Download

1 / 63
700 likes | 1.05k Views
Maschinelles Lernen. Prof. Dr. Katharina Morik Universität Dortmund Fachbereich Informatik Lehrstuhl Künstliche Intelligenz. Maschinelles Lernen steckt in…. Google interessante Webseiten finden -- aus den Verweisen von Webseiten lernen

E N D
Maschinelles Lernen Prof. Dr. Katharina Morik Universität Dortmund Fachbereich Informatik Lehrstuhl Künstliche Intelligenz
Maschinelles Lernen steckt in… • Googleinteressante Webseiten finden-- aus den Verweisen von Webseiten lernen • AmazonBücher, CDs, DVDs empfehlen-- aus dem Kaufverhalten von Kunden lernen • PostsortierungHandschriften erkennen • Marketinggute/schlechte Kunden finden
Aber was ist maschinelles Lernen? • “Lernen ist jeder Vorgang, der ein System in die Lage versetzt, bei der zukünftigen Bearbeitung der selben oder einer ähnlichen Aufgabe diese besser zu erledigen.” Herbert Simon 1983 • Ist das Lernziel immer, eine Aufgabe besser zu erledigen? • Gibt es Lernen ohne Ziel? • Hat man gelernt, wenn man ein besseres Hilfsmittel benutzt? • Insbesondere kann man nichts lernen, wenn man schon alles kann.
Was ist denn Lernen beim Menschen? • Auswendig lernen • Einüben • Logisch schließen • Alle Menschen sind sterblich. Sokrates ist ein Mensch. Sokrates ist sterblich. • Sokrates, Uta, Udo, Veronika, Volker, … sind Menschen und sterblich.Alle Menschen sind sterblich. • Begriffe bilden • Theorien entwickeln, Gesetze formulieren
Eins von diesen Dingen gehört nicht zu den anderen! Dies sind Tassen: Dies sind keine Tassen: Begriffe bilden
Alles zusammenfassen zu einer Klasse, was gemeinsame Merkmale hat. Bedarf für Kategorisierung: Es gibt schon ein Wort dafür Vorhersage ist nötig Begriff erleichtert die Definition anderer Begriffe Begriffsbildung: 1. Kategorisierung
Begriffsbildung: 2. Charakterisierung Kategorien abgrenzend beschreiben • für Gegensätze dieselben Merkmale verwenden • so wenig Merkmale wie möglich • Vererbbarkeit der Merkmale • Operationalität der Merkmale Merkmale: Farbe: blau, weiß, schraffiertForm: rund, kreuzAnzahl: 1, 2, 3 Teilobjekte - + - a) blau, b) besteht aus 2 Teilobjekten, c) blau und besteht aus 2 Teilobjekten
3. Anwendung des Begriffs = Klassifikation a) ist blau: - b) besteht aus 2 Teilobjekten: + c) ist blau und besteht aus 2 Teilobjekten: - a) ist blau: + b) besteht aus 2 Teilobjekten: - c) ist blau und besteht aus 2 Teilobjekten: -
Aha • Begriffe bilden ist eine Lernaufgabe, die Menschen können. • Das ist nützlich, um Dinge zu klassifizieren. • Verallgemeinerung: • Tassen, • abstrakte Formen, • sympathische Menschen, • gute Kunden das Prinzip des Lernens ist das selbe. • Können wir das formal beschreiben?
Maschinelles Lernen • Unüberwachtes Lernen:Clustering ~ KategorisierungSpezialfall: eins von diesen Dingen gehört nicht zu den anderen. • Überwachtes Lernen:Lernen aus Beispielen ~ Charakterisierung
Lernmenge/Testmenge • Lernmenge: Menge von Beispielen = klassifizierte Beobachtungen • Lernen einer Definition(Funktion) • Testmenge: Menge von Beispielen, bei denen die tatsächliche Klassifikation mit der von der Definition vorhergesagten verglichen wird - + -
a) ist blau: korrekt und vollständig b) besteht aus 2 Teilobjekten: nicht korrekt nicht vollständig c) ist blau und besteht aus 2 Teilobjekten: korrekt unvollständig korrekt, vollständig korrekt ist eine Definition, wenn sie kein negatives Beispiel abdeckt; vollständig ist eine Definition, wenn sie alle positiven Beispiele abdeckt - + - + -
- + - + Wahrscheinlichkeit • Raum, aus dem die Beispiele kommen • Verteilung der Zielwerte darin - …
pi 1 0,5 0 Y - + D 1 0,5 0 0,3 0,5 0,7 Wahrscheinlichkeitsverteilung • D: Verteilung von Ydiskrete Zufallsvariable • Verteilungsfunktion f. diskrete Zufallsvariable • Bei zwei Werten alsoDY = p+ + p- Bei stetigen Zufallsvariablen ist die Ableitung der Verteilungsfunktion die Dichtefunktion.
