Download

1 / 24
250 likes | 454 Views
Semi-Sparse Flow-Sensitive Pointer Analysis. Ben Hardekopf Calvin Lin The University of Texas at Austin POPL ’09 Simplified by Eric Villasenor. Overview. Background Flow-Sensitive Analysis Semi-Sparse Flow-Sensitive Analysis Questions. Uses.

E N D
Semi-Sparse Flow-Sensitive Pointer Analysis Ben Hardekopf Calvin Lin The University of Texas at Austin POPL ’09 Simplified by Eric Villasenor
Overview • Background • Flow-Sensitive Analysis • Semi-Sparse Flow-Sensitive Analysis • Questions
Uses • Gather pointer information to improve precision which allows optimizations • Flow sensitive is beneficial for the following • Security analysis • Deep error checking • Hardware synthesis • Multi-threaded programs
Types of Analysis • Types of pointer Analysis • Flow • Consider statement ordering in code • Little progress made in scalability • Context • Consider Procedure calls • Good progress in scalability • Complimentary improvement of precision
Analysis Tradeoffs • Scalability vs Precision • It takes time to analysis code • It takes memory to hold the analysis • Insensitive vs Sensitive • Insensitive less complex/precise • Sensitive more complex/precise • Larger pieces of code in general are complex
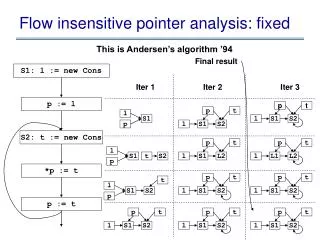
Traditional Flow-Sensitive Analysis • Lattice of dataflow facts • Meet operator on lattice • Transfer functions map lattice elements to other lattice elements • Use CFG = <N,E> • N nodes (program points) • E edges (flow)
Traditional Flow-Sensitive Analysis • Iterative algorithm • Runs until convergence • Adds successor nodes to work list when output set changes • Propagates pointer information to all reachable nodes • Prohibitive in memory and computation complexity
Contributions • Two Ideas • Semi-sparse analysis • Novel use of Binary Decision Diagrams • Two new optimizations • Top-level pointer equivalence • Local points-to graph equivalence
Static Single Assignment w = a; x = b; y = c; z = y; y = d; w1 = a1; x1 = b1; y1 = c1; z1 = y1; y2 = d1; • Def/use relation captured • Let us use it to reduce information sent to nodes w = a; x = b; y = &c; z = y; y = &d; w1 = a1; x1 = b1; y1 = ?; z1 = ?; y2 = ?;
Partial Single Static Assignment • Two classes of variable • Address-Taken • In memory • Use ALLOC/STORE • Top-level • Never expose address • Not dynamically allocated int a, b, *c, *d; int* w = &a; int* x = &b; int** y = &c; int** z = y; c = 0; *y = w; *z = x; y = &d; z = y; *y = w; *z = x; w1 = ALLOCa x1 = ALLOCb y1 = ALLOCc z1 = y1 STORE 0 y1 STORE w1 y1 STORE x1 z1 y2 = ALLOCd z2 = y2 STORE w1 y2 STORE x1 z2
Partial Single Static Assignment • Advantages • Single global points-to graph for top-level variables • They have same pointer information over entire program • Top-level def/use info immediately available • Local points-to graph only contain address-taken information
Dataflow Graph • DFG - combination of sparse evaluation graph (SEG) and def-use chain • Optimized version of CFG • Omits nodes that neither define nor use pointer info • Connects adr-taken statements so defs reach uses • Two stage construction • First DEFadr and USEadr are considered • Second stage connects top-level defs to uses
Dataflow Graph y1 = ALLOCc STORE 0 y1 w1 = ALLOCa x1 = ALLOCb z1 = y1 STORE w1 y1 w1 = ALLOCa x1 = ALLOCb y1 = ALLOCc z1 = y1 STORE 0 y1 STORE w1 y1 STORE x1 z1 y2 = ALLOCd z2 = y2 STORE w1 y2 STORE x1 z2 y2 = ALLOCd STORE x1 z1 z2 = y2 STORE w1 y2 STORE x1 z2
Semi-Sparse Analysis • Each function has program statement work list • Initialized to statements that define variables • Each program statement that uses or defines address-taken variables has two points-to graphs • IN = incoming address-taken info • OUT = outgoing address-taken info • Global points-to graph holds pointer info for top-level variables • Function work list that holds function waiting to be processed • Initialized to contain all functions in program
Semi-Sparse Analysis • Iterative algorithm • Computes for all nodes until convergence • INk = U(x in pred(k)) OUTx • OUTk = GENk U (INk– KILLk) • KILL set determines strong or weak update • Know value of left hand side do strong update • precise • Unsure of left hand side do weak update • conservative
Top-Level Pointer Equivalence • Optimization • Reduces number of top-level variables in DFG • x equiv y iff x points-to z and y points-to z • Key Idea • Replace variables with identical points-to sets with single set representative • Member of the set selected as representative
Top-Level Pointer Equivalence y1 = ALLOCc STORE 0 y1 w1 = ALLOCa x1 = ALLOCb z1 = y1 STORE w1 y1 w1 = ALLOCa x1 = ALLOCb y1 = ALLOCc z1 = y1 STORE 0 y1 STORE w1 y1 STORE x1 z1 y2 = ALLOCd z2 = y2 STORE w1 y2 STORE x1 z2 y2 = ALLOCd w1 = ALLOCa x1 = ALLOCb y1 = ALLOCc STORE 0 y1 STORE w1 y1 STORE x1 y1 y2 = ALLOCd STORE w1 y2 STORE x1 y2 STORE x1 y1 STORE x1 z1 z2 = y2 STORE x1 y1 STORE w1 y2 STORE x1 z2 STORE x1 y2 STORE x1 y2
Local Points-to Graph Equivalence • Optimization • Eliminates nodes in DFG with identical points-to graphs • Share a single points-to graph • Used in SEG portion of graph • Key Idea • Non-preserving nodes • Only STORE and CALL modify adr-taken pointer info. • Preserving nodes • Propagate pointer info to other nodes
Local Points-to Graph Equivalence • Process takes O(n3) • N is the number of nodes in SEG portion of DFG • (DEFadr or USEadr) • Further optimized to only use STORE • 0.1% precision loss • Similar to RTL • STORE to STORE collapsible
BDDs • Compressed representation of set relations • Operations performed without decompression • Set operations can be performed in polynomial-time • Useful to store CFG and points-to graph • Transfer functions are BDD operations • Set operations
Semi-Sparse Symbolic Analysis • Encode top-level points-to information in BDD • Most variables are top-level • BDDs can not operate on individual statements efficiently • Use iterative algorithm for address-taken points-to information • Strong and weak updates • Allows BDD to operate efficiently