Download
1 / 1
10 likes | 125 Views
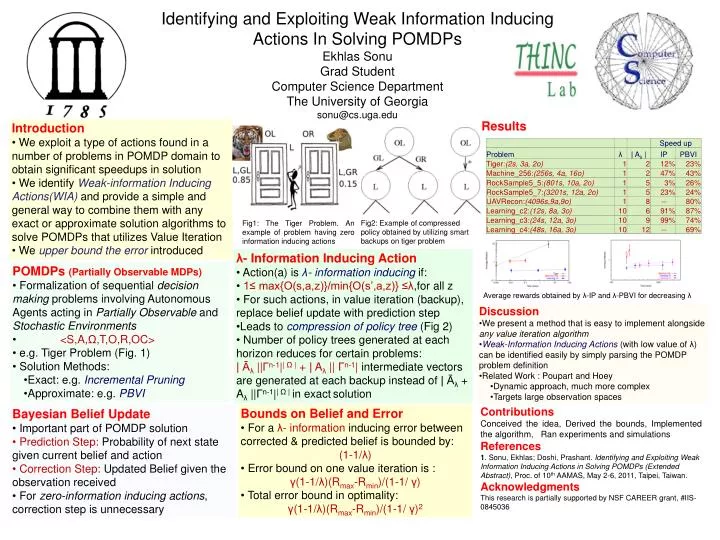
Identifying and Exploiting Weak Information Inducing Actions In Solving POMDPs Ekhlas Sonu Grad Student Computer Science Department The University of Georgia sonu@cs.uga.edu. Results. Introduction

E N D
Identifying and Exploiting Weak Information Inducing Actions In Solving POMDPs Ekhlas Sonu Grad Student Computer Science Department The University of Georgia sonu@cs.uga.edu Results • Introduction • We exploit a type of actions found in a number of problems in POMDP domain to obtain significant speedups in solution • We identify Weak-information Inducing Actions(WIA)and provide a simple and general way to combine them with any exact or approximate solution algorithms to solve POMDPs that utilizes Value Iteration • We upper bound the error introduced Fig2: Example of compressed policy obtained by utilizing smart backups on tiger problem Fig1: The Tiger Problem. An example of problem having zero information inducing actions • λ- Information Inducing Action • Action(a) is λ- information inducing if: • 1≤ max{O(s,a,z)}/min{O(s’,a,z)} ≤λ,for all z • For such actions, in value iteration (backup), replace belief update with prediction step • Leads to compression of policy tree (Fig 2) • Number of policy trees generated at each horizon reduces for certain problems: • |Āλ||Γn-1|| Ω | + |Aλ|| Γn-1| intermediate vectors are generated at each backup instead of |Āλ+ Aλ||Γn-1|| Ω | in exactsolution • POMDPs (Partially Observable MDPs) • Formalization of sequential decision making problems involving Autonomous Agents acting in Partially Observable and Stochastic Environments • <S,A,Ω,T,O,R,OC> • e.g. Tiger Problem (Fig. 1) • Solution Methods: • Exact: e.g. Incremental Pruning • Approximate: e.g. PBVI Average rewards obtained by λ-IP and λ-PBVI for decreasing λ • Discussion • We present a method that is easy to implement alongside any value iteration algorithm • Weak-Information Inducing Actions (with low value of λ) can be identified easily by simply parsing the POMDP problem definition • Related Work : Poupart and Hoey • Dynamic approach, much more complex • Targets large observation spaces • Contributions • Conceived the idea, Derived the bounds, Implemented the algorithm, Ran experiments and simulations • References • 1. Sonu, Ekhlas; Doshi, Prashant. Identifying and Exploiting Weak Information Inducing Actions in Solving POMDPs (Extended Abstract), Proc. of 10th AAMAS, May 2-6, 2011, Taipei, Taiwan. • Acknowledgments • This research is partially supported by NSF CAREER grant, #IIS-0845036 • Bounds on Belief and Error • For a λ- information inducing error between corrected & predicted belief is bounded by: • (1-1/λ) • Error bound on one value iteration is : • γ(1-1/λ)(Rmax-Rmin)/(1-1/ γ) • Total error bound in optimality: • γ(1-1/λ)(Rmax-Rmin)/(1-1/ γ)2 • Bayesian Belief Update • Important part of POMDP solution • Prediction Step: Probability of next state given current belief and action • Correction Step: Updated Belief given the observation received • For zero-information inducing actions, correction step is unnecessary