a */ • READP(a, x) /* P reads x from variable a */ • We use “processes” and “processors” interchangeably
Definition • A shared memory is sequentially consistent(SC) iff for any execution, there is a total order < among all READ/WRITE events such that: • if a process p performs e1 before e2 then e1 < e2 • preserve the program order • for each READP(a, x), if we let WRITEQ(a, y) be the last write to a in the above total order, then x = y • read returns the last write
Informally, it says: • to reason about possible outcome of the program, interleave all reads/writes in all possible ways and assume each read gets the value of the last write to the read location P’s accesses Q’s accesses
So far so good • We will see a reasonable optimization easily breaks SC • Let’s assume we are implementing a shared memory multiprocessor of two CPUs, with caches $ $ mem
Recall the previous program and assume both CPUs cache x and y • main memory is not important in this example x=0 y=0 x=0 y=0
P writes 1 to x. It will need update (or invalidate) the other cache P Q x=0 y=0 x=1 y=0
A processor does not want to block while update/invalidation is in progress (a reasonable optimization for an architect) • P may then get 0 from y in the cache P Q x=0 y=0 x=1 y=0
Q may experience a similar sequence and get 0 from x in the cache P Q x=0 y=1 x=1 y=0
We ended up with both processors’ reading zeros • This violates SC P 0 Q 0 x=1 y=1 x=1 y=1
Looking back (1) • P writes 1 to xP • P sends an update msg to Q • P reads 0 from yP • Q writes 1 to yQ • Q sends an update msg to P • Q reads 0 from xQ • P receives an update msg and write 1 to yP • Q receives an update msg and write 1 to xQ
Looking back (2) • In intuitive terms, “a write is not atomic”, because a single write must update multiple locations (caches) • Definition of SC (total order among R/W events) can be interpreted as saying “a write is atomic”
What if we do not have caches? • Assume there are no caches, but there are multiple memory modules • Assume there is no single bus that serializes every access P Q x=0 y=0
How to fix it (one possibility) • A write by processor P first gets an exclusive access to the bus • P sends an update/invalidate msg to the other cache • The other cache replies with an acknowledgement after updating the variable • P blocks (does not issue furthermemory accesses) until it receives the acknowledgement • P updates its cache and releases the bus Essentially, really serialize all accesses
Illustrated • During (1) and (2), • P blocks (stalls) • The bus won’t be granted for other accesses P Q (1) update/invalidate (2) ack
Can you prove this implements SC? • For simplicity, assume • No main memory (cache only) • Data are always on both caches • An update protocol • A write sends the new value to the other cache • Reads never miss. It immediately returns the value currently on the cache
Outline • Model the protocol as a distributed-memory (asynchronous message passing) program • define relevant events (acquire_bus, recv_update, recv_ack, release_bus, read) • call them micro-events • an execution of such a protocol generates a total order of such micro-events. • from the execution, construct a total order of READs/WRITEs satisfying the definition of SC
Relaxed Memory Consistency Models • So many “weaker” consistency models have been proposed both for multiprocessors, software shared memory, programming languages, file systems, ... • They are generically called “relaxed memory consistency”
Models in the literature • processor consistency • total store order, partial store order, relaxed memory ordering • weak consistency • release consistency • lazy release consistency • ...
How they are generally defined • Which memory accesses may be reordered • A processor Q may observe another processor P’s writes differently from the order P issues them • Writes may not be atomic • Processors Q and R may observe another processor P’s writes differently from each other
Memory barrier • Processors not supporting SC usually have separate “memory barrier” instructions to enforce ordering/completion of instructions • usually called “memory barrier” or “fence” • sfence, lfence, mfence (Pentium) • membar (SPARC) • wmb, mb (Alpha) • etc.
Variants • Different instructions enforce ordering between different kinds (load/store) of memory accesses • e.g., SPARC • “membar #StoreLoad” ensures following loads do not bypass previous stores • e.g., Pentium • “lfence” ensures following loads do not bypass previous loads
... R W R membar R W R ... Semantics of memory barrier • if processor P issues “a ; membar ; b” in this order, another processor Q will observe a before b • all membar events are totally ordered and the order preserves the program order
In implementation terms • membar will stall processor until all previous accesses have been completed • e.g., until • in-transit load instructions have returned values, and • in-transit cache invalidations have been acknowledged
Memory consistency for programming languages • So far we have been dealing with semantics of “processors” (or machine languages) • Ideally, all programming languages should define precise consistency models too, but they rarely do
Today’s common practice (1) C/C++ • “you know which expression access memory” • *p, p->x, p[0], ... • they are not actually trivial at all! • global variables • non-pointer structs • optimizations eliminating memory accesses • Programmers somehow control/predict them by inserting volatile etc.
Today’s common practice (2)most high-level languages • Do not write programs for which subtle consistency semantics matter • only use supported idioms mutex, cond_var, ..., for synchronization, to guarantee “there are no races” • What if there are races ? undefined (rarely stated explicitly)
High-level languages • What are races? • conflicting accesses to the same data • What are conflicting accesses? • not separated by supported synchronization idioms (unlock -> lock, cond_signal -> cond_wait) • and one of them is a “write”
The third way : Java • We will see presentation of the last week • Java has “synchronized” (lock), and wait/notify (condition variable) used for most synchronization operations • At the same time, Java also defines behavior under races (memory consistency model) • discussion in the community revealed how intricated it is