Download

1 / 89
900 likes | 1.06k Views
Propuestas de una estadística moderna en estudios relacionados con el cambio climático Ana Justel Departamento de Matemáticas Universidad Autónoma de Madrid. Propuestas de una estadística moderna en estudios relacionados con el cambio climático Ana Justel - Universidad Autónoma de Madrid.

E N D
Propuestas de una estadística moderna en estudios relacionados con el cambio climático • Ana Justel • Departamento de Matemáticas • Universidad Autónoma de Madrid
Propuestas de una estadística moderna en estudios relacionados con el cambio climático • Ana Justel - Universidad Autónoma de Madrid En los últimos años la estadística se enfrenta a la necesidad de desarrollar nuevos métodos para extraer la información rápida y eficazmente de grandes bases de datos, pero también que nos permitan aprender de datos problemáticos y escasos.En esta conferencia se presentarán varios problemas reales, relacionados con indicadores para el estudio del cambio climático, que en la mayoría de los casos han motivado el desarrollo de nuevos procedimientos estadísticos. Muchos de los trabajos tienen su origen en el análisis de los datos registrados en la Antártida por el equipo del proyecto Limnopolar, uno de los lugares donde las condiciones de trabajo son más extremas por el aislamiento, la dificultad de acceso y la meteorología. Los problemas estadísticos que trataremos incluyen el concepto de tendencia para datos funcionales en el estudio de series de temperaturas en la región de la Península Antártica, aprovechando datos “defectuosos” y escasos. Cluster de series temporales para agrupar países con intereses comunes frente a los compromisos del Protocolo de Kyoto. Selección de variables en análisis cluster para identificar diferencias en las pautas de consumo eléctrico de los hogares. Detección de cambios de variabilidad en series de temperaturas para predecir indirectamente el momento en que se congela/descongela un lago antártico, y así estimar el número de días con actividad biológica. Estimación robusta de parámetros relacionados con la presencia de especies como bioindicadores. Análisis de la varianza para seleccionar indicadores de impacto en áreas protegidas de la Antártida.
Cluster de series temporales para agrupar países con intereses comunes frente a los compromisos del Protocolo de Kyoto • Selección de variables en análisis cluster para identificardiferencias en las pautas de consumo eléctrico de los hogares • Concepto de tendencia para datos funcionales en el estudio de series de temperaturas en la región de la Península Antártica, aprovechando datos “defectuosos” y escasos • Detección de cambios de variabilidad en series temporales para predecir indirectamente el momento en que se congela/descongela un lago antártico, y estimar el número de días con actividad biológica • Estimación robusta de parámetros relacionados con la presencia de especies como bioindicadores • Análisis de la varianza para seleccionar indicadores de impacto en áreas protegidas de la Antártida
Problemas estadísticos Análisis multivariante Series temporales Cluster de series temporales para agrupar países con intereses comunes frente a los compromisos del Protocolo de Kyoto
Problemas estadísticos Análisis multivariante Series temporales Selección de variables en análisis cluster para identificar diferencias en las pautas de consumo eléctrico de los hogares Datos funcionales
Problemas estadísticos Análisis multivariante Series temporales Concepto de tendencia para datos funcionales en el estudio de series de temperaturas en la región de la Península Antártica, aprovechando datos “defectuosos” y escasos Datos funcionales
Problemas estadísticos Análisis multivariante Series temporales Detección de cambios de variabilidad en series temporales para predecir indirectamente el momento en que se congela/descongela un lago antártico, y estimar el número de días con actividad biológica Datos funcionales Robustez
Problemas estadísticos Análisis multivariante Series temporales Estimación robusta de parámetros relacionados con la presencia de especies como bioindicadores Datos funcionales Robustez
