Download

1 / 1
10 likes | 156 Views
British Society for Proteome Research/European Bioinformatics Institute Meeting ‘From Proteins to Systems’ 27-29 July 2005 Hinxton Hall Conference Centre, Wellcome Trust Genome Campus, Cambridge Proteomics Networks on the World Wide Web Ruth McNally & Peter Glasner

E N D
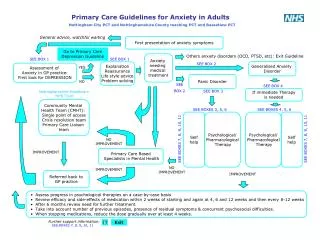
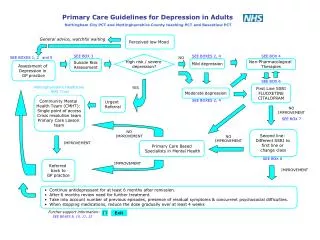
British Society for Proteome Research/European Bioinformatics Institute Meeting ‘From Proteins to Systems’ 27-29 July 2005 Hinxton Hall Conference Centre, Wellcome Trust Genome Campus, Cambridge Proteomics Networks on the World Wide Web Ruth McNally & Peter Glasner Centre for Economic & Social Aspects of Genomics (CESAGen), Cardiff Table 1 shows that the network contains a variety of different types of websites, both in terms of how they are classified on proteomics society website links lists, & in terms of their top level domain. It is notable that there are no .gov nodes. Previous research suggests that the absence of .gov websites – which are typically sources of information about regulation & funding – is typical of a network in its early stages. [vi]It will be interesting to monitor this, especially after the European Proteomics Association (EuPA) becomes active following its first General Council Meeting at HUPO’s 4th Annual World Congress in Munich in August (which appears in the network as hupo2005.com). • CESAGen • The Centre for Economic & Social Aspects of Genomics (CESAGen) is a specialist social science research centre based at Cardiff & Lancaster Universities in the UK. Founded in 2002, it is funded by the Economic & Social Research Council (ESRC), & is part of the ESRC’s Genomic Network. [i] • One of CESAGen’s Flagship Projects studies proteomics using methods & concepts from the field of science & technology studies (STS). [ii] This poster is based on our experiments to map & monitor proteomics on the WWW using the ‘IssueCrawler’, a software tool developed by govcom.org. [iii] Table 1: Nodes in the Network The IssueCrawler The researcher supplies the IssueCrawler with the URLs (website addresses) of at least two ‘Starting Points’. The IssueCrawler: • Crawls the Starting Points & retrieves the outward links. • Performs co-link analysis on the outward links. Co-links become the network nodes. • Analyses the direction and intensity of linking between the nodes. IssueCrawler results can be used to: • Visualise a website’s politics of association: The decision to hyperlink to another website is a conscious decision – the enactment of ‘hyperlink diplomacy’. [iv] Which websites are active linkers? What kinds of websites do they (& don’t they) link to? • Simulate websurfing: Issue Crawler maps simulate journeys that could be taken by someone surfing the WWW from the Starting Points. For the surfer, hyperlinks may be construed as a (dynamic) recommendation that accords the linkee status. Co-linking indicates shared recognition. • Locate networks: Which websites are in the network? Which are out? How does it change over time? Of the proteomics societies whose websites were used as Starting Points, only the website of Korean HUPO failed to pass the co-linking threshold for inclusion in the network. The research initiative nodes are the websites of HUPO’s Brain Proteome Project (hbpp.org) & HUPO’s Proteomics Standards Initiative (psidev.sourceforge.net), which is the only .net website in the network. The websites of the 8 commercial supplier/product websites are typical of .com websites of commercial organisations in that they do not link to any of the other network nodes. At the other extreme, .org websites typically display a more promiscuous linking style, in this network exemplified by the following proteomic society websites: swissproteomicsociety.org, bspr.org, dgpf.org & hupo.org which, respectively, link to 65, 51, 32 & 23 other nodes. With regard to visible politics of association, the hupo.org website only links to proteomics societies which are affiliated to HUPO, & Italy HUPO (hupo.it) & the Italian Proteome Society (ipsoc.it) do not link to each other. Method Starting Points:URLs of the websites of 22 proteomics societies Crawl parameters:Crawl depth – 1; Iterations – 1; Co-link analysis by page; Starting Points not privileged Date:18 July 2005 Figure 2: Cluster map; top 20 nodes; node size is relative centrality (inlinks & outlinks); red nodes give & receive links; green nodes only receive links Figure 1: Cluster map; all nodes; node size is relative to inlinks from the network; node colour corresponds to top level domain of website URL (see legend panel) Figure 2 maps the 20 most significant nodes in the network. In contrast to Fig 1, node size in Fig 2 represents outlinks to other nodes as well as inlinks received. Red nodes give & receive links from the other nodes in Fig 2, whereas green nodes only receive links. Note the much reduced size of asms.org & the other green nodes compared to the red nodes. The size & location of swissproteomicsociety.org reflect its centrality in the network, which is the result of its sociable linking style. Results & Discussion The Issue Crawler identified a heterogeneous network containing 91 nodes that collectively host 100 co-linked webpages. There are 431 directed linkages within the network, but, as Figures 1 & 2 illustrate, these are not evenly distributed. For more information about this research see our forthcoming Viewpoint Article in Proteomics, Issue 12, August, 2005. Acknowledgements: This research is supported by the ESRC at CESAGen, Cardiff. Figure 1is a cluster map where the size of a node is relative to the number of other nodes that link to it. [v] hupo.org, the website of the Human Proteome Organisation (HUPO), is the 2nd largest node in the network. However, the largest node is the website of the American Society for Mass Spectrometry (asms.org) (15 inlinks), which implies that this website enjoys the highest level of status/recognition within the network. However asms.org does not repay the compliment; it links to only one node – imss.nl – the website of the Int’l Mass Spec Society, implying that its politics of association on the WWW are rather different to those of the proteomics society websites that collectively assembled the network nodes. There is a cluster of mass spectrometry society website nodes on the top right hand side of the network, near spectroscopynow.com. Notes [i] www.cesagen.lancs.ac.uk; www.genomicsforum.ac.uk/ESRC_Genomics_Network/index.php [ii] www.cesagen.lancs.ac.uk/research/projects/proteomics.htm [iii] www.govcom.org/about_us.html [iv] Rogers, R. and Marres, N. 2000, Public Understanding of Science 9: 1-23. [v] Cluster map software is ReseauLu, by Andrei Mogoutov, www.Aguidel.com [vi] Rogers, R. 2004, Information Politics on the Web. MIT Press. Further Information Tel: +44(0) 2920 870024 McNallyR@cardiff.ac.uk; www.cesagen.lancs.ac.uk