Download

1 / 47
470 likes | 710 Views
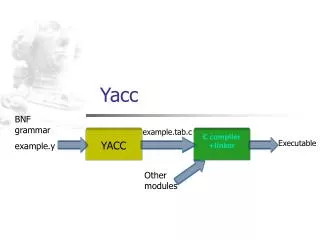
ML-YACC. David Walker COS 320. Outline. Last Week Introduction to Lexing, CFGs, and Parsing Today: More parsing: automatic parser generation via ML-Yacc Reading: Chapter 3 of Appel. The Front End. Lexical Analysis : Create sequence of tokens from characters

E N D
ML-YACC David Walker COS 320
Outline • Last Week • Introduction to Lexing, CFGs, and Parsing • Today: • More parsing: • automatic parser generation via ML-Yacc • Reading: Chapter 3 of Appel
The Front End • Lexical Analysis: Create sequence of tokens from characters • Syntax Analysis: Create abstract syntax tree from sequence of tokens • Type Checking: Check program for well-formedness constraints stream of characters stream of tokens abstract syntax Lexer Parser Type Checker
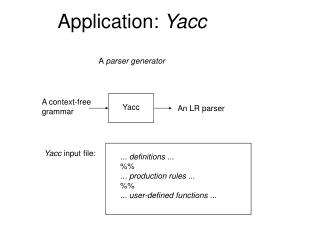
Parser Implementation • Implementation Options: • Write a Parser from scratch • not as boring as writing a lexer, but not exactly a weekend in the Bahamas • Use a Parser Generator • Very general & robust. sometimes not quite as efficient as hand-written parsers. Nevertheless, good for lazy compiler writers. Parser Specification
Parser Implementation • Implementation Options: • Write a Parser from scratch • not as boring as writing a lexer, but not exactly a weekend in the Bahamas • Use a Parser Generator • Very general & robust. sometimes not quite as efficient as hand-written parsers. Nevertheless, good for lazy compiler writers. Parser Specification Parser parser generator
Parser Implementation • Implementation Options: • Write a Parser from scratch • not as boring as writing a lexer, but not exactly a weekend in the Bahamas • Use a Parser Generator • Very general & robust. sometimes not quite as efficient as hand-written parsers. Nevertheless, good for lazy compiler writers. stream of tokens Parser Specification Parser parser generator abstract syntax
ML-Yacc specification • three parts: User Declarations: declare values available in the rule actions %% ML-Yacc Definitions: declare terminals and non-terminals; special declarations to resolve conflicts %% Rules: parser specified by CFG rules and associated semantic action that generate abstract syntax
ML-Yacc declarations (preliminaries) • specify type of positions %pos int * int • specify terminal and nonterminal symbols %term IF | THEN | ELSE | PLUS | MINUS ... %nonterm prog | exp | op • specify end-of-parse token %eop EOF • specify start symbol (by default, non terminal in LHS of first rule) %start prog
Simple ML-Yacc Example grammar symbols %% %term NUM | PLUS | MUL | LPAR | RPAR %nonterm exp | fact | base %pos int %start exp %eop EOF %% exp : fact () | fact PLUS exp () fact : base () | base MUL factor () base : NUM () | LPAR exp RPAR () semantic actions (currently do nothing) grammar rules
attribute-grammars • ML-Yacc uses an attribute-grammar scheme • each nonterminal may have an associated semantic value associated with it • when the parser reduces the parsing stack using rule (X ::= s), a semantic action that uses the semantic values from s will be executed • when parsing is completed successfully, the parser returns the value associated with the start symbol
attribute-grammars • semantic actions typically build the abstract syntax for the internal language • to use semantic values during parsing, we must declare symbol types: • %terminal NUM of int | PLUS | MUL | ... • %nonterminal exp of int | fact of int | base of int • type of semantic action must match type declared for LHS nonterminal in rule
ML-Yacc with Semantic Actions grammar symbols with type declarations %% %term NUM of int | PLUS | MUL | LPAR | RPAR %nonterm exp of int | fact of int | base of int %pos int %start exp %eop EOF %% exp : fact (fact) | fact PLUS exp (fact + exp) fact : base (base) | base MUL base (base1 * base2) base : NUM (NUM) | LPAR exp RPAR (exp) computing integer result via semantic actions grammar rules with semantic actions
ML-Yacc with Semantic Actions datatype exp = Int of int | Add of exp * exp | Mul of exp * exp %% ... %% exp : fact (fact) | fact PLUS exp (Add (fact, exp)) fact : base (base) | base MUL exp (Mul (base, exp)) base : NUM (Int NUM) | LPAR exp RPAR (exp) computing abstract syntax via semantic actions
A simpler grammar datatype exp = Int of int | Add of exp * exp | Mul of exp * exp %% ... %% exp : NUM (Int NUM) | exp PLUS exp (Add (exp1, exp2)) | exp MUL exp (Mul (exp1, exp2)) | LPAR exp RPAR (exp) why don’t we just use this simpler grammar?