Problemas estadísticos Análisis multivariante Series temporales Análisis de la varianza para seleccionar indicadores de impacto en áreas protegidas de la Antártida Análisis de la varianza Datos funcionales Robustez
Problemas estadísticos Análisis multivariante Series temporales Análisis de la varianza Datos funcionales Robustez
Cluster de series temporales para agrupar países con intereses comunes frente a los compromisos del Protocolo de Kyoto Cluster de series temporales basado en densidades de predicción Andrés M. Alonso Universidad Carlos III de Madrid José Ramón Berrendero Universidad Autónoma de Madrid Adolfo Hernández Universidad Complutense de Madrid Ana Justel Universidad Autónoma de Madrid
Planteamiento del problema Observamos los datos históricos de emisiones de CO2 y queremos clasificar en grupos o “CLUSTERS” a los países Emisiones de CO2 en 24 países industrializados
Planteamiento del problema El objetivo de las técnicas estadísticas de ANÁLISIS CLUSTER o de CONGLOMERADOS es identificar grupos de individuos con características comunes a partir de la observación de varias variables en cada uno de ellos Esta técnica no debe ser confundida con el análisis discriminante y los métodos de asignación, que parten de un conocimiento previo de los grupos (seguimiento de pacientes sometidos que reciben tratamiento o placebo)
Planteamiento del problema Un CLUSTER es un grupo de individuos que, cuando la dimensión lo permite, el ojo humano identifica como homogéneos entre sí y separados de los individuos de los otros clusters
Planteamiento del problema Métodos para encontrar clusters Cluster jerárquico.Se parte de tantos clusters como datos tiene la muestra y en cada paso se van juntando dos clusters siguiendo algún criterio especificado, hasta obtener un único cluster con todos los datos Criterios de optimización.Producen una partición de los objetos en un número especificado de grupos siguiendo un criterio de optimización. El más conocido es k-MEDIAS En general, se buscaHOMOGENEIDADdentro de los gruposyHETEROGENEIDADentre grupos
Planteamiento del problema Observamos series temporales y queremos clasificarlas en grupos o “CLUSTERS” ¿Podemos utilizar las técnicas habituales del análisis multivariante para encontrar los clusters?
Planteamiento del problema • Procedimientos cluster tradicionales ignoran la estructura de autocorrelación de la serie y no proporcionan buenos resultados • Necesidad de desarrollar nuevos procedimientos cluster para series temporales • Algunos trabajos previos se basan en los modelos que generan las observaciones, o en el último dato observado • El problema se complica mucho más con SERIES TEMPORALES MULTIVARIANTES, cuando observamos más de una variable para cada individuo a lo largo del tiempo
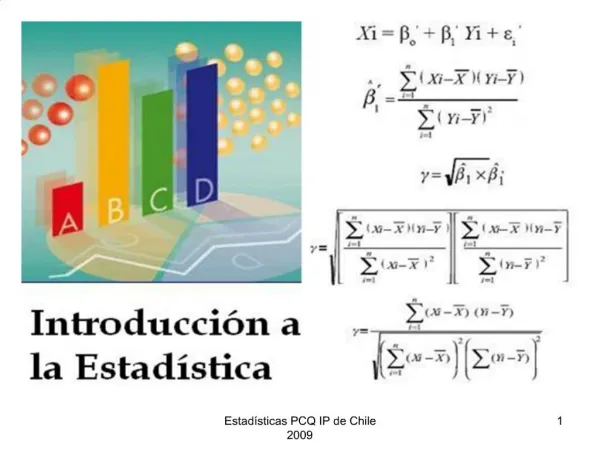
ˆ ˆ ˆ ( ) ( ) ( ) 1 1 1 L X X X + + + , , , 1 T h 2 T h p T h M M O M ˆ ˆ ˆ ( ) ( ) ( ) n n n L X X X + + + , , , 1 T h 2 T h p T h Planteamiento del problema Observamos SERIES TEMPORALES MULTIVARIANTES y queremos clasificarlas en grupos o “CLUSTERS” Proyectamos en el futuro
Planteamiento del problema En muchas situaciones en la vida real, estamos interesados en las PREDICCIONES en un momento específico del futuro Modelo Presente Futuro Los resultados, en general, serán diferentes
Dam construction Planteamiento del problema En muchas situaciones en la vida real, estamos interesados en las PREDICCIONES en un momento específico del futuro Fuente: Manuel Ruiz, UAM Daxi Village, China
Planteamiento del problema • ¿Por qué clusters de predicciones? • Se reduce la dimensionalidad del problema • Se incluye información tanto del presente como del pasado de las series • En muchos problemas, el interés real se centra en el comportamiento futuro ó en si las series convergen o no a un cierto nivel • Desarrollo sostenible • Emisiones de CO2 (Protocolo de Kyoto) • Convergencia económica
Planteamiento del problema Además, nuestro método se basa en clasificar las series por las distancias entre las DENSIDADES DE LAS PREDICCIONES, no sólo en la predicciones puntuales. Esto permite distinguir entre situaciones donde las predicciones puntuales son similares, pero las densidades completas proporcionan más información.
