Download

1 / 0
0 likes | 153 Views
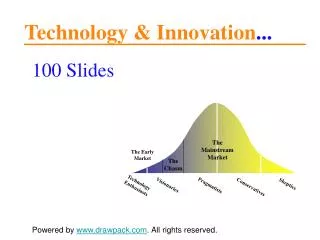
Core of Business “Intelligence” technology. Database warehouse, data mining and on-line analytical processing . Business Intelligence and Analytics for Decision Support. The diagram show the role played by data warehouse, data-mining

E N D