Download

1 / 28
330 likes | 830 Views
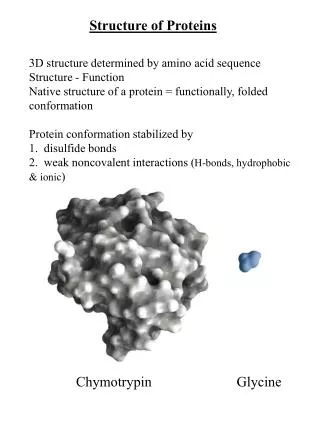
Chap. 4B The Three-dimensional Structure of Proteins. Topics Overview of Protein Structure Protein Secondary Structure Protein Tertiary and Quaternary Structure Protein Denaturation and Folding. Fig. 4-1. Structure of the enzyme chymotrypsin, a globular protein.

E N D
Chap. 4B The Three-dimensional Structure of Proteins • Topics • Overview of Protein Structure • Protein Secondary Structure • Protein Tertiary and Quaternary Structure • Protein Denaturation and Folding Fig. 4-1. Structure of the enzyme chymotrypsin, a globular protein
Fibrous Proteins: Silk Fibroin Fibroins, the proteins of silks, are produced by insects and spiders. Their polypeptide chains are predominantly in the ß conformation. Fibroins are rich in Ala and Gly residues, permitting close packing of ß sheets and an interlocking arrangement of R groups (Fig. 4-14a). The overall structure is stabilized by extensive hydrogen bonding between all peptide linkages in the polypeptides of each ß sheet and by the optimization of van der Waals interactions between sheets. Silk does not stretch because the ß conformation is already highly extended. However the structure is flexible because the sheets are held together by weak interactions rather than by covalent bonds as with the disulfide bonds in -keratins.
Globular Proteins: Myoglobin (I) Myoglobin is a relatively small (Mr 16,700) oxygen-binding protein of muscle cells. It functions to store oxygen and to facilitate oxygen diffusion in contracting muscle tissue. It is particularly abundant in the muscles of diving mammals such as whales, seals, and porpoises. Myoglobin contains a single polypeptide chain of 153 amino acids and a single prosthetic group, iron protoporphyrin (heme) (Fig. 4-16). The same heme group is found in erythrocyte hemoglobin, and is responsible for the deep red-brown color of both myoglobin and hemoglobin. Myoglobin was the first globular protein whose structure was determined by x-ray diffraction. In the diagram in Fig. 4-16, myoglobin structure is represented via ribbon (a), surface contour (b), ribbon plus side-chain (c), and space-filling (d) models.
Globular Proteins: Myoglobin (II) The backbone of myglobin consists of eight relatively straight right-handed helices interrupted by bends, some of which are ß turns (Fig. 4-16a). Seventy-eight per cent of the residues of myoglobin occur in the helical regions (Table 4-4, see below). The heme group is mostly surrounded by the polypeptide chain and sits in a crevice which is barely exposed at the surface of the structure (Fig. 4-16 b & d). Most of the hydrophobic amino acid R groups are in the interior of the molecule, hidden from exposure to water. All but two polar R groups are located on the outer surface of the molecule. The atoms inside myoglobin are densely packed, and thus short-range van der Waals interactions make a significant contribution to stability. All of the peptide bonds are in the planar trans configuration. Three of the four Pro residues are found in bends.
The Heme Group of Myoglobin A heme group is present in myoglobin, hemoglobin, cytochromes, and many other proteins. Heme consists of a complex organic ring structure, protoporphyrin, which binds an iron atom in its ferrous (Fe2+) state (Fig. 4-17a). The iron atom has six coordination positions, four of which are in the plane of the protoporphyrin and bonded to it, and two of which are perpendicular to the ring. In myoglobin and hemoglobin one of the perpendicular coordination positions is bound to a nitrogen atom of a His residue in the polypeptide chain (Fig. 4-17b). The sixth coordination position is open and serves as the binding site for an O2 molecule. It is important that the myoglobin heme group is largely sequestered away from the solvent. The iron of free heme in solution is readily oxidized to the ferric (Fe3+) state, which does not bind O2.
