Download

1 / 19
190 likes | 207 Views
This study compares Single-Thread Performance, In-order Processor, Sun Niagara 1.2.4, #threads per chip, and out-of-order Processor designs to determine the optimal architectural choice. Focusing on performance, power, and thermal factors, it evaluates the impact of L2 cache size variations, advantages of SMT over CMP architectures for memory-bound benchmarks, and energy efficiency considerations with Dynamic Thermal Management. Key findings indicate different thermal profiles and performance efficiencies between SMT and CMP setups, highlighting the need for further exploration of thread-level parallelism and hybrid core designs.

E N D
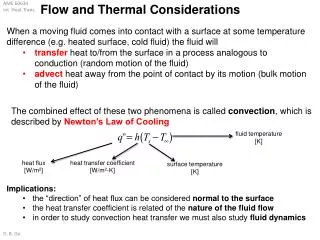
Performance, Energy and Thermal Considerations of SMT and CMP architectures Yingmin Li, David Brooks, Zhigang Hu, Kevin Skadron Dept. of Computer Science, University of Virginia Division of Engineering and Applied Sciences, Havard University IBM T.J.Watson Research Center
note: not to scale Equal performance curve? Out-of-order Processor CMP with out-of-order Cores CMP with out-of-order SMT cores Single Thread Performance In-order Processor Sun Niagara 1 2 4 #threads per chip Motivation • Future trend calls for multi-core and multi-thread architectures • Which is better: lots of tiny speed demons or fewer brainiacs? • Which is more valuable, more L2 or additional cores? • Performance, power, and thermal properties of multi-core vs. multi-thread architectures not well understood
Scope of this Study Equal-area comparison between SMT vs. CMP extensions of an Apple G5-like core Note: 1MB L2 roughly equals to 1 G5 like Core in terms of area Single- threaded SMT Single-threaded CMP
Outline • Modeling / Model Validation • SMT vs. CMP performance, power and thermal analysis (without DTM) • SMT vs. CMP performance, power and thermal analysis (with DTM) • Conclusions and future work
Performance sensitivity with different L2 size CMP L2 size = SMT L2 size – 1MB
Modeling and Validation • Performance: Turandot with SMT and CMP augmentations, validated against Power4 preRTL model • Power: PowerTimer with SMT and CMP augmentations, validated against CPAM power data extracted from circuit • Temperature: Hotspot from UVA integrated with Turandot/PowerTimer, validated with test chips at UVA
Turandot/PowerTimerSimulationFramework • Supports SMT/CMP • Runs on AIX/PowerPC and Linux/Intel platforms • PowerTimer based on CPAM data, extracted from circuits • See Micro’02 tutorial by Zhigang Hu and David Brooks for details
Hotspot temperature model • Models all parts along both primary and secondary heat transfer paths • At arbitrary granularities • Fast and accurate • Essentially a lumped thermal R-C network
Peak Temperature of The Hottest Spot for SMT and CMP 3 heat-up mechanisms • Unit self heating determined by the power density of the unit • Global heating through TIM (thermal interface material) and spreader • Lateral thermal coupling between neighboring units
Illustration (global heat-up of CMP vs. local heat-up of SMT)
Temperature Trend with technology evolution • Increased utilization of SMT becomes muted • L2 cache tends to be much cooler than the core • Expotential temperature dependence of leakage
SMT vs. CMP performance and power efficiency analysis (without DTM) SMT is superior for memory bound(high-l2-cache-miss rate) benchmarks while CMP is superior for non memory bound benchmarks Compute-bound Memory-bound
The impact of changing L2 size: Examples Changes from memory bound to non memory bound when L2 size changes Stays memory bound when L2 size changes MCF+MCF MCF+VPR
SMT vs. CMP performance with DTM • Global technique • Global DVS • Fetch throttling • Local technique • Rename throttling • Register file throttling (ideal) Localized DTM method favors SMT while global DTM method favors CMP Compute-bound Memory-bound
SMT energy efficiency with DTM Localized method can lead to better energy-delay product result compared with global method in some cases. Compute-bound Memory-bound
CMP energy efficiency with DTM Localized method is inferior for CMP in terms of energy and energy delay product metrics Compute-bound Memory-bound
Conclusions • With the same chip area, SMT performs better than CMP for memory bound benchmarks while CMP performs better than SMT for non memory bound benchmarks with Apple G5 like architecture. • The thermal heating effects are quite different for CMP and SMT • CMP machines are clearly hotter than SMT machines with leaky technology • Different DTM technique favors different architecture
Future Work • Consider significantly larger amounts of thread-level parallelism and hybrids between CMP and SMT cores • The impact of varying core complexity on the performance of SMT and CMP, and explore a wider range of design options, like SMT fetch policies. • Explore server-oriented workloads