Metodología para clasificar series temporales PASO 1. Calcular las densidades de predicción PASO 2. Calcular la matriz de discrepancias entre las series (usando las densidades de predicción) PASO 3. Aplicar análisis cluster tradicional
Metodología para clasificar series temporales PASO 1. Calcular las densidades de predicción • Si no asumimos ninguna distribución para los datos necesitamos usar métodos de remuestreo (“sieve bootstrap”) para calcular la densidad de predicción • Con el bootstrap extraemos B valores de la distribución de la predicción en el momento específico del futuro que nos interesa • Estimamos la densidad de la predicción aplicando métodos no paramétricos a los B valores bootstrap Se puede desarrollar una versión más sencilla de implementar asumiendo normalidad o basando la agrupación en predicciones puntuales
Metodología para clasificar series temporales Esquema del procedimiento BOOTSTRAP
Estimamos cada distancia con , que se calcula a partir de los estimadores no paramétricos de las densidades de predicción usando la muestra de predicciones bootstrap Hemos probado quees estimador consistente de Dij Hemos hecho unas simulaciones para comparar Dij y Metodología para clasificar series temporales PASO 2. Calcular la matriz de discrepancias (D) • Para cada par de series calculamos la distancia L2 entre las funciones de densidad de las predicciones
Metodología para clasificar series temporales PASO 3. Aplicar análisis cluster tradicional • La matriz de discrepancias obtenida se utiliza como input de un procedimiento cluster • Los métodos jerárquicos se pueden ejecutar conociendo sólo la MATRIZ de DISCREPANCIAS, los que se basan en criterios de optimización no nos sirven
Metodología para clasificar series temporales Criterios para unir grupos en métodos jerárquicos • Enlace sencillo (single linkage): unir por la distancia al individuo más cercano del grupo • Enlace promedio (average linkage): unir por la media de las distancias a todos los individuos del grupo • Enlace completo (complete linkage): unir por la distancia al individuo más alejado del grupo • ...
Metodología para clasificar series temporales Dendograma Los clusters están representados mediante trazos horizontales y las etapas de la fusión mediante trazos verticales {1,2},3,{4,5} ¿Cuántos cluster hay? Tests formales, intuición (conocimiento del problema)
El caso de las emisiones de CO2 Protocolo de Kyoto Impone límites en las emisiones de CO2 y otros cinco gases, “responsables” del calentamiento global. Negociado en Kyoto en 1997, entra en vigor en 2005 con la ratificación de Rusia (cuando es aceptado por los países responsables del 55% de las emisiones a nivel mundial). El objetivo es reducir al menos un 5% (respecto de los niveles de 1990) antes de 2012, pero con objetivos distintos según regiones (UE 8%, Japón 6%) Aplicamos la técnica de CLUSTER PARA SERIES TEMPORALES para crear grupos de países con intereses comunes que puedan compartir experiencias o políticas para alcanzar las reducciones comprometidas
El caso de las emisiones de CO2 Protocolo de Kyoto - Emisiones de CO2 1960-1999 Toneladas per capita En 24 países industrializados
El caso de las emisiones de CO2 Basado en el dato de 1999 Basado en la predicción de 2012
El caso de las emisiones de CO2 Basado en el dato de 1999 Basado en la densidad de la predicción de 2012
El caso de las emisiones de CO2 Protocolo de Kyoto - ¿Cluster con el último dato o con las predicciones?
El caso de las emisiones de CO2 Protocolo de Kyoto - ¿Cluster con el último dato o con las predicciones?