A simpler grammar datatype exp = Int of int | Add of exp * exp | Mul of exp * exp %% ... %% exp : NUM (Int NUM) | exp PLUS exp (Add (exp1, exp2)) | exp MUL exp (Mul (exp1, exp2)) | LPAR exp RPAR (exp) this grammar is ambiguous! E E * E E E E + NUM E E E E * + NUM NUM + NUM * NUM NUM NUM NUM NUM
a simpler grammar datatype exp = Int of int | Add of exp * exp | Mul of exp * exp %% ... %% exp : NUM (Int NUM) | exp PLUS exp (Add (exp1, exp2)) | exp MUL exp (Mul (exp1, exp2)) | LPAR exp RPAR (exp) But it is so clean that it would be nice to use. Moreover, we know which parse tree we want. We just need a mechanism to specify it! E E * E E E E + NUM E E E E * + NUM NUM + NUM * NUM NUM NUM NUM NUM
Recall how LR parsing works: desired parse tree: exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR E E E + E E * NUM yet to read NUM NUM Input from lexer: NUM + NUM * NUM State of parse so far: E + E elements of desired parse parsed so far We have a shift-reduce conflict. What should we do to get the right parse?
Recall how LR parsing works: desired parse tree: exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR E E E + E E * NUM yet to read NUM NUM Input from lexer: NUM + NUM * NUM State of parse so far: E + E * elements of desired parse parsed so far We have a shift-reduce conflict. What should we do to get the right parse? SHIFT
Recall how LR parsing works: desired parse tree: exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR E E E + E E * NUM yet to read NUM NUM Input from lexer: NUM + NUM * NUM State of parse so far: E + E * NUM elements of desired parse parsed so far SHIFT SHIFT
Recall how LR parsing works: desired parse tree: exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR E E E + E E * NUM yet to read NUM NUM Input from lexer: NUM + NUM * NUM State of parse so far: E + E * E elements of desired parse parsed so far REDUCE
Recall how LR parsing works: desired parse tree: exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR E E E + E E * NUM yet to read NUM NUM Input from lexer: NUM + NUM * NUM State of parse so far: E + E elements of desired parse parsed so far REDUCE
Recall how LR parsing works: desired parse tree: exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR E E E + E E * NUM yet to read NUM NUM Input from lexer: NUM + NUM * NUM State of parse so far: E elements of desired parse parsed so far REDUCE
The alternative parse exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR E E + NUM NUM yet to read Input from lexer: NUM + NUM * NUM elements parsed so far State of parse so far: E + E We have a shift-reduce conflict. Suppose we REDUCE next
The alternative parse exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR E E E + NUM NUM yet to read Input from lexer: NUM + NUM * NUM elements parsed so far State of parse so far: E REDUCE
The alternative parse exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR * E E NUM E E + NUM NUM yet to read Input from lexer: NUM + NUM * NUM elements parsed so far State of parse so far: E * E Now: SHIFT SHIFT REDUCE
The alternative parse E exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR * E E NUM E E + NUM NUM yet to read Input from lexer: NUM + NUM * NUM elements parsed so far State of parse so far: E REDUCE
Summary desired parse tree: exp ::= NUM | exp PLUS exp | exp MUL exp | LPAR exp RPAR E E E + E E * NUM yet to read NUM NUM Input from lexer: NUM + NUM * NUM State of parse so far: E + E elements of desired parse parsed so far We have a shift-reduce conflict. We have E + E on stack, we see *. We want to shift. We ALWAYS want to shift since * has higher precedence than +.
