Download

1 / 37
410 likes | 860 Views
Time Series. César Emmanuel Richard Bruno. XML et Data Mining – 2005-2006 Université de Versailles Saint-Quentin en Yvelines. Sommaire. Présentation des Séries Temporelles Définitions & Explications But de l’Analyse Modèles Mathématiques Les Algorithmes Présentation générale

E N D
Time Series César Emmanuel Richard Bruno XML et Data Mining – 2005-2006 Université de Versailles Saint-Quentin en Yvelines
Sommaire • Présentation des Séries Temporelles • Définitions & Explications • But de l’Analyse • Modèles Mathématiques • Les Algorithmes • Présentation générale • Détails de l’ART dans SQL Server 2005 • Détails du modèle ARIMA • Avantages et inconvénients des différents modèles
Présentation des Séries Temporelles XML et Data Mining – 2005-2006 Université de Versailles Saint-Quentin en Yvelines
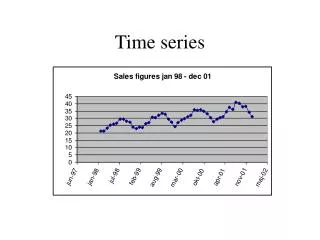
Présentation des Séries Temporelles 1. Définitions & Explications S’intéresser à la « dynamique » d’une variable L’analyse des séries temporelles Définition : La suite d’observations (yt, tЄT) d’une variable y à différentes dates t est appelée série temporelle. Habituellement T est dénombrable, de sorte que t=1…T. Importance de la dimension temporelle La périodicité de la série n’importe pas
Présentation des Séries Temporelles 1. Définitions & Explications Une série temporelle est donc toute suite d’observations correspondant à la même variable : • Macroéconomiques : PIB d’un pays, Inflation, Exportations Ventes d’une entreprise donnée, Nombre d’employés, Revenus d’un individu • Microéconomiques : • Financières : CAC40, Prix d’une option d’achat, Cours d’une action • Météorologiques : Pluviosité, Nombre de jours de soleil par an • Politiques : Nombre de votants, Voix reçu par un candidat • Démographiques : Taille moyenne des habitants, Leur âge Tout ce qui est chiffrable et varie en fonction du temps
Présentation des Séries Temporelles 1. Définitions & Explications Représentation : généralement un graphique de valeurs (ordonnées) en fonction du temps (abscisses) (a) (b) Stationnarité Tendance Saisonnalité (c) (d)
Présentation des Séries Temporelles 2. But de l’Analyse On peut en distinguer 9 principales applications : • Prévoir • Relier les variables • Déterminer la causalité • Étudier des anticipations des agents • Repérer les tendances et cycles • Corriger des variations saisonnières • Détecter les chocs structurels • Contrôler les processus
Présentation des Séries Temporelles 3. Modèles Mathématiques Définition : Le but poursuivi est la formulation d’un modèle statistique qui soit une représentation congruente du processus stochastique qui génère la série observée. Approche : Il est en pratique impossible de connaître la distribution d’une série temporelle {yt}t≥0, on s’intéresse par conséquent à la modélisation de la distribution conditionnelle de {yt} via sa densité : f(yt | Yt-1) Conditionnée sur l’historique du processus Yt-1 = (yt-1, yt-2,…, y0) Il s’agit donc d’exprimé yt en fonction de son passé
Présentation des Séries Temporelles 3. Modèles Mathématiques Résultat : L’approche conditionnelle fournit une Décomposition Prévision Erreur selon laquelle : Yt = E[yt | Yt-1] + εt E[yt | Yt-1] est la composante de yt qui peut donner lieu à une prévision, quand l’historique du processus Yt-1 est connu où εt représente les informations imprévisibles
