Download
1 / 20
200 likes | 217 Views
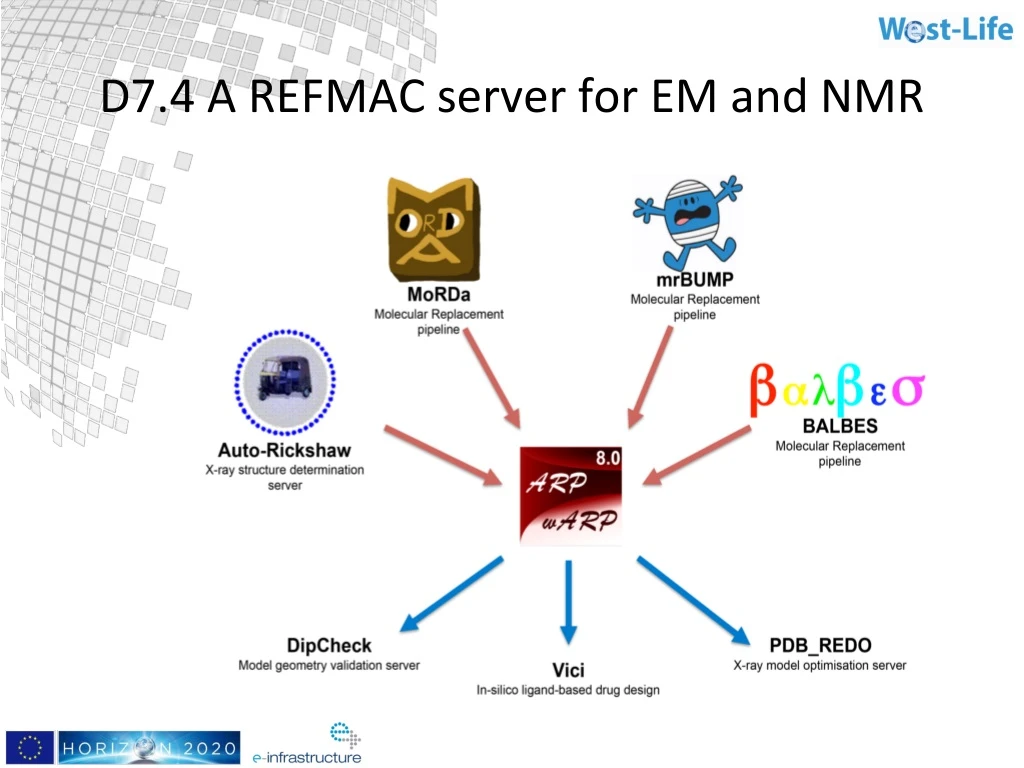
D7.4 A REFMAC server for EM and NMR. D7.7: Quality analysis workflow for predicted complexes. Joint project: EMBL-EBI Marc F. Lensink (University of Science and Technology of Lille). Background & rationale.

E N D
D7.7: Quality analysis workflow for predicted complexes • Joint project: • EMBL-EBI • Marc F. Lensink (University of Science and Technology of Lille)
Background & rationale Protein–protein interactions and protein assemblies play a crucial role in all cellular processes. A small fraction of protein complexes have been solved experimentally. Computational procedures to generate models of macromolecular assemblies is important to supplement experimental methods. Validation of experimentally determined structures: coordinated by the wwPDB structure validation task forces (X-ray, NMR, EM, hybrid/integrative methods). These are available to worldwide user. Validation of predicted complexes is established by the CAPRI (Critical Assessment of Predicted Interactions) community, however it is not available to users. This deliverable (D7.7) aims to make this analysis protocol available to users worldwide.