Example 2 exp ::= NUM | exp PLUS exp | exp MUL exp | exp MINUS exp | LPAR exp RPAR E E - NUM NUM yet to read Input from lexer: NUM - NUM - NUM elements parsed so far State of parse so far: E - E We have a shift-reduce conflict. We have E - E on stack, we see -. What do we do?
Example 2 exp ::= NUM | exp PLUS exp | exp MUL exp | exp MINUS exp | LPAR exp RPAR E E E - NUM NUM yet to read Input from lexer: NUM - NUM - NUM elements parsed so far State of parse so far: E We have a shift-reduce conflict. We have E - E on stack, we see -. What do we do? REDUCE
Example 2 exp ::= NUM | exp PLUS exp | exp MUL exp | exp MINUS exp | LPAR exp RPAR - E E NUM E E - NUM NUM yet to read Input from lexer: NUM - NUM - NUM elements parsed so far State of parse so far: E - E SHIFT SHIFT REDUCE
Example 2 E exp ::= NUM | exp PLUS exp | exp MUL exp | exp MINUS exp | LPAR exp RPAR - E E NUM E E - NUM NUM yet to read Input from lexer: NUM - NUM - NUM elements parsed so far State of parse so far: E REDUCE
Example 2: Summary E exp ::= NUM | exp PLUS exp | exp MUL exp | exp MINUS exp | LPAR exp RPAR - E E NUM E E - NUM NUM yet to read Input from lexer: NUM - NUM - NUM elements parsed so far State of parse so far: E We have a shift-reduce conflict. We have E - E on stack, we see -. What do we do? REDUCE. We ALWAYS want to reduce since – is left-associative.
precedence and associativity • three solutions to dealing with operator precedence and associativity: 1) let Yacc complain. • its default choice is to shift when it encounters a shift-reduce error • programmer intentions unclear; harder to debug other parts of your grammar; generally inelegant 2) rewrite the grammar to eliminate ambiguity • can be complicated and less clear 3) use Yacc precedence directives • %left, %right %nonassoc
precedence and associativity • given directives, ML-Yacc assigns precedence to each terminal and rule • precedence of terminal based on order in which associativity is specified • precedence of rule is the precedence of the right-most terminal • eg: precedence of (E ::= E + E) ==> prec(+) • a shift-reduced conflict is resolved as follows • prec(terminal) > prec(rule) ==> shift • prec(terminal) < prec(rule) ==> reduce • prec(terminal) = prec(rule) ==> • assoc(terminal) = left ==> reduce • assoc(terminal) = right ==> shift • assoc(terminal) = nonassoc ==> report as error yet to read ....................T E input: terminal T next: RHS of rule on stack: ........E % E
precedence and associativity datatype exp = Int of int | Add of exp * exp | Sub of exp * exp | Mul of exp * exp | Div of exp *exp %% %left PLUS MINUS %left MUL DIV %% exp : NUM (Int NUM) | exp PLUS exp (Add (exp1, exp2)) | exp MINUS exp (Sub (exp1, exp2)) | exp MUL exp (Mul (exp1, exp2)) | exp DIV exp (Div (exp1, exp2)) | LPAR exp RPAR (exp)
precedence and associativity precedence directives: %left PLUS MINUS %left MUL DIV yet to read prec(MUL) > prec(PLUS) ....................MUL E input: terminal T next: RHS of rule on stack: ...E PLUS E
precedence and associativity precedence directives: %left PLUS MINUS %left MUL DIV yet to read prec(MUL) > prec(PLUS) ....................MUL E input: terminal T next: RHS of rule on stack: ... E PLUS E SHIFT
precedence and associativity precedence directives: %left PLUS MINUS %left MUL DIV yet to read prec(PLUS) = prec(SUB) ....................SUB E input: terminal T next: RHS of rule on stack: ...E PLUS E
precedence and associativity precedence directives: %left PLUS MINUS %left MUL DIV yet to read prec(PLUS) = prec(SUB) ....................SUB E input: terminal T next: RHS of rule on stack: ...E PLUS E REDUCE
one more example datatype exp = Int of int | Add of exp * exp | Sub of exp * exp | Mul of exp * exp | Div of exp *exp | Uminus of exp %% %left PLUS MINUS %left MUL DIV %% exp : NUM (Int NUM) | MINUS exp (Uminus exp) | exp PLUS exp (Add (exp1, exp2)) | exp MINUS exp (Sub (exp1, exp2)) | exp MUL exp (Mul (exp1, exp2)) | exp DIV exp (Div (exp1, exp2)) | LPAR exp RPAR (exp) yet to read ....................MUL E ...MINUS E what happens?
