Download

1 / 37
370 likes | 544 Views
Predictable Implementation of Real-Time Applications on Multiprocessor Systems-on-Chip. Alexandru Andrei. Embedded Systems Laboratory Linköping University, Sweden. GSM Phone: Search Radio Link Control Talking. MP3 player. Digital Camera: Take Photo Restore Photo. High performance

E N D
Predictable Implementation of Real-Time Applications on Multiprocessor Systems-on-Chip Alexandru Andrei Embedded Systems Laboratory Linköping University, Sweden
GSM Phone: • Search • Radio Link Control • Talking MP3 player • Digital Camera: • Take Photo • Restore Photo ... • High performance • Low power • Predictable
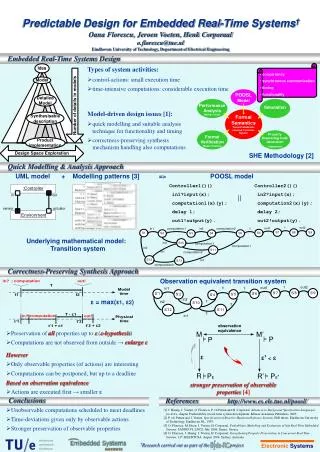
t0 ASIC0 CPU0 t1 t2 dl Bus CPU1 t3 t4 Extract Task Graph t5 dl • Worst case • execution times • Task power Formal Extract Task Parameters for (i=0;i<99;i++) x=x+a[i]; Simulation for (j=0;j<100;j++) y=y+b[i]; if (x<y)z=y; Optimize Implement Design Flow Hardware platform Software Application(s) for (i=0;i<99;i++) x=x+a[i]; for(j=0;j<100;j++) y=y+b[i]; if (x<y)z=y; Extract Task Parameters Optimize
t0 t1 t2 dl t3 t4 t5 dl Application Model
Hardware Architecture Interrupt Device CPU CPU CPU CACHE CACHE CACHE Bus Private Memory Private Memory Private Memory Semaphore Device Shared Memory
Private Mem1 CPU1 t1: Instructions t1 comp(x) copy(x,s) x Cache Cache Shared Mem CPU2 Private Mem2 t2: copy(s,y) Instructions t2 use(y) y BUS Execution Model t1 s t2 Original TG
ti ti twi Explicit communication trj tj tj Original TG Extended TG Task Model
CPU1 PMem1 t1 t1 t2 ShMem Bus CPU2 t2 PMem2 twi twi twi Motivational Example WCET: t1=60; t2=25; tw2=12 t1 andt2 have a deadline at time 63
M1 M3 M5 M2 M4 I5 tw2 I2 I4 I1 I3 Explicit communication Implicit communication Motivational Example (2) dl=63 t1 CPU1 0 6 9 15 33 39 57 t2 tw2 CPU2 24 36 0 6 11 17 BUS
Motivational Example (3) dl=63 Deadline violation ! M5 t1 M1 M3 CPU1 0 6 9 18 36 49 67 M2 M4 t2 tw2 CPU2 24 43 0 12 17 31 I5 tw2 I1 I2 I3 I4 BUS 24 31 43 49 0 6 12 18 Using a FCFS bus arbiter
Motivational Example (4) dl=63 t1 M1 M3 M4 CPU1 0 6 9 18 33 39 57 M2 M4 t2 tw2 CPU2 26 39 0 12 17 32 tw2 I5 I1 I3 I4 I2 BUS 26 39 21 32 49 0 6 9 15 Using a bus schedule
Motivational Example Message In multiprocessor systems, the WCET depends on the bus load! In multiprocessor systems, the WCET depends on the schedule ! In multiprocessor systems, the schedule depends on the WCET!
Implicit Communication Setup: ARM7 cores, ST bus protocol 1) Icache: 4096b, Dcache: 1024b 2)Icache: 4096b, Dcache: 1024b 3)Icache: 16b, Dcache: 256b
WCET Analysis • Difficult both for single and multiprocessor systems • Single processor tools: Symta/P, Absint aiT • Handle instruction and data caches • Basic idea: enumerate all the possible paths of the program (CFG) and consider always the longest one
WCET Analisys Flow source files Abstract syntax tree CFG construction binary file generation Instr. address extraction Data address Data dependency extraction analysis Program segment Data flow simulation Data flow analysis analysis Instr. Cache analysis Data cache analysis Data cache Instruction cache analysis analysis Annotated CFG WCET
WCET Analysis: Example void foo() { int i, temp; for (i=0; i<100; i++) { temp=a[i]; a[temp]=0; } }
WCET Analysis: CFG id: 2 1:void foo() { 2: int i, temp; 3: for (i=0; 4: i<N; 5: i++) { 6: temp=a[i]; 7: a[temp]=0; 8: } 9:} id: 17 Lno:3,4,9 id: 12 Lno:3,4,6 id: 4 id: 16 Lno:6,7,5,4,8 id: 13 Lno:6,7,5,4,6 id: 11
id: 2 id: 17 Lno:3,4 id: 12 Lno:3,4 id: 4 id: 4 Loop bound (for ex. N=100) id: 16 Lno:6,7,5,4,8 id: 13 Lno:6,7,5,4,6 id: 11 WCET Analysis: CFG Control nodes: 2, 4, 11 Basic blocks: 12, 17, 13, 6
WCET Analysis with Instruction Cache • Generate the address traces for each program block • Assume always a miss at the beginning of each block • Use a cache simulator to get the cache rate/miss ratio for each block • We can do better