Problem • Wir haben nur die Häufigkeit von Zielwerten in unserer Beispielmenge. • Die wahre Verteilungsfunktion ist uns unbekannt. • Den wahren Fehler ED [Q(h(x),y)] kennen wir nicht -- erwarteter (durchschnittlicher) Fehler, wenn die Instanzen gemäß D gewählt werden. • Wir nehmen an, dass in der Testmenge die selbe (unbekannte) Verteilung gilt. • Wir minimieren wenigstens den empirischen (beobachteten) Fehler.
Kreuzvalidierung • Man teile alle verfügbaren Beispiele in n Mengen auf, z.B. n= 10. • Für i=1 bis i=n: • Wähle die i-te Menge als Testmenge und • die restlichen n-1 Mengen als Lernmenge. • Messe Korrektheit und Vollständigkeit auf der Testmenge. • Bilde das Mittel der Korrektheit und Vollständigkeit über allen n Lernläufen. • Das Ergebnis gibt die Qualität des Lernergebnisses an.
Funktionslernen aus Beispielen • Sei: • X: Raum möglicher Instanzenbeschreibungen • D: Wahrscheinlichkeitsverteilung auf X P (X) • Y: Menge von Zielwerten • H: Menge zulässiger Funktionen, Hypothesensprache LH • Gegeben: • Menge E von Beispielen (x,y) aus X x Y mit f(x)=y • Ziel: • Eine Funktion h(X) aus LH, die das Fehlerrisiko minimiert
Minimierung des beobachteten Fehlers • Da wir die tatsächliche Funktion f(X) nicht kennen, können wir nur eine hinreichend große Lernmenge nehmenund für diese den Fehler minimieren. empirical risk minimization • Wir können auch noch strukturelle Aspekte als zweites Optimierungsziel hinzunehmen, z.B. die Komplexität der Hypothese structural risk minimization
Klassifikation, Regression Zwei Spezialisierung des Funktionslernens: • Klassifikation: die Zielvariable ist diskret, typischerweise Boolean. • Regression: das Ziel ist eine reelle Variable.
Fehler • Fehlerrisikop(xi) Wahrscheinlichkeit, dass das Beispiel xi aus X gezogen wird. • Quadratischer Fehler (numerische Zielwerte) • 0-1-Verlust
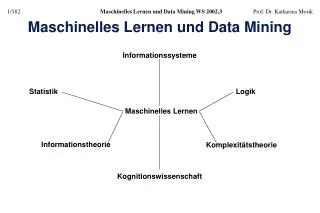
Was wissen wir jetzt? • Wir haben die Lernaufgaben Klassifikationslernen (Begriffslernen) und Regression als Spezialisierungen des Funktionslernens aus Beispielen (Funktionsapproximation) definiert. • Der Bezug zur Statistik wurde durch die Verteilung der Zielvariablen hergestellt. Gebraucht wurde dies für den empirischen Fehler. • Der Bezug zur Logik wurde durch die binäre Zielvariable (+ wahr, - falsch) und die Hypothesensprache des Beispiels hergestellt.