Présentation des Séries Temporelles 3. Modèles Mathématiques Modèle de séries temporelles 1. Processus autorégressifs d’ordre 1, AR(1) : yt = ayt-1 + εt εt ~WN(0,σ2) (bruit blanc) La valeur de yt ne dépend que de son prédécesseur. Ses propriétés sont fonction de α qui est facteur d’inertie : • α = 0 : yt est imprévisible et ne dépend pas de son passé, on parle de bruit blanc • αЄ ]-1,1] : yt est stable autour de zéro • |α| = 1 : yt est instable et ses variations sont imprévisibles • |α|< 1 : yt est explosif
Présentation des Séries Temporelles 3. Modèles Mathématiques 1. Processus autorégressifs d’ordre 1, AR(1) :
Présentation des Séries Temporelles 3. Modèles Mathématiques 2. Séries Multi variées : 3. Processus autorégressif vectoriel, VAR(1) : 4. Modèle autorégressif à retard distribués, ADL :
Les Algorithmes XML et Data Mining – 2005-2006 Université de Versailles Saint-Quentin en Yvelines
Les Algorithmes 1. Présentation Générale Listing des modèles: • ARIMA (Box & Jenkins) and Autocorrelations • Interrupted Time Series ARIMA • Exponential Smoothing • Seasonal Decomposition (Census1) • X-11 Census method II seasonal adjustement • Distributed Lags Analysis • Single Spectrum (Fourier) Analysis • Cross Spectrum Analysis • Spectrum Analysis • Fast Fourier Transformations
Les Algorithmes 2. Détails de l’ART dans SQL Server 2005 L’algorithme est en fait une version hybride d’autorégression et des techniques d’arbres de décisions. Autorégression 1er étape: La méthode Case Transform : Case Transform
Les Algorithmes 2. Détails de l’ART dans SQL Server 2005 2ème étape: Trouver la fonction f On a : Xt = f(Xt-1,Xt-2,…,Xt-n) + εt Si f est linéaire : Xt = a1Xt-1,+ a2Xt-2+ anXt-n + εt où ai sont les coefficients d’autorégression Pour trouver f trouver les ai Méthode : ajuster les coefficients par un processus de minimisation Abouti a un système d’équations linéaires pour les coefficients an (Yule Walker Equation) Permet le calcul des coefficients grâce a la matrice de covariance =
Les Algorithmes 2. Détails de l’ART dans SQL Server 2005 Autorégression Tree La fonction f correspond a un arbre de régression Représentation :
Les Algorithmes 2. Détails de l’ART dans SQL Server 2005 Saisonnalité Ex : La moyenne des t° en été n’est pas la même qu’en hiver, et le phénomène se répète tous les ans. Comment cela fonctionne dans l’ART: Pendant l’étape « Case Transform », l’algorithme ajoute des points de données basé sur des paramètres de saisonnalité. Paramètre : Periodicity_Hint Avec l’exemple précédent et une période de saisonnalité de 12mois, l’algorithme ajoute dans la table : Lait(t-8x12) … Lait(t-36) Lait(t-24) Lait(t-12) Lait(t0) Pain(t-8x12) … Pain(t-36) Pain(t-24) Pain(t-12) Pain(t0) Note : On peut spécifier plusieurs Periodicity_Hint Note : Détection automatique la saisonnalité basé sur l’algorithme « Fast Fourier Transform » Note : L’algorithme reconnaît les « séries croisées »
Les Algorithmes 2. Détails de l’ART dans SQL Server 2005 Saisonnalité Les principaux paramètres de l’ART: • Minimum_Support • Complexity_Penalty • Historical_Model_Count • Historical_Model_Gap • Periodicity_Hint • Auto_Detect_Periodicity • Maximum_Series_Value • Minimum_Series_Value
Les modèles ARIMA • Présentation : • ARIMA (Auto-Regressive-Integrated-Moving Average) popularisée et formalisée par Box et Jenkins (1976). • Les processus autorégressifs supposent que chaque point peut être prédit par la somme pondérée d’un ensemble de points précédents plus un terme aléatoire d’erreur. • Le processus d’intégration suppose que chaque point présente une différence constante avec le point précédent. • Les processus de moyenne mobile supposent que chaque point est fonction des erreurs entachant les points précédents plus sa propre erreur.
