Download

1 / 31
421 likes | 829 Views
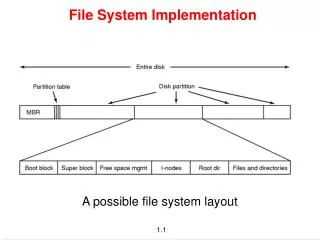
File-System Implementation. Operating System Concepts chapter 11. CS 355 Operating Systems Dr. Matthew Wright. File-System Structure. Two design problems: How should the file system look to the user? How are logical files mapped onto the physical storage devices?

E N D
File-System Implementation Operating System Concepts chapter 11 CS 355 Operating Systems Dr. Matthew Wright
File-System Structure • Two design problems: • How should the file system look to the user? • How are logical files mapped onto the physical storage devices? • Physical storage devices are usually magnetic disks, which are useful for storing multiple files because: • It is possible to read from a disk and write back into the same place that was just read • A disk can directly access any location on the disk (just move the read-write heads and wait for the disk to rotate). • Transfers between memory and disk are performed in units of blocks.
File Systems—Examples general characteristics of some common file systems (particular characteristics depend on implementation)
Layers of File System Abstraction Application Programs Logical File System: manages metadata (all of the file-system structure except the actual contents of files) and directory structure File-Organization Module: translates logical addresses to physical addresses for the basic file system Basic File System: able to issue generic commands to device drivers, manages memory buffers and caches I/O Control: device drivers and interrupt handlers to transfer information between main memory and disk system Storage Devices
File-System Implementation • Implementing a file system requires various memory structures. • On disk, a file system contains: • Boot control blockcontains info needed by system to boot OS from that volume • Volume control blockcontains volume details, such as number of blocks, size of blocks, and count of free blocks • Directory structureorganizes the files • Per-file File Control Block (FCB)contains many details about the file; known as an inodeon most UNIX systems • In-memory data structures • Mount tablecontains information about each mounted volume • Directory cacheholds information about recently-accessed directories • System-wide open file tablecontains a copy of the FCB for each open file • Per-process open-file tablecontains a pointer to the entry in the system-wide open file table for each file the process has open • Buffershold file-system blocks while they are being read from or written to disk
File Open • A file must be opened via the open() system call. • If the file is already in the system-wide open file table, an entry is created in the per-process open file table pointing to the entry in the system-wide table. • Otherwise, the directory is searched for the given file, and the FCB is copied into the system-wide open file table and an entry is created in the per-process open file table. • open() returns a pointer to the entry in the per-process open file table (a file descriptor in UNIX; a file handle in Windows).
File Close • A file is closed via the close() system call. • The entry in the per-process open file table is removed. • The open count in the system-wide entry is decremented. • If all users have closed the file, then the entry in the system-wide open file table is removed.
Partitions and Mounting • Raw disk is used where no file system is appropriate. • UNIX swap space uses a raw partition, and it uses its own format for what it stores in this space. • Some databases uses raw disk and format the data to suit their needs. • Boot information can be stored in its own partition, usually as a series of blocks that are loaded into memory at startup. • Execution starts at a predefined location, where the boot loader is stored. • The boot loader knows enough about the file-system structure to find and load the kernel, and start it running. • In a dual-boot system, the boot loader can also give the user a choice of which operating system to boot. • The root partition, containing the kernel, is mounted at boot time. • Other volumes can be mounted at boot time or later, and the OS determines the file system on each one.
Virtual File Systems • How does an operating system allow multiple types of file systems to be integrated into a directory structure? • Virtual file system (VFS) uses object-oriented techniques to simplify and modularize the implementation. • VFS allows the same system call interface (the API) to be used for different types of file systems. • VFS allows files to be uniquely represented throughout a network.