one more example datatype exp = Int of int | Add of exp * exp | Sub of exp * exp | Mul of exp * exp | Div of exp *exp | Uminus of exp %% %left PLUS MINUS %left MUL DIV %% exp : NUM (Int NUM) | MINUS exp (Uminus exp) | exp PLUS exp (Add (exp1, exp2)) | exp MINUS exp (Sub (exp1, exp2)) | exp MUL exp (Mul (exp1, exp2)) | exp DIV exp (Div (exp1, exp2)) | LPAR exp RPAR (exp) yet to read ....................MUL E ...MINUS E what happens? prec(*) > prec(-) ==> we SHIFT
the fix datatype exp = Int of int | Add of exp * exp | Sub of exp * exp | Mul of exp * exp | Div of exp *exp | Uminus of exp %% %left PLUS MINUS %left MUL DIV %left UMINUS %% exp : NUM (Int NUM) | MINUS exp %prec UMINUS (Uminus exp) | exp PLUS exp (Add (exp1, exp2)) | exp MINUS exp (Sub (exp1, exp2)) | exp MUL exp (Mul (exp1, exp2)) | exp DIV exp (Div (exp1, exp2)) | LPAR exp RPAR (exp) yet to read ....................MUL E ...MINUS E
the fix datatype exp = Int of int | Add of exp * exp | Sub of exp * exp | Mul of exp * exp | Div of exp *exp | Uminus of exp %% %left PLUS MINUS %left MUL DIV %left UMINUS %% exp : NUM (Int NUM) | MINUS exp %prec UMINUS (Uminus exp) | exp PLUS exp (Add (exp1, exp2)) | exp MINUS exp (Sub (exp1, exp2)) | exp MUL exp (Mul (exp1, exp2)) | exp DIV exp (Div (exp1, exp2)) | LPAR exp RPAR (exp) yet to read ....................MUL E ...E MINUS E changing precedence of rule alters decision: prec(-) > prec(*) ==> we REDUCE
the dangling else problem • Grammar: S ::= if E then S else S S ::= if E then S S ::= ... • Consider: if a then if b then S else S • parse 1: if a then (if b then S else S) • parse 2: if a then (if b then S) else S • Parser reports shift-reduce error • in default behavior: shift (what we want)
the dangling else problem • Grammar: S ::= if E then S else S S ::= if E then S S ::= ... • Alternative solution is to rewrite grammar: S ::= M S ::= U M ::= if E then M else M M ::= ... U ::= if E then S U ::= if E then M else U
default behavior of ML-Yacc • Shift-Reduce error • shift • Reduce-Reduce error • reduce by first rule • generally considered unacceptable • for assignment 3, your job is to write a grammar for Fun such that there are no conflicts • you may use precedence directives tastefully
Note: To enter ML-Yacc hell, use a parser to catch type errors • when doing assignment 3, your job is to catch parse errors • there are lots of programming errors that will slip by the parser: • eg: 3 + true • catching these sorts of errors is the job of the type checker • just as catching program structure errors was the job of the parser, not the lexer • attempting to do type checking in the parser is impossible (in general) • why? Hint: what does “context-free grammar” imply?