CAPRI + evaluation criteria • The Critical Assessment of Predicted Interactions (CAPRI) is a community-wide initiative to organize worldwide experiment for macromolecular complex prediction. Established in 2001. • >130 complexes have been predicted by groups worldwide • Since its inception, the CAPRI committee has organized six evaluation meetings. During these evaluation meetings, discussions within the community have led to established standards for the parameters and criteria used to evaluate the quality of the predicted complexes • Assess geometric (L-rms, I-rms) and biological (f(nat)) properties of the models
Web server Input 1: Structures of Unbound proteins Input 2: Structure of Complex Input 3: Predicted models Run workflow on EBI farm
Result • User provide e-mail – unique link to result • Currently, result shows a table showing classification of each model • Will allow download of superposition files, etc
D7.8 Report on prototypes using Big Data approaches • Selected projects: • Implementation of Convolutional Neural Network for structural biology maps • Clustering PDB entries • Extracting mentions of residues from literature
Machine learning for cryoEM First prototype for "Big Data" technologies in structural biology Other examples: • Steve Ludtke CNNs for cryoET • SuRVoS for segmentation • Several attempts at particle picking • Use case: • Analyse 3D maps to learn and recognise features at different scales: • e.g. missing components, domains, side chains • Protein vs nucleic acid vs solvent • EM: effect of map sharpening • xtal: effect of phase quality
CNN for maps • Network • Classify as protein or noise • Implemented with Keras • Tried standard VGG16 model, but reverted to 5-layer model Data • EMD-2984 betagal2.2Å • 48*48 pixel 2D slices • Fitted model 5a1a to annotate as protein or not • Compare deposited map with blurred map • 33,148 and 18,750 slices respectively deposited blurred
Similarity and clustering in PDB • The problem • New protein/chain, find similar ones in PDB • Several methods to assess similarity, e.g. • GESAMT: E. Krissinel, Enhanced fold recognition using efficient short fragment clustering, J MolBiochem.,2012, 1: 76-85 • RCC: R.Corral-Corral et al., Machine Learnable Fold Space Representation Based on Residue Cluster Classes,Comp. biol. and chem., 2015, 59: 1-7. • Too many (140k entries/500k chains) to compare with all • Representative clean set (65k chains) • Thorough statistics (space coverage, similarity measure correlation, pairwise similarity distribution, …) • Two proposed approaches • Dissimilarity search, dimensionality reduction and clustering
Similarity and clustering in PDB • “Dissimilarity search” • If the new structure t is dissimilar to some r, anything similar to r needn’t be considered • Precompute similarity of all entries with some fixed representative set N • Still feasible -- dne once, extensible with new entries • On query with t, choose random samples of N • Based on precomputed similarities, use them to identify candidates • Compute similarity of t with all candidates, choose the best one
Similarity and clustering in PDB • Dimensionality reduction and clustering • Compute residue cluster classes –26 integer descriptors • Embed in real space, perform linear and non-linear dimensionality reductions • Apply multiple clustering techniques • Evaluate quality of resulting clusters • Framework to plug in different algorithms in all steps being developed
Similarity and clustering in PDB • Plans • Develop prototypes • Cross-validate results • Use independent similarity assessment techniques • Publish! • Integrate with PDB
Natural Language Processing • Annotations will also be imported to PDBe • Dashboard at https://pyresid-dash.herokuapp.com/ • Uses spaCy • Software pyresid available via pip • IUCR considering use • Work done by Rob Firth STFC, Francisco Talo EBI • Rob will attend OpenMinTed conference • Challenges: sentence boundary recognition • Possible continuation by future grant application • Ingest from Proteopedia?
D7.9 Report on existing metadata standards, and proposals for new vocabularies • Provenance: D6.4 should add PROV-O to Virtual Folder • Projects: translate ARIA metadata to CERIF • Workflows: CSIC EOSC Pilot on cryoEMworkflows • NUTS metadata in Repository, ? NMR-STAR • mmCIF…
UU Contribution to data standards • Utrecht member of the integrative modelling task force of PBD • Contributing to expending the mmCIF dictionary • https://github.com/ihmwg/IHM-dictionary • Visit to Sali’s lab at USSF and RCSB in Rutgers in January • First HADDOCK integrative model deposited in PDB dev: • https://pdb-dev.wwpdb.org
mmCIF • DipChecknow accepts mmCIF input • ARP/WARP accepts mmCIF for ligands but not proteins (EMBL-Hamburg) • The PDB-REDO databank now stores mmCIF files • The PDB_REDO service reads and writes mmCIF • Version 8 of PDB-REDO will use mmCIF internally (NKI). • 3DBionotes reads mmCIF