Directory Implementation • Linear list of file names with pointer to the data blocks. • Simple to program • Time-consuming to execute, since sequential searches are slow • Hash Table: use a hash function to return a pointer to each file in the linear list • Faster than linear list for directory searches • Must make provision for collisions (situations where two file names hash to the same location) • Hash table is usually of some fixed size
Allocation Methods • How do we allocate space for files on a disk? • We desire: • To use disk space efficiently • To be able to access files quickly • Three common methods: • Contiguous allocation • Linked allocation • Indexed allocation
Contiguous Allocation • Each file occupies a set of contiguous blocks on the disk • Advantages: • Simple to read or write a file • Directory is simple • Provides random access within a file • Disadvantages: • Must find contiguous space for each new file • Dynamic storage-allocation problem: use best-fit or worst-fit algorithms to fit files in holes • External fragmentation (defragmentation is costly) • Files cannot grow easily • One solution is to use extents: extra blocks that may be appended to a file and not stored contiguously with the original file
Linked Allocation • Each file is a linked list of disk blocks, which may be scattered on the disk • Directory contains a pointer to the first and last blocks, and each block contains a pointer to the next block • Advantages: • No external fragmentation • Easy to expand the size of a file • Disadvantages: • Not suitable for random access within a file • Pointers take up some disk space • Difficult to recover a file if a pointer is lost or damaged • Blocks may be collected into clustersof several blocks • Fewer pointers are necessary • Fewer disk seeks to read an entire file • Greater internal fragmentation
File-Allocation Table (FAT) • File-allocation table (FAT) is a variant of linked allocation used in MS-DOS and OS/2. • A section of disk at the beginning of each volume contains the allocation table. • Table has one entry per disk block, indexed by block number. • Each entry contains the block number of the next block in the file. • The table can be used to quickly find a block within a file, improving random access time within files. • If the FAT is not cached, the disk heads must move frequently between files and the FAT. • Best performance requires that the entire FAT be in memory. • FAT is efficient for small disks, but not for large disks because the table itself grows very large.
File-Allocation Table (FAT) user directory block allocation table physical blocks on disk
Indexed Allocation • Indexed allocation brings all pointers together into one location called the index block. • Each file has its own index block, which is an array of disk-block addresses (address i is the address of the ith block of the file). • Advantages: • Supports direct access • No external fragmentation • Does not require keeping a large FAT in memory • Disadvantages: • Wasted space within index blocks • Data blocks may be spread all over the volume, resulting in many read/write head movements
Indexed Allocation • How big should the index blocks be? • A small block cannot contain enough pointers for a large file. • A large block wastes space with each small file. • Linked scheme: for large files, link together several index blocks • Multilevel index: a first-level index block points to a set of second-level index blocks, which contain pointers to file blocks. • Combined scheme: Suppose we can store 15 pointers of the index block are stored in the FCB (or inode, on UNIX). • First 12 of these are pointers to direct blocks (that contain file data) • Next 3 are pointers to indirect blocks (that contain pointers) • First points to a single indirect block • Second points to a double indirect block • Third points to a triple indirect block • This allows very large file sizes (UNIX implementations of this scheme support files that are terabytes in size).
Indexed Allocation UNIX inode, illustrating combined indexing
Practice (11.1) Consider a file currently consisting of 100 blocks. Assume that the file-control block (and the index block, in the case of indexed allocation) is already in memory. Calculate how many disk I/O operations are required for contiguous, linked, and indexed (single-level) allocation strategies, if, for one block, the following conditions hold. In the contiguous-allocation case, assume that there is no room to grow at the beginning but there is room to grow at the end. Also assume that the block information to be added is stored in memory. • The block is added at the beginning. • The block is added in the middle. • The block is added at the end. • The block is removed from the beginning. • The block is removed from the middle. • The block is removed from the end.
Practice (11.15) Consider a file system that uses inodes to represent files. Disk blocks are 8-KB in size and a pointer to a disk block requires 4 bytes. This file system has 12 direct disk blocks, plus single, double, and triple indirect disk blocks. What is the maximum size of a file that can be stored in this file system?
Free-Space Management • System maintains a free-space list of free disk blocks. • The free-space list can be stored in various ways • Bit Vector: free-space list is often implemented as a bit vector (or bit map) • Each block is represented by one bit. • If the block is free, the bit is a 1; otherwise the bit is a 0. • Example: 0001 0010 1001 0101 indicates that blocks 3, 6, 8, 11, 13, and 15 are free, and the others are occupied • Advantage: simplicity • Disadvantage: Fast access requires that the bit vector be kept in memory, which could consume many megabytes of memory (32 MB bit map for a 1 TB disk with 4 KB blocks).