Les modèles ARIMA • Un modèle ARIMA est étiqueté comme modèle ARIMA (p,d,q) dans lequel : • p est le nombre de terme autorégressifs, • d est le nombre de différence, • q est le nombre de moyennes mobiles.
Les modèles ARIMA 2. Les différentes étapes : On part de la série temporelle originale de l’évolution des unités de ventes suivant :
Les modèles ARIMA • Etape 1 : détermination de l’ordre de différenciation Le graphique de la fonction d’auto-corrélation présente une régression lente et linéaire typique de séries non stationnaires : • Or la méthode ARIMA suppose que l’on travaille sur une série stationnaire, c’est-à-dire que la moyenne et la variance soient constantes dans le temps. • On va donc remplacer la série originale par une série de différences adjacentes. • Pour corriger la non-stationnarité des valeurs, on pourra utiliser une transformation logarithmique ou exponentielle.
Les modèles ARIMA On a un écart type important 17.56. Cette série nécessite donc d’être différenciée. Une différenciation d’ordre 1 suppose que la différence entre 2 valeurs successives de y est constante. On utilise donc la fonction suivante : yt - yt-1 = µ + Ɛt où µ est la constante du modèle et représente la différence moyenne en y. Si µ = 0, la série est stationnaire. Une première différenciation avec l’application du modèle ARIMA(0,1,0) donne les résidus suivants : La série semble a peu près stationnaire et l’écart type a été réduit de manière importante : 1.54 au lieu de 17.56.
Les modèles ARIMA Si on essaie une seconde différenciation en appliquant un modèle ARIMA(0,2,0). Les modèles d’ordre 2 ne travaillent plus sur des différences mais sur les différences de différence. On utilisera alors l’équation de prédiction suivante : yt - 2yt-1 + yt-2 = µ + Ɛt ou encore yt = µ + 2yt-1 - yt-2 + Ɛt on obtient les résultats suivants : Cette série montre des signes clairs de sur-différenciation et l’écart type a augmenté de 1.54 à 1.81. Ceci semble indiqué que l’ordre optimal de différenciation pour cette série est de 1. Toute fois ce modèle devra être optimisé par l’ajout des termes AR ou MA.
Les modèles ARIMA • Conclusion intermédiaire : • Un modèle sans différenciation suppose que la série originale est stationnaire. • Un modèle avec une différenciation d'ordre 1 suppose que la série originale présente une tendance constante. • Un modèle avec une différenciation d'ordre 2 suppose que la série originale • présente une tendance variant dans le temps.
Les modèles ARIMA • Etape 2 : détermination des termes AR Analyse basée sur l’examen des fonctions d’auto-corrélation (ACF) et d’auto-corrélations partielles (PACF). Auto-corrélation est la corrélation d’une série avec elle-même selon un décalage défini. • Les modèles autorégressifs supposent que yt est une fonction linéaire des fonctions précédentes • yt = µ + Ф1 yt-1 + Ф2 yt-2 + Ф3 yt-3 + Ɛt • où Ɛ est le choc aléatoire et Ф1, Ф2 et Ф3 sont les coefficients d’auto-régression compris dans l’intervalle ]-1,1[
Les modèles ARIMA Si on ajuste cette série avec un modèle ARIMA(2,1,0) on obtient les fonctions ACF ET PACF suivantes : L’analyse montre que les coefficients AR sont significativement différents de 0 et que l’écart type a été réduit de 10% (1.42 au lieu de 1.54). L’équation de prédiction a donc la forme suivante : yt = µ + yt-1 + Ф1(yt-1 - yt-2) + Ф2(yt-2 - yt-3) avec µ = 0.258178, Ф1 = 0.2524 et Ф2 = 0.195572 Cette équation permet d’établir le graphique de prédictions suivant :
Les modèles ARIMA • Etape 3 : détermination des termes MA Analyse également basée sur l’examen des fonctions d’auto-corrélation (ACF) et d’auto-corrélations partielles (PACF). Les modèles à moyenne mobile suggèrent que la série présente des fluctuations autour d’une valeur moyenne. • yt = µ + θ1Ɛt-1 + θ2Ɛt-2 + θ3Ɛt-3 + Ɛt • où θ1, θ2 et θ3 sont les coefficients de moyenne mobile. • L’analyse des différents résultats va montrer que le modèle le plus pertinent serait un ARIMA(0,2,1) dont l’équation de prédiction serait la suivante : • yt = 2yt-1 - yt-2 – θ1Ɛt-1