Protein Folding Patterns: Motifs To understand the complete three-dimensional structure of a protein, it is important to analyze its folding pattern. Two terms are used to describe a folding pattern--motif (a.k.a., fold) and domain. A motif is a recognizable folding pattern involving two or more elements of secondary structure and the connections between them. Motifs can be simple, such as the ß--ß loop motif; motifs also can be elaborate, such the ß barrel motif (Fig. 4-18). In some cases a single large motif may comprise the entire protein. Motif and fold can be used interchangeably, however the term fold is more commonly applied to describe more complex folding patterns. For example, the distinctive arrangement of eight helices in myoglobin is found in all globins and is called the globin fold.
Protein Folding Patterns: Domains A domain is a part of a polypeptide chain that is independently stable or could undergo movements as a single entity with respect to the entire protein. Each domain can appear as a distinct globular lobe region as is true for the calcium binding protein of muscle, troponin C (Fig. 4-19). However, extensive contacts can occur between domains and make individual domains hard to discern. The two or more domains of a protein often have different functions, which are coordinated in the overall function of the protein. Small proteins such as myoglobin usually only have one domain.
Protein Folding Patterns: Some Rules Several rules have emerged from studies of common protein folding patterns. 1) Hydrophobic interactions are important for protein stability. At least two layers of secondary structure are required for shielding of hydrophobic residues from water. 2) helices and ß sheets usually are found in different structural layers of a protein. 3) Segments adjacent to each other in the primary structure are usually stacked next to each other in the folded structure. 4) The ß conformation is most stable when the individual strands are twisted slightly in a right-handed sense (Fig. 4-20c).
Large Motifs Can Be Constructed from Smaller Ones Complex motifs can be built up from simpler ones. For example, a series of ß--ß loops arranged so the ß strands form a barrel creates a particularly stable and common motif, the /ß barrel (Fig. 4-21). In this structure each parallel ß segment is connected to its neighbor by an -helical segment.
Structural Classification Via Motifs Based on similarities in tertiary structure, different folding motifs are now grouped into larger classes (e.g., the all class, Fig. 4-22 top). Other classes include the all ß, the /ß (with and ß segment interspersed or alternating), and the + ß (with and ß regions somewhat segregated) (Fig. 4-22, not shown).
Protein Families and Superfamilies Based on motif analysis of many proteins, it now is clear that protein tertiary structure is more reliably conserved than is amino acid sequence. Proteins with significant similarity in primary structure and/or with similar tertiary structure and function are said to be in the same protein family. Proteins within a family are evolutionarily related. Two or more protein families that have little similarity in primary structure but display the same major structural motif are grouped together in a superfamily. An evolutionary relationship among families in a superfamily is considered probable even though time and functional distinctions have erased many of the telltale sequence relationships.
Multisubunit Proteins Many proteins have multiple polypeptide subunits (from two to hundreds). A multisubunit protein is referred to as a multimer. A multimer with just a few subunits is often called an oligomer. The repeating structural unit in such a multimeric protein, whether a single subunit or a group of subunits, is called a protomer. Greek letters are sometimes assigned to distinguish the individual subunits that make up a protomer. Multisubunit proteins have quaternary structure.
Quaternary Structure of Hemoglobin Hemoglobin (Mr 64,500) contains four polypeptide chains with one heme prosthetic group each, in which the iron atoms are in the ferrous (Fe2+) state (Fig. 4-23). The protein portion, globin, consists of two chains (141 residues each) and two ß chains (146 residues each). The subunits of hemoglobin are arranged in symmetric pairs, each pair having one and one ß subunit. Hemoglobin can therefore be described either as a tetramer or as a dimer of ß protomers.
Intrinsically Disordered Proteins As many as a third of all human proteins may be unstructured or have significant content of unstructured segments. These intrinsically disordered proteins have properties that are distinct from classical structured proteins. Namely, they can lack a hydrophobic core, and instead may contain high densities of charged amino acid residues such as Lys, Arg, and Glu. Pro residues are also prominent as they tend to disrupt ordered structures. The lack of an ordered structure can allow a protein to interact with multiple partners. The mammalian protein p53 plays a crucial role in the control of cell division. It features both structured and unstructured segments (Fig. 4-24). An unstructured region at the carboxyl terminus interacts with at least four different binding partners and assumes a different structure in each of the complexes.
