Download
1 / 20
400 likes | 1.35k Views
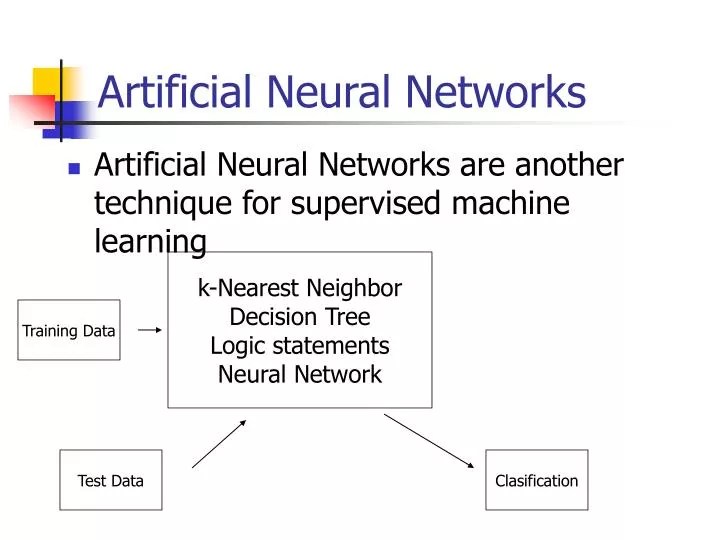
Artificial Neural Networks. Artificial Neural Networks are another technique for supervised machine learning. k-Nearest Neighbor Decision Tree Logic statements Neural Network. Training Data. Test Data. Clasification. Human neuron. Dendrites pick up signals from other neurons

E N D
Artificial Neural Networks • Artificial Neural Networks are another technique for supervised machine learning k-Nearest Neighbor Decision Tree Logic statements Neural Network Training Data Test Data Clasification
Human neuron • Dendrites pick up signals from other neurons • When signals from dendrites reach a threshold, a signal is sent down axon to synapse
Connection with AI • Most modern AI: • “Systems that act rationally” • Implementing neurons in a computer • “Systems that think like humans” • Why artificial neural networks then? • “Universal” function fitter • Potential for massive parallelism • Some amount of fault-tolerance • Trainable by inductive learning, like other supervised learning teachniques
Perceptron Example 1 = malignant 0 = benign # of tumors w1 = -0.1 Output Unit w2 = 0.9 Avg area Avg density w3 = 0.1 Input Units
The Perceptron: Input Units • Input units: features in original problem • If numeric, often scaled between –1 and 1 • If discrete, often create one input node for each category • Can also assign values for a single node (imposes ordering)
The Perceptron: Weights • Weights: Represent importance of each input unit • Combined with input units to feed output units • The output unit receives as input:
The Perceptron: Output Unit • The output unit uses an activation function to decide what the correct output is • Sample activation function:
Simplifying the threshold • Managing the threshold is cumbersome • Incorporate as a “virtual” weight
How do we compute weights? • Initialize all weights randomly • Usually between [-0.5, 0.5] • Put the first point through the network • Actual Output: • Define Error = Correct Output – Actual Output
Perceptron Example 1 = malignant 0 = benign # of tumors w1 = -0.3 w0 = 0 Output Unit w2 = -0.2 Actual Output = 0 Correct Output = 1 Error = 1 – 0 = 1 If input is positive, wantweight to be more positiveIf input is negative, wantweight to be more negative Avg area Avg density w3 = 0.4 Input Units
The Perceptron Learning Rule: How do we compute weights? • Put the first point through the network • Actual Output: • Define Error = Correct Output – Actual Output • Update all weights: • a = learning rate • Repeat with all points, then all points again, and again, until all correct or stopping criterion reached
Can appropriate weights always be found? • ONLY IF data is linearly separable
What if data is not linearly separable? Neural Network. O • Each hidden unit is a perceptron • The output unit is another perceptron with hidden units as input Vj
How to compute weights for a multilayer neural network? • Need to redefine perceptron • “Step function” no good – need something differentiable • Replace with sigmoid approximation
Sigmoid function • Good approximation to step function • As binfinity,sigmoid step • We’ll just take b = 1 for simplicity
Computing weights: backpropogation • Think of as a gradient descent method, where weights are variables and trying to minimize error:
Minimize squared errors • For all training points, let • Tp = correct output • Op = actual output • Want to minimize error • Work with one point at a time, and move weights in direction to reduce error the most
Expand (drop the p for simplicity) • Direction of most rapid positive rate of change (gradient) is given by partial derivative Update rule for hidden layer
Simplify as • Input layer backprop is similar, but requires some more chain rule partial derivatives
Neural Networks and machine learning issues • Neural networks can represent any training set, if enough hidden units are used • How long do they take to train? • How much memory? • Does backprop find the best set of weights? • How to deal with overfitting? • How to interpret results?




