Free-Space Management • Linked List: free-space list could be stored as a linked list • Keep the pointer to the first free block in a special memory location • Each free block contains a pointer to the next free block • Advantage: free-space list stored in free space • Disadvantage: finding multiple free blocks is slow • Grouping: pointers to free blocks can be grouped in blocks • If block size is n, then use one block to store the addresses of n – 1 free blocks, followed by the address of the next block of free-block addresses. • Advantage: Addresses of a large number of free blocks can be found quickly • Disadvantage: sequential file data will often be stored in noncontiguous blocks.
Free-Space Management • Counting: • Often, several contiguous blocks are freed simultaneously. • We can store the address of a free block followed by the number of consecutive blocks that are free. • Advantage: Less fragmentation of files; free-space list is shorter • Disadvantage: each free-space entry requires more space; inefficient for fragmented disks. • Space Maps: • Sun’s ZFS file system was designed for huge numbers of large files and directories. • ZFS creates metaslabsto divide disk space into manageable chunks. • Each metaslap has a space map—a log of all block activity. • The log indicates which blocks are free.
Synchronous vs. Asynchronous Writes • Most disks include a cache that stores information read from or to be written to the disk. • Synchronous writes • Are not cached • Are written in the order that they are received • The calling routine waits for the data to reach disk • Useful for database writes and other atomic transactions • Asynchronous writes • Are cached • Are written in any order • The calling routine does not wait • Are most common
Recovering from System Crashes • A system crash that occurs when data is being written to disk (or in cache waiting to be written to disk) can cause inconsistencies among directory structures and FCBs. • Consistency checking • The system can scan the metadata on the file system to check the consistency of the system. • Inconsistencies may or may not be reparable. • Consistency checking can take a very long time. • Many modern file systems are log-based transaction-oriented (or journaling) file systems • All metadata changes are written in a log. • A transaction is considered committed once it is in the log, and the user process may continue executing. • After the transaction is (asynchronously) carried out on disk, the log entry is deleted. • If the system crashes, log indicates transactions to be performed.
Recovering from System Crashes • Network Appliance’s WAFL file system and Sun’s ZFS file system use a different alternative to consistency checking: • The system never overwrites old blocks with new data. • All transactions are written to new blocks. • When the writes are complete, the metadata structures pointing to the old blocks are updated to point to new blocks. • The old blocks are then made available for re-use. • ZFS also provides check-summing of all metadata and data blocks. • ZFS has no consistency checker. • Since all devices eventually fail, backing up files to other storage media is essential for preserving data.
Example: NFS • The Sun Network File System (NFS) is an implementation and a specification of a file system for accessing remote files across LANs. • Allows remote directories to be mounted over local directories • The mount request requires the hostname and directory name for the remote machine. • Mounting is subject to access-rights control. • Once mounted, a remote directory integrates seamlessly into the local file system and directory structure. • NFS protocol provides remote procedure calls (RPCs) for remote file and directory operations.
Example: NFS Three independent file systems on different machines: Cascading mounts: effect of mounting S2:/usr/dir2 over U:/usr/local/dir1 Effect of mounting S1:/usr/shared over U:/usr/local
Example: WAFL • Network Appliance’s WAFL file system is optimized for random writes on network file servers. • WAFL: Write-Anywhere File Layout • Serves files to clients via NFS, CIFS, ftp, and http • File system: • Block-based, with inodes to describe files • All metadata is stored in files: inodes, free-block map, etc. • New data is written to new blocks. • Writes are fast, since • they can occur at the • free block nearest to • the read-write heads.
Example: WAFL • WAFL can easily take a snapshot of the system at any time: • A snapshot involves copying the root inode. • As new data is written, the root inode is updated. • Since blocks are not overwritten, the copy of the root inode preserves the system at the time the copy was made. • What should WAFL do when the disk fills up?