Proteostasis The maintenance of an active set of cellular proteins required under a given set of conditions is called proteostasis (Fig. 4-25). Three kinds of processes contribute to proteostasis. First, proteins are synthesized on a ribosome. Second, multiple pathways contribute to protein folding, many of which involve the activity of complexes called chaperones. Chaperones (including chaperonins) also contribute to the refolding of proteins that are partially and transiently unfolded. Finally, proteins that are irreversibly unfolded are subject to sequestration and degradation by several additional pathways. Partially unfolded proteins and protein-folding intermediates that escape the quality control activities of the chaperones and degradative pathways may aggregate, forming both disordered aggregates and ordered amyloid-like aggregates that contribute to disease processes.
Protein Denaturation (I) The conformation of a native protein is only marginally stable. Conditions different from those in a cell, etc., therefore can cause protein structural changes resulting in the loss of three-dimensional structure needed for function (i.e., denaturation). In the denatured state, the conformation of the protein need not be completely randomized. A number of physical and chemical agents can cause protein denaturation. A classic agent is heat, which has complex effects on many weak interactions in a protein (primarily on the hydrogen bonds). On heating, a protein’s conformation generally remains intact until an abrupt loss of structure occurs over a relatively narrow temperature range (the Tm) (Fig. 4-26a). The abruptness of the loss of structure suggests a cooperative process in which loss of structure in one or more parts of the protein rapidly destabilizes the structure of other parts.
Protein Denaturation (II) Proteins also can be denatured by extremes in pH, by miscible organic solvents such as alcohol and acetone, by certain solutes such as urea and guanidine hydrochloride, or by detergents (Fig. 4-6b). None of these agents breaks covalent bonds. Organic solvents, urea and detergents act primarily by disrupting the hydrophobic interactions that produce the stable core of globular proteins. Urea and guanidine hydrochloride also disrupt hydrogen bonds. Extremes of pH alter the net charge on the protein causing electrostatic repulsion and the disruption of some hydrogen bonding. The denatured structures resulting from these various treatments are not necessarily the same. Lastly, denaturation often results in aggregation and precipitation of the unfolded protein. The protein precipitate that is seen after boiling an egg white is a well known example.
Renaturation of Ribonuclease Early studies examining the renaturation (refolding) of the enzyme ribonuclease provided experimental proof that the tertiary structure of a protein is determined by its primary structure (Fig. 4-27). In this experiment, purified ribonuclease was denatured to its unfolded inactive state by exposure to a concentrated solution of urea and the reducing agent, mercaptoethanol. This unfolded the protein and reduced all disulfide cross-links to cysteine residues. When urea and mercaptoethanol were removed, the randomly-coiled, denatured ribonuclease spontaneously refolded to its catalytically active state. Even the protein’s four unique disulfide bonds reformed correctly. This experiment provided the first evidence that the amino acid sequence of a polypeptide chain contains all the information required to fold the chain into its native, three-dimensional structure.
Overview of Protein Folding Protein folding is thought to occur via a hierarchical pathway (Fig. 4-28). Certain amino acid sequences fold first into local secondary structures, guided by constraints discussed earlier in Chap. 4. Assembly of local structures is followed by formation of longer-range interactions between these secondary structure elements to obtain folding motifs described above. Throughout the process hydrophobic interactions play a significant role in aggregating nonpolar amino acid side chains in the core of folding intermediates and the final tertiary structure. Computer programs have now been developed that can often predict the structures of small proteins on the basis of their amino acid sequences.
The Thermodynamics of Protein Folding Thermodynamically, the protein folding process can be viewed as a kind of free energy funnel (Fig. 4-29). The unfolded states (top of funnel) are characterized by a high degree of conformational entropy and relatively high free energy. As folding proceeds, the narrowing of the funnel reflects the decrease in the conformational space that must be searched as the protein approaches its native state (N, at the bottom of the funnel). Small depressions along the sides of the free energy funnel represent semistable intermediates that can slow the folding process. The funnels can have a variety of shapes depending on the complexity of the folding pathway, the existence of semistable intermediates, and the potential for particular intermediates to assemble into aggregates of misfolded proteins.
Chaperones Many proteins do not fold spontaneously as they are synthesized by a cell. The folding of these proteins requires the general class of proteins called chaperones. Chaperones interact with partially folded or improperly folded polypeptides, facilitating correct folding pathways or providing microenvironments in which folding can occur. Several types of chaperones are found in organisms ranging from bacteria to humans. The two major classes of chaperones are the molecular chaperones (e.g., the Hsp70 family of proteins) and chaperonins (e.g., the GroEL/Hsp60 family of proteins). (Hsp stands for heat shock protein. These proteins are induced in bacterial cells by exposure to high temperatures.) Molecular chaperones act as monomers, whereas chaperonins are large multisubunit complexes.