Übersicht über die Vorlesung • Lernaufgaben: • Klassifikation • (Regression) • Häufige Mengen finden • Subgroup detection und Regellernen • Clustering • Paradigmen der Lernbarkeit (Lerntheorie) • Lernen als Suche • Induktive Logische Programmierung • PAC-learning • Statistische Lerntheorie
Übersicht (cont’ed) • Lernverfahren: • Top Down Induction of Decision Trees Begriffslernen • kNN Begriffslernen • Apriori Finden häufiger Mengen • FPgrowth “ • Winepi (zeitlich) “ • Least general generalization “ • Generalisierte -Subsumtion “ • RDT, RDT/dm Regellernen • STT Lernen eines Verbands • Kluster “ • SVM “ • K-Means Clustering
Übersicht (cont’ed) • Anwendungen: • Ökologische Klassifikation von Pflanzenstandorten • Warenkörbe • Tag-Nachtzyklus – Erklärungen von Kindern • Intensivmedizin • Textklassifikation • Musikklassifikation
Übersicht (cont’ed) • Ihr Lernziel: • Algorithmen verstehen – Prinzipien erkennen • Dafür muss man mal etwas selbst implementieren. • Algorithmen anwenden • Wann ist ein Algorithmus gut geeignet? • Mit welchen Parametereinstellungen? • Anwendungen modellieren • Dazu gehört mehr als ein Lernverfahren, nämlich Repräsentation für X und LH, Vorverarbeitung…
Leistungsnachweis • Diese Vorlesung mit Übungen ist eine Prüfungs-vorbereitung, falls Sie als Prüfungsthema ML wählen.Kommen Sie und fragen Sie, falls etwas unklar ist! • ML lässt sich kombinieren mit IS, DM, GS • Die Übungen sollen alle versucht werden. Es müssen 80% der Punkte erreicht werden, um einen Schein zu bekommen.
Maschinelles Lernen -- Prozess • Daten auswählen (sampling) • Training- und Testmenge erstellen (Kreuzvalidierung) • Geeignete Repräsentation für Beispiele erstellen • Merkmalsauswahl • Merkmalsextraktion … • Lernverfahren auswählen und Parameter einstellen • Gütekriterium • Modell auf Testdaten anwenden • Ergebnisse anschauen • Performanz gemäß Gütekriterium
Instanzbasiertes Klassifizieren • Alle Beispiel werden abgespeichert. • Geschickt indexieren? • Typische Beispiele auswählen? • Zu einem neuen Beispiel xnew aus der Testmenge werden die ähnlichsten Beispiele gesucht • Ähnlichkeitsmaß? und gemäß einer Entscheidungsfunktion • Maximum, Mehrheit, Mittelwert? aus deren Klasse(n) die Klasse von xnew ermittelt.
kNN, diskret (Mehrheitsentscheidung) • Sei N die Teilmenge von E mit Kardinalität k, die die zu xnew nächsten Nachbarn enthält, und Nyj:={e=(x,yj) N} diejenigen, die für yj stimmen: • Gegeben Beispiele E, ein neues Beispiel xnew, eine natürliche Zahl k und eine Ähnlichkeitsfunktion sim, dann ist • Die kNN-Vorhersage:
kNN, kontinuierlich (Mittelwert) • Sei N wie eben, aber y eine reelle Zahl. • Gegeben E, xnew, k, sim (wie eben), dann ist • Die kNN-Vorhersage:
Ähnlichkeit – Distanz -- Metrik • Normieren auf [0,1]! • dist (x1, x2) = 1- sim (x1, x2) • Eine Metrik erfüllt die Bedingungen: • Metrik (x,x) = 0 • Metrik(x1, x2) = Metrik(x2, x1) • Metrik (x1,x2) Metrik (x1, x3)+Metrik(x2,x3) x2 x3 x1
Ähnlichkeitsfunktion für Attribute • Ein Beispiel hat die Attribute A1,..., Am, wobei x[i] den Wert des Attributs Ai bezeichnet. • Bei diskreten (nominalen) Attributen A:simAi(x1[i], x2[i]):=1, falls x1[i]=x2[i], sonst 0. • Bei numerischen Attributen, die in den Beispielen mit minimalem Wert minA und maximalem Wert maxA vorkommen:
Ähnlichkeitsfunktion für Beispiele • Seien x1, x2 X mit den Attributen A1, ..., Am und w1, ..., wm nicht negative reelle Zahlen (Gewichte). • Die Ähnlichkeit zweier Beispiele ist definiert als: • Wie finden wir geeignetes k und geeignete Gewichte?