Selección de variables en análisis cluster para identificardiferencias en las pautas de consumo eléctrico de los hogares Selección de variables para análisis cluster Ricardo Fraiman Universidad de San Andrés, Argentina Ana Justel Universidad Autónoma de Madrid Marcela Svarc Universidad de San Andrés, Argentina Data source: Cuesta–Albertos and Fraiman (2006)
Consumo eléctrico en 88 hogares argentinosSe miden 96 variables: consumo de electricidad en intervalos de 15 minutos en un día– Datos funcionalesCuesta–Albertos y Fraiman (2006) encuentran dos clusters con un método k-medias para datos funcionalesEl primer cluster tiene 33 hogares, y el segundo 55
Objetivo Buscamos el subconjunto de variables más pequeño posible que explique las agrupaciones de los datos que hemos encontrado, o un porcentaje alto de ellas. Es habitual que el número de variables, que no debemos confundir con la cantidad de información, sea demasiado elevado. Aplicación Análisis exploratorio de datos. Ayuda a interpretar los cluster que se formanReducir la dimensión. Para nuevos conjuntos de datos
Selección de variables • Trataremos de eliminar variables • “RUIDOSAS”, que son las no informativas • y/o • REDUNDANTES, que no aportan información que no este contenida en otras variables
El método cluster es bueno • Encontrar los grupos con un método cluster El método cluster genera una partición del espacio • Seleccionar las variables “AFTER-CLUSTER” Método de selección de variables Proponemos un método:- consistente estadísticamente- no paramétrico - fácil de usar
Optimizing criteria K-medias Hierarchical clustering
SELECCIÓN DE VARIABLES “AFTER” CLUSTER Probamos a clasificar sólo con las variables de todos los subconjuntos posibles y elegimos el ÓPTIMO: más pequeño y que más explique Cuando se elimina la información de las variables “ruidosas”. Esperamos que NO CAMBIENlos clusters (los datos se quedan en la misma partición) La CLAVE está en tener en cuenta que la partición se define en el espacio de variables original, así que para reasignar los datos a los cluster no puedo eliminar variables aunque sean ruidosasEN LUGAR DE ELIMINAR VARIABLES DEBEMOS “DESACTIVARLAS”
Desactivar variables ruidosas Que una variable sea ruidosa significa que su DISTRIBUCIÓN DE PROBABILIDAD es la misma en todos los clustersEsto nos sugiere “cancelar” el efecto de una variable sustituyendo todos los valores que toma por laMEDIA
Resultados con datos simulados El método para seleccionar variables funciona muy bien para eliminar variables ruidosas, pero es incapaz de detectar variables con información redundante.
Ejemplo con datos simulados Data source: Tadesse, Sha and Vannucci (2005)
Eliminar variables redundantes La extensión más natural es cambiar MEDIAS por MEDIAS CONDICIONALES El mejor predictor de Xi basado en las variables del subconjunto En la practica, calculamos la media condicional con una regresión no paramétrica que hace uso de la información local, de un número de VECINOS MÁS CERCANOS que tenemos que fijar También probamos que este método de selección de variables es consistente
Ejemplo con datos simulados Método basado en la media condicional Data source: Tadesse, Sha and Vannucci (2005)
El método basado en la MEDIA CONDICIONAL sirve para eliminar las variables “RUIDOSAS” y las REDUNDANTES, pero requiere • Un tamaño muestral grande para calcular la esperanza condicionada • Mucho esfuerzo computacional • Elegir el número adecuado de vecinos más cercanos, que es un problema sin resolver El método basado en la MEDIA MARGINAL es más simple.
Consumo de electricidad – Datos funcionales 96 variables: consumo eléctrico en intervalos de 15 minutos en un día Un número demasiado elevado para calcular todas las posibles combinaciones Data source: Cuesta–Albertos and Fraiman (2006) Diseñamos un algoritmo de busqueda forward-backward para encontrar las “ventanas de tiempo” más relevantes para el procedimiento de cluster.
Consumo de electricidad – Datos funcionales Resultados con 100 permutaciones Usar el algoritmo de la media condicionada, en lugar del de la media que es más rápido, significa reduccir del número de intervalos que caracterizan a los dos tipos de consumidores Para calcular la media condicionada, consideramos 5, 10 and 33 vecinos más cercanos