Download

1 / 32
• 320 likes • 341 Views
Discover the fundamentals of microarray technology, including Illumina Beadarray, Affymetrix, and Spotted Arrays. Learn basic data analysis techniques and quality control methods. Explore normalization procedures and tools like Bioconductor for efficient analysis. Delve into gene expression analysis and pathway exploration using GeneSpring and GSEA. Dive into transcription factor regulon monitoring and network analysis with NextBio.

E N D
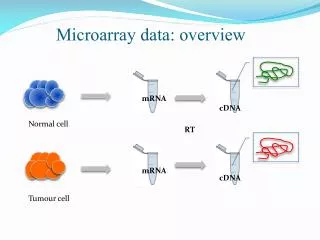
An overview of Microarray Technology and Data Analysis Basic Data Analysis
The Illumina Beadarray Technology • Highly redundant (~50 copies of a bead) • 60mer oligos • Each array is deconvoluted using a colour coding tag system • Human, Mouse, Rat, Custom
Affymetrix Technology • Highly redundant (~25 short oligos per gene) • PM-MM oligo system valuable for cross hybe detection • Human, Mouse, E. coli, Yeast…….. • Affy and illumina arrays have been systematically compared
Spotted Arrays • Low redundancy • cDNA and oligo • Cy5/Cy3 dye • Cost and custom
Worked Example: illumina data • Data contains 36 experiments by 47294 genes. Raw data extracted using Beadstudio. • Quality controlled in “R” package. Removed unexpressed genes using the Beadstudio Detection P-value. Leaves ~28,000 genes. • Quantile Normalised data, and quality controlled the normalisation in maCorrPlot “R” package. • Clustered using Hierarchical methods
BeadArray Quality Control Primarily look at hybe controls (internal spikes) and the housekeeping genes. Stringency should be greater than 3-fold. Hybridisation Controls == Stringency ==
The free R-stats package A massively powerful program with hundreds of plugins BUT requires a LARGE investment to learn. Some good web resources: Bioconductor Gives you access to good free Affy analysis tools
Raw Data from Beadstudio Use the P-detection QC tool in Beadstudio2 or use the R code: >inds = apply(dat[,c(F,T)],1,function(x) any(x>=0.99)) >dat.present <- dat[inds,c(T,F)] Signal P-value column Normalisation in BeadStudio is also an option
Normalisation • Why? • Remove chip to chip variation • Many different methods • A) Normalisation to the mean (old school) • B) Intensity-dependent normalisation • -to rank invariant genes (housekeeping) • -Quantile normalisation
Boxplots showing raw data for 36 chips: 3 bad? >boxplot(log(dat.present)) Outliers 75% quartile Median 25% quartile
After QC for low confidence genes (P<0.99) Note: ~50 replicate beads per array Outliers 75% quartile Median 25% quartile
The effect of quantiles Normalisation on the filtered 36 data sets >library(affy) >Qdata <- normalize.quantiles(Rawdata)
Judging the success of normalisation: maCorrPlot >library(maCorrPlot) >corrA.raw = CorrSample(mat.present_raw, np = 1000, seed = 1234) >plot(corrA.raw, main = "6-8 Quantiles") >dev.print (device=pdf, file = "6-8 Quantiles.pdf") One round of quantiles normalisation works well
Looking for patterns in the data using correlation coefficients Diagonal Block of similar Samples
Non Negative Matrix Factorisation Maths for the real world -image analysis -text analysis Works very well with array data Compares using small areas of change
NMF: cancer classification etc Good way to visualize large data sets
GeneSpring • Shared Resources has a copy which is available via Remote Desktop • High quality software; very carefully put together. Respected, tried and tested. • Good user friendly statistics
Core GeneSpring functions • Drag and drop data table • Remove low expressing genes • Define replicates and groups • ANOVA • Expression across Pathways
KEY FUNCTION: Experiments > Experiment parameters You must define the replicates in experiment parameters
Filtering>Filter on Volcano Plot Plots most robustly changed genes P-value Fold Change
Pathways in GeneSpring View all data in parallel across pathway Clicking takes you to the NCBI
The Free GeneSet Enrichment Analysis (GSEA) Program • where single-gene analysis finds little similarity between two independent studies, GSEA reveals many biological pathways in common • GSEA has a database of 1,325 biologically defined gene sets
Monitoring Transcription Factor Regulons across cell types Network analysis
NextBio: Comparing to all available data Query Biogroup (geneset) Your Data Uploaded NextBio Data 30,000 arrays Query Against
Results of Query against all Biogroups Drill down to lists>individual genes>NCBI