Chaperone-assisted Protein Folding Molecular chaperones such as Hsp70, bind to regions of unfolded polypeptides that are rich in hydrophobic residues. They protect both proteins denatured by heat and newly synthesized and not yet folded proteins from aggregation. They also block the folding of certain proteins that must remain unfolded until they have been translocated across a membrane. Some chaperones also facilitate the quaternary assembly of oligomeric proteins. The Hsp70 proteins bind to and release polypeptides in a cycle that uses energy from ATP hydrolysis and involves several other proteins, such as Hsp40 and NEF (nucleotide-exchange factor) (Fig. 4-30). When the bound polypeptide is released after a cycle of ATP hydrolysis, it has a chance of folding properly. If not, the protein may be bound again, and the process repeated. Hsp70 can also deliver unfolded polypeptides to chaperonins.
Chaperonin-assisted Protein Folding (I) Chaperonins are elaborate protein complexes required for the folding of many cellular proteins that do not fold spontaneously. In E. coli, 10-to-15% of newly translated proteins require the GroEL/GroES chaperonin system for folding under normal conditions. This increases to 30% when cells are subjected to heat stress. The mechanism of protein folding by the GroEL/GroES chaperonin is shown in the next slide (Fig. 4-31). Each GroEL complex consists of two large chambers formed by two heptameric rings. GroES (also a heptamer) blocks one of the GroEL chambers after an unfolded protein is bound inside. The chamber with the unfolded protein is referred to as cis; the opposite one is trans. Folding occurs within the cis chamber during the time it takes to hydrolyze the 7 ATPs that are bound to subunits in the heptameric GroEL ring. The GroES and the ADP molecules then dissociate and the protein is released. The two chambers of the GroEL system alternate in the binding and facilitated folding of client proteins. Inside the chamber, a protein has about 10 seconds to fold. Constraining the protein within the chamber prevents inappropriate protein aggregation and also restricts the conformational space that a polypeptide chain can explore as it folds.
Protein Folding Disorders: Amyloidoses In a number of human disorders (amyloidoses; including Alzheimer disease), a soluble protein that is normally produced by a cell adopts a misfolded state and converts into an insoluble extracellular amyloid fiber (Fig. 4-32a). Commonly, fiber formation is promoted by the aggregation of regions of proteins that have a ß conformation. In Alzheimer disease, proteolytic cleavage of a neuronal membrane protein (amyloid-ß precursor protein, APP) produces an -helical membrane-spanning peptide (amyloid-ß peptide) that converts to the ß conformation and aggregates into amyloid fibrils (Fig. 4-32 b & c). The extracellular deposition of amyloid fibrils is associated with plaque formation and ultimately death of the nearby neurons.
Protein Folding Disorders: Prion Diseases (I) In the neurodegenerative diseases known as spongiform encephalopathies, a misfolded form of a normal neuronal protein PrP is responsible for disease. Spongiform encephalopathies occur in many species of animals. In humans, the disorders are known as kuru and Creutzfeld-Jacob disease. In cows, the disorder is known as mad cow disease. In sheep it is called scrapie, and in deer and elk, it is called chronic wasting disease. The diseased brain becomes riddled with holes (Fig. 1, Box 4-6). Progressive deterioration of the brain leads to a spectrum of neurological symptoms, and is always fatal.
Protein Folding Disorders: Prion Diseases (II) Prion protein (PrP) is a normal constituent of brain tissue in all mammals. The protein is thought to possibly function in cell signaling. Illness occurs when the normal cellular PrP (PrPC) folds into an altered conformation called PrPSc (Sc denotes scrapie) (Fig. 2, Box 4-6). In PrPSc, part of the -helical region of PrPC is converted to the ß conformation. PrPSc monomers then associate forming amyloid-like ß sheets. Importantly, the interaction of PrPSc with PrPC converts the latter to PrPSc, initiating a domino effect in which more and more of the brain protein converts to the disease-causing form. For this reason PrPSc is infectious. The mechanism by which PrPSc leads to spongiform encephalopathy is not understood. In inherited forms of prion diseases, a mutation in the gene encoding PrP produces a change in one amino acid residue that is believed to make the conversion of PrPC to PrPSc more likely.