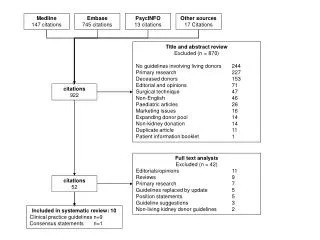
Download

1 / 20
210 likes | 697 Views
Sophia Soohoo CS 147 – Parallel Processing The use of 2 or more central processing units in a single computer system The CPUS share the other components of a computer Memory Disk System bus Multiprocessing Symmetric

E N D
Sophia Soohoo CS 147 – Parallel Processing
The use of 2 or more central processing units in a single computer system • The CPUS share the other components of a computer • Memory • Disk • System bus Multiprocessing
Symmetric • More than one computer processor will share memory capacity and data path protocol • Only one copy or the operating system will be used to initiate all the orders executed by the processors involved in the connection • Each CPU can act independently • All CPUs can be equal, or some processors can be reserved for particular uses • Drawback: bottleneck caused by bandwidth of the memory bus connecting the various processors, the memory, and the disk arrays Types of multiprocessing - Symmetric
Professor at Stanford University Received his PhD from Purdue University Worked for 10 years in computer organization and design. Proposed Flynn’s taxonomy in 1966 Multiprocessing classification – michael j. flynn
Flynn’s taxonomy – classification of computer architectures Flynn’s taxonomy distinguishes multi-processor computer architecture according to how they can be classified along the 2 independent dimensions of instruction and data. SISD – single instruction single data MISD – multiple instruction single data SIMD – single instruction multiple data MIMD – multiple instruction multiple data
SISD – Single instruction Single Data • A serial (non parallel) computer • Single instruction – only one instruction steam is being acted on by any CPU during any one clock cycle • Oldest classification • Modern day uses: • Older mainframes • Minicomputers • Workstations • PCs
A type of parallel computer • Single instruction – all CPUs execute the same instruction at any given clock cycle • Multiple data – each CPU can operate on a different data element • Synchronous (lockstep) • Since only one instruction is processed at a time, not necessary for each CPU to fetch and decode the instruction • Types: Processor arrays and vector pipelines • Uses: Computers with GPUs SIMD – Single instruction multiple data
Single data stream is fed into CPUs • Each CPU operates on the data independently through independent instruction streams • Advantage – redundancy/failsafe; multiple CPUs perform the same tasks on the same data, which reduces the chance of incorrect results if a single CPU fails • Disadvantage – expensive • Uses: array processors MISD – Multiple Instruction Single data
Most common type of parallel computing • Multiple instruction – every processor may be executing a different instruction stream • Multiple data – every CPU can work with a different data stream • Execution can be synchronous or asynchronous • Examples: super computers, multiprocessor SMP MIMD - Multiple instruction multiple data
Model is divided into 3 main types of memory architectures: • Shared Memory • Distributed Memory • Distributed Shared Memory Mapping Data and instruction set to memory
Ability for all processors to access all memory as global address space • Multiple CPUs can operate independently but share same memory resources • Changes in memory location affected by a CPU are visible to all other CPUs • Divided into 2 main classes: • UMA • NUMA Parallel Computer Memory Architecture – Shared memory
Uniform Memory Access • All CPUs share the physical memory uniformly • Access time is independent of which CPU makes the request or which memory chip contains the transferred data • Each CPU has a private cache • Identical processors • Cache coherent – if one processor updates a location in shared memory, all other process know about the update. Mimd Styles – uniform memory access (UMA)
Uniform Memory Access In the UMA memory architecture, all processors access shared memory through a bus (or another type of interconnect)
Used in multiprocessors • Provide separate memory for each CPU, avoiding performance hit when several CPUs attempt to address the same memory • Provides a performance benefit over single shared memory by a factor roughly the number of processors • Memory access time depends on the memory location relative to the processor • Processor can access its own local memory faster that non-local memory Mimd Styles – non-uniform memory access (nUMA)
Advantages • Global address space provides a user friendly programming to memory • Data sharing between tasks is fast and uniform due to proximity of memory to CPUs • Disadvantages • Lack of scalability between memory and CPUs. Adding more CPUs increases the traffic on shared memory CPU path • Programmer responsibility for synchronization constructs that insure “correct” access to global memory • Expensive to design and produce shared memory machines NUMA – Non-Uniform Memory Access
Memory access time varies with the location of the data to be accessed. If data resides in local memory, access is fast. If data resides in remote memory, access is slower. The advantage of the NUMA architecture as a hierarchical shared memory scheme is its potential to improve average case access time through the introduction of fast, local memory. NUMA - Non-Uniform Memory Access
Require a communication network to connect inter-processor memory • CPUs have their own distributed memory • Memory in one CPU does not map to another – each processor sees only its own memory • No concept of global address space • When processor needs to access data in another CPU, the programmer must define how and when data is communicated Distributed Memory
Shared memory component is usually cache coherent SMP machine • Combination of both shared and distributed memory • Distributed memory component is the networking of multiple SMPs • Required to move data from one SMP to another Hybrid distributed-shared Memory
http://www.networkworld.com/details/550.html?def • http://arith.stanford.edu/~flynn/ • http://en.wikipedia.org/wiki/Flynn%27s_taxonomy • https://computing.llnl.gov/tutorials/parallel_comp/#Whatis • http://it.toolbox.com/wiki/index.php/NUMA_Architecture • http://www.drdobbs.com/go-parallel/article/showArticle.jhtml?articleID=218401502 • http://www.ece.ucsb.edu/~parhami/text_par_proc.htm • http://www.ats.ucla.edu/rct/classes/introtoparallel_files/v3_document.htm References