Download

1 / 21
210 likes | 356 Views
VMware Farm Optimization. By Jeremy Kampwerth jkampy@hotmail.com. Introduction To Me. Windows and Unix System Administrator for 8 years. Capacity and Performance Engineer for 6 years. Apparently I like working for large companies. I consider myself a jack of many trades.

E N D
VMware Farm Optimization By Jeremy Kampwerth jkampy@hotmail.com
Introduction To Me • Windows and Unix System Administrator for 8 years. • Capacity and Performance Engineer for 6 years. • Apparently I like working for large companies. • I consider myself a jack of many trades. • Presentations like this are not one of the trades.
In General • Topic has VMware in the title but this is not about VMware specifically as the concepts I will discuss could be applied to any virtual environment. • The concepts are more about common sense then they are trade secrets. • My role was to assist the project by providing analysis and technical expertise. • I was not doing the dirty work
Introduction to the Topic • Working hand-in-hand with the virtual support team to reign in the wild fire that was virtual sprawl. • Optimize VMs based on historical utilization data with added controls around application requirements. • Today capacity team is part of the before and after process to regulate and review.
Introduction to the Topic • I will discuss • How we got into the mess and how did the capacity team help to get out of the mess. • How and why was the capacity team engaged. • The expensive tools we used to do the job. • The guidelines we used to make safe decisions. • What were the failures? • What led to the successes?
How did we get into this mess? • Many factors led to the wild fire (virtual sprawl) • Corporate decision to push virtualization • Lack of controls in request process • Lead to many over-provisioned VMs • Existing large non-centralized environment managed across many different internal organizations each with a different set of rules
Ask the Capacity Team for help • Surely the internal capacity team was the first call. • Surely before they ask for money they would think of the capacity team. • Surely upper management would know the capacity team exists. • Luckily they did
What was being asked • Can we help the virtual team reign in the madness? • Can we produce same results as outside company? • Can we do it in a safe manner? • Can we do it reliably and reproduce reliability?
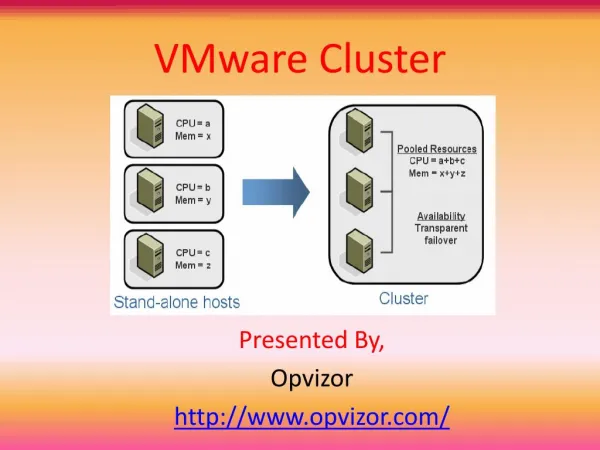
What did they do? • Looked at data for thousands of VMs • Data only contained 4 weeks • Analysis via Modeling tool • Fancy tool with top secret formula • CMDB details not considered • No application relationships • No account for age of the VM • Many reductions found • Over 40% vCPU reduction • Over 70% vMEM reduction
Our Guidelines • Make sure the server is being used for what it was intended • In deployment for 180 days • Consider the application • Match by role and function • Within each application, all production web servers should be sized the same • Enough Data • Minimum 90 days of data • Peak utilization • No arguing (but but why?) • 15 minute interval • Add headroom • 20% headroom for vCPU • 5% headroom for vMem (consumed memory)
The Process • Capacity team to produce the results and review and with project team to identify candidates. • Project team to communicate plan to planners and application owners. • Allow for rebutal • But you better bring the facts • Optimize
The First Year Results • Of the 15% of VM candidates identified • 23% were cancelled after appeals process • Of the completed • 50% reduction in configured vCPUs • vMem was excluded • 100% of reductions made with no issues
The Second Year Results • Of the 8% of VM candidates identified • 24% were cancelled after appeals process • Of the completed • 20% reduction in configured vCPUs • 10% reduction in configured vMem • 100% of reductions made with no issues
Realized Benefits • Better performing VMs • Over-provisioning of resources can hurt • Better performing Hosts • Accurate view allowed for higher utilization of the clusters • Costs • Delayed purchase of new farms for over a year • Time to focus on future • New farms running more powerful hardware allowed for a many to one replacement
What were the issues? • Communication breakdown • First knowledge of optimization was from the change request • Lack of understanding • Not knowing how and why • Coordination of optimizations • Had to learn how things would work
What led to the Success? • Management backing • You will be optimized unless you can produce evidence • Conservative formula • Peak utilization served us well • Communication, Communication, Communication • Processes in place • Appeals process • Resources on demand (or at least with a phone call)
Where are we today • Part of the request process • Previously we may or may not be asked for sizing • Currently all sizings come through us • All existing servers get a sizing recommendation • Annual Optimization Review • At least one optimization per year • Optimization now includes vCPU, vMem, and storage • Storage follows same type guidelines but analysis not be capacity team