Parameterbestimmung • Für jedes in Frage kommende k mache einen Lernlauf mit n-facher Kreuzvalidierung (bei n Beispielen: leave-one-out) und setze k auf den Wert, bei dem der kleinste Fehler herauskam. • Gewichte die Attribute am höchsten, • die am besten mit y korrelieren oder • den höchsten Informationsgehalt bezüglich y besitzen. • Lerne die Gewichte bei der Kreuzvalidierung: • Stimmt die Klassifikation von xnew nicht, erhöhe die Gewichte derjenigen Attribute, in denen sich xnew von den k nächsten Nachbarn unterscheidet. • Später bei der SVM mehr dazu!
Was wissen wir jetzt? • Eine Idee von Lernen vergleicht alle bisher gesehenen Beispiele mit dem neuen und klassifiziert entsprechend den k ähnlichsten. • Entscheidend ist dabei • das Ähnlichkeitsmaß (Euklid Abstand), • die Gewichtung der Attribute und • die Entscheidungsfunktion. • Kreuzvalidierung kann zum Setzen von k und den Gewichten verwendet werden.
Klassifizieren mit Entscheidungsbäumen Feuchte trocken feucht Temp Säure basisch neutral alkalisch ≤9 >9 Temp Temp +-+ ≤3,5 >3,5 ≤7,5 >7,5 - + + - Bodenprobe: trocken, alkalisch, 7 wird als geeignet klassifiziert (+) Bodeneignung für Rotbuchen
Lernen aus Beispielen Ohne weiteres Wissen können wir als Vorhersage immer - sagen. Der Fehler ist dann 8/16.
Aufteilen nach Bodenfeuchte Feuchte trocken feucht 1 basisch 7 + 3 neutral 7 + 5 neutral 8 - 6 neutral 6 + 7 neutral 11 - 8 neutral 9 - 9 alkal. 9 + 10 alkal. 8 + 13 basisch 6 + 15 basisch 3 - 16 basisch 4 + 2 neutral 8 - 4 alkal. 5 - 11 basisch 7 - 12 neutral 10 + 14 alkal. 7 - Vorhersage der häufigsten Klasse: 11/16 trocken +: Fehler 4/11 5/16 feucht -: Fehler 1/5 Fehler bei Information über Feuchte: 11/16 4/11 + 5/16 1/5 = 5/16
Bedingte Wahrscheinlichkeit • Wahrscheinlichkeit, dass ein Beispiel zu einer Klasse gehört, gegeben der MerkmalswertP(A|B) = P(A B) / P(B) • Annäherung der Wahrscheinlichkeit über die Häufigkeit • Gewichtung bezüglich der Oberklasse • Beispiel:P(+ |feucht) = 1/5 P(- |feucht) = 4/5 gewichtet mit 5/16P(+ |trocken) = 7/11 P(- | trocken) = 4/11 gewichtet mit 11/16 Wahl des Merkmals mit dem höchsten Wert (kleinsten Fehler)
Information eines Merkmals • Wir betrachten ein Merkmal als Information. • Wahrscheinlichkeit p+, dass das Beispiel der Klasse + entstammt. Entropie • Ein Merkmal mit k Werten teilt eine Menge von Beispielen E in k Untermengen auf. Für jede dieser Mengen berechnen wir die Entropie. Güte(Merkmal, E):=
Feuchte Güte des Attributs Feuchte mit den 2 Werten trocken und feucht: - ( 11/16 I(+,-) // trocken + 5/16 I(+,-)) = //feucht - ( 11/16 (-7/11 log 7/11 + -4/11 log 4/11) + 5/16 (-1/5 log 1/5 + -4/5 log 4/5)) = - 0,27 alle 16 Beispiele trocken feucht 11 Beispiele: 5 Beispiele: 7 davon + 1 davon + 4 davon - 4 davon -
Säure Güte des Attributs Säure mit den3 Werten basisch, neutral undalkalisch: - ( 5/16 I(+,-) basisch + 7/16 I(+,-) neutral + 4/16 I(+,-)) = alkalisch-0,3 basisch: - 3/5 log 3/5 + -2/5 log 2/5 neutral: -3/7 log 3/7 + -4/7 log 4/7 alkalisch: - 2/4 log 2/4 + -2/4 log 2/4 alle 16 Beispiele basisch neutral alkalisch 3 in + 3 in + 2 in + 2 in - 4 in - 2 in -
Temperatur • Numerische Merkmalswerte werden nach Schwellwerten eingeteilt. • 9 verschiedene Werte in der Beispielmenge, also 8 Möglichkeiten zu trennen. • Wert mit der kleinsten Fehlerrate bei Vorhersage der Mehrheitsklasse liegt zwischen 6 und 7. • 5 Beispiele mit Temp < 7, davon 3 in +,11 Beispiele Temp ≥ 7, davon 6 in -. • Die Güte der Temperatur als Merkmal ist - 0,29.