Les modèles ARIMA • Conclusion : • Ces deux modèles peuvent ajuster de manière alternative la série de départ. • Le choix d'un ou l'autre modèle peut reposer sur des présupposé théoriques liés au phénomène observé. • La décision n'est pas simple et les cas les plus atypiques requièrent, outre l'expérience, de nombreuses expérimentations avec des modèles différents (avec divers paramètres ARIMA). • Puisque le nombre de paramètres (à estimer) de chaque type dépasse rarement 2, il est souvent judicieux d'essayer des modèles alternatifs sur les mêmes données. • Toutefois, les composantes des séries chronologiques empiriques peuvent souvent être assez bien approchées en utilisant l'un des 5 modèles de base suivants, identifiables par la forme de l'autocorrélogramme (FAC) et de l'autocorrélogramme partiel (FACP).
Comparatif des méthodes XML et Data Mining – 2005-2006 Université de Versailles Saint-Quentin en Yvelines
Comparatif des méthodes La segmentation neuronale Avantages : • aptitude à modéliser des relations linéaires entre les données, • on détermine automatiquement le nombre optimal de segments au lieu de le fixer automatiquement. Inconvénients : • temps d’exécution plus élevé du fait du nombre d’itérations nécessaires pour une bonne segmentation, • se présentent comme des boîtes noires, • les segments sont moins différenciés en taille et en contenu, • un bon apprentissage nécessite un grand échantillon important pour un bon calcul, • les variables doivent être numériques et leurs modalités comprises dans l’intervalle [0,1] ce qui implique une normalisation des données, • très sensibles aux valeurs extrêmes et aux individus isolés.
Comparatif des méthodes La méthode des centres mobiles Avantages : • temps d’exécution proportionnel au nombre d’individus ce qui la rend applicable à de grands volumes de données, • nombre d’itérations nécessaires est faible. Inconvénients : • ne s’applique qu’à des données continues ce qui nécessite des transformations, • absence de solutions optimales mais des meilleures solutions possibles par rapport aux hypothèses d’origine, • le nombre de segments est fixé au départ. Il ya donc un risque qu’on s’éloigne du véritable nuage des individus.
Comparatif des méthodes La méthode des arbres de décision Avantages : • grande compréhensibilité des résultats pour les utilisateurs, • faible dépendance aux valeurs extrêmes ou manquantes, • faible sensibilité au bruit des variables non discriminantes, • permettent de gérer des variables de tout type : continues, discrètes, catégoriques, • certains arbres permettent de traiter un très grand nombre de variables explicatives. Inconvénients : • l’arbre détecte des optimums locaux et non globaux car il utilise les variables séquentiellement et non simultanément. Le choix d’une branche n’est plus jamais remis en cause, • l’apprentissage nécessite un grand nombre d’individus, • la forme des modèles obtenus ne correspond pas forcément à celle de l’échantillon, • les valeurs obtenues ne sont pas uniformément distribuées, • le temps de calcul d’un arbre est long.
Comparatif des méthodes Les méthodes ARIMA Avantages : • modèle de référence dans l’économétrie, • permet de comprendre la signification théorique de différents processus, • faible impact des valeurs extrêmes. Inconvénients : • appropriées que si la série chronologique est stationnaire, • nécessitent au moins 50 observations dans le fichier de données, • nécessite de tester tous les paramètres donc long en terme d’apprentissage.
Conclusion Intérêt des séries temporelles On considère l’intérêt des séries temporelles selon trois perspectives : • descriptive, • explicative, • prévisionnelle.