WCET Analysis with ICache: Unrolled CFG id: 2 id: 17 Lno:3,4 id: 12 Lno:3,4 1:void foo() { 2: int i, temp; 3: for (i=0; 4: i<100; 5: i++) { 6: temp=a[i]; 7: a[temp]=0; 8: } 9:} id: 4 id: 13 Lno:6,7,5,4,6 id: 16 Lno:6,7,5,4,8 id: 104 id: 11 id: 13 Lno:6,7,5,4,6
miss lno 3 (i) miss lno 3 (d) lno 3 miss lno 4 (i) lno 4 miss lno 6 (i) miss lno 6 (d) lno 6 miss lno 7 (i) miss lno 7 (d) lno 7 miss lno 5 (i) lno 5, 4 miss lno 6 (d) lno 6 miss lno 7 (d) lno 7, 5, 4 WCET Analysis with ICache: Unrolled CFG id: 2 id: 17 Lno:3,4 id: 12 Lno:3,4 id: 4 id: 13 Lno:6,7,5,4,6 id: 16 Lno:6,7,5,4,8 id: 104 id: 11 id: 13 Lno:6,7,5,4,6
WCET Analysis: Multiprocessor • Cache miss penalty is constant in single processor case • Cache miss penalty is variable in the multiprocessor case
Predictable MPSoC Bus Access • Partition the bus period in bus slots (TDMA) • Assign bus slots to the processors • The bus arbiter grants the bus to a processor only during its allocated slots • Eliminates the bus interference • Not flexible: an idle bus slot can not be used by another processor
Analysis & Bus Access id: 2 miss lno 3 (i) id: 17 Lno:3,4 id: 12 Lno:3,4 miss lno 3 (d) lno 3 miss lno 4 (i) lno 4 id: 4 miss lno 6 (i) miss lno 6 (d) lno 6 id: 13 Lno:6,7,5,4,6 miss lno 7 (i) id: 16 Lno:6,7,5,4,8 miss lno 7 (d) lno 7 miss lno 5 (i) lno 5, 4 id: 104 id: 11 miss lno 6 (d) id: 13 Lno:6,7,5,4,6 lno 6 miss lno 7 (d) lno 7, 5, 4 Bus schedule ... CPU2 CPU2 CPU2 CPU1 CPU1 CPU1 24 32 42 52 8 16 0
Multiprocessor Analysis and Optimization In multiprocessor systems, the WCET depends on the schedule ! In multiprocessor systems, the schedule depends on the WCET!
t3 t5 t4 t4 t4 t4 t4 t4 t4 t1 t1 t1 t2 t2 t2 t2 t2 t3 t3 t5 t5 t3 t5 Overall Approach CPU1: t1, t4 CPU2: t2 CPU3: t3 , t5 CPU1 t2 CPU2 t5 CPU3 BUS
Overall Approach q=0 Schedule new task at q time t>= Y is the set of all tasks that are active at time t Select bus schedule B for the time interval New task to schedule starting at t Bus schedule optimization Determine WCET of the tasks from set Y q is the earliest time finishes Y a tasks from set
Overall Approach q=0 Schedule new task at q time t>= Y is the set of all tasks that are active at time t Select bus schedule B for the time interval New task to schedule starting at t Bus schedule optimization Determine WCET of the tasks from set Y q is the earliest time finishes Y a tasks from set
Bus Schedule: BSA1 ... CPU1 CPU2 CPU2 CPU1 t0 t1 t3 t2 t4 slot_start owner t0 CPU1 t1 CPU2 over a period t2 CPU1 t3 CPU2 ... ...
Bus Schedule: BSA2 CPU1 CPU2 ... CPU2 CPU1 CPU2 CPU1 t0 t4 t5 t3 t1 t6 t2 Segment 1 Segment 2 seg_size seg_start owners t0 12 1, 2 owner size CPU1 1 CPU2 3 over a period seg_size seg_start owners t4 7 2, 1 owner size CPU1 2 CPU2 5 ... ...
Bus Schedule: BSA3 CPU1 CPU2 CPU1 CPU2 CPU2 CPU1 ... t0 t4 t5 t3 t1 t6 t2 Segment 1 Segment 2 owners slot_size seg_start t0 1, 2 3 over a period t4 6 2, 1 ... ... ...
Experimental Results 4 BSA1 BSA2 3.5 BSA3 BSA4 3 Normalized Schedule Length 2.5 2 1.5 1 2 4 6 8 10 12 14 16 18 20 Number of CPUs
3.5 5.0 4.0 3.0 2.6 3 2.2 1.8 1.2 1.0 2.5 2 1.5 1 2 4 6 8 10 Experimental Results Normalized Schedule Length Number of CPUs
Real-life Example • Smart phone • GSM voice codec (encoder+decoder) and Mp3 player • 64 tasks, between 100-2000 lines of C code per task • 4 ARM7 processors, interconnected via a bus
Real-life Example • GSM + Mp3 • 64 tasks • 4 ARM7 processors
Conclusions • Realistic model for MPSoC • WCET analysis must be integrated in the system scheduling • Tool for system level scheduling and WCET • Tested on real applications
ARTIST TU Brauschweig U. of Bologna Original SymtaP code Bus controller Implementation LiU