Merkmalsauswahl • Gewählt wird das Merkmal, dessen Werte am besten in (Unter-)mengen aufteilen, die geordnet sind. • Das Gütekriterium Information bestimmt die Ordnung der Mengen. • Im Beispiel hat Feuchte den höchsten Gütewert.
Algorithmus TDIDT (ID3) am Beispiel Feuchte trocken feucht 2 neutral 8 - 4 alkal. 5 - 11 basisch 7 - 12 neutral 10 + 14 alkal. 7 - 1 basisch 7 + 3 neutral 7 + 5 neutral 8 - 6 neutral 6 + 7 neutral 11 - 8 neutral 9 - 9 alkal. 9 + 10 alkal. 8 + 13 basisch 6 + 15 basisch 3 - 16 basisch 4 +
Algorithmus TDIDT am Beispiel Feuchte trocken feucht 2 neutral 8 - 4 alkal. 5 - 11 basisch 7 - 12 neutral 10 + 14 alkal. 7 - Säure alkalisch basisch neutral 1 basisch 7 + 13 basisch 6 + 15 basisch 3 - 16 basisch 4 + 3 neutral 7 + 5 neutral 8 - 6 neutral 6 + 7 neutral 11 - 8 neutral 9 - 9 alkal. 9 + 10 alkal. 8 +
Algorithmus TDIDT am Beispiel Feuchte trocken feucht 2 neutral 8 - 4 alkal. 5 - 11 basisch 7 - 12 neutral 10 + 14 alkal. 7 - Säure alkalisch basisch Temp. 1 basisch 7 + 13 basisch 6 + 15 basisch 3 - 16 basisch 4 + 7,5 >7,5 9 alkal. 9 + 10 alkal. 8 + 3 neutral 7 + 6 neutral 6 + 5 neutral 8 - 7 neutral 11 - 8 neutral 9 -
Algorithmus TIDT am Beispiel Feuchte trocken feucht 2 neutral 8 - 4 alkal. 5 - 11 basisch 7 - 12 neutral 10 + 14 alkal. 7 - Säure alkalisch basisch Temp. Temp. 7,5 >7,5 9 alkal. 9 + 10 alkal. 8 + 3,5 >3,5 3 neutral 7 + 6 neutral 6 + 5 neutral 8 - 7 neutral 11 - 8 neutral 9 - 1 basisch 7 + 13 basisch 6 + 16 basisch 4 + 15 basisch 3 -
Algorithmus ID3 (TDIDT) Rekursive Aufteilung der Beispielmenge nach Merkmalsauswahl: • TDIDT(E, Merkmale) • E enthält nur Beispiele einer Klasse --> fertig • E enthält Beispiele verschiedener Klassen: • Güte (Merkmale,E) • Wahl des besten Merkmals a mit k Werten • Aufteilung von E in E1, E2, ..., Ek • für i=1, ..., k: TDIDT(Ei, Merkmale \ a} • Resultat ist aktueller Knoten mit den Teilbäumen T1, ..., Tk
Komplexität TDIDT ohne Pruning • Bei m (nicht-numerischen) Merkmalen und n Beispielen ist die Komplexität O(mn log n) • Die Tiefe des Baums sei in O(log n). • O(n log n) alle Beispiele müssen “in die Tiefe verteilt” werden, also: O(n log n) für ein Merkmal. • m mal bei m Merkmalen!