Download

1 / 50
500 likes | 921 Views
Cache Designs and Tricks. Kyle Eli, Chun-Lung Lim . Why is cache important?. CPUs already perform computations on data faster than the data can be retrieved from main memory and… …microprocessor execution speeds are increasing faster than DRAM access times.

E N D
Cache Designs and Tricks Kyle Eli, Chun-Lung Lim
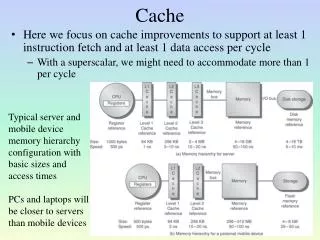
Why is cache important? • CPUs already perform computations on data faster than the data can be retrieved from main memory and… • …microprocessor execution speeds are increasing faster than DRAM access times. • Cache is typically much faster than main memory. • Multiple caches, each specialized to enhance a different aspect of program execution.
What is Cache ? • A cache is collection of data duplicating original values stored or computed earlier. • Implemented on- or off-chip in SRAM. • Faster to fetch or compute relative to original values. • Low latency • High bandwidth • Commonly organized into two or three levels.
Cache Associativity • Direct-Mapped Cache • Fully Associative Cache • Set Associative Cache
Direct-Mapped Cache • Slots are treated as a large array, with index chosen using the bits of the address. • Suffers from many collisions, causing the cache line to be repeatedly evicted even when there are many empty slots. • Very simple, only one slot to check.
Fully Associative Cache • Any slot can store the cache line. • Obtains data by comparing tag bits of the address to tag bits of every slot and making sure the valid bit is set. • Hardware is complex. • Normally used in translation lookaside buffers.
Set Associative Cache • Combination of fully-associative and direct-mapped schemes. • Cache slots are grouped into sets. • Finding a set is like direct-mapped scheme. • Finding slot within the set is like the fully-associative scheme. • Comparison hardware only needed for finding sets. • Fewer collisions because you have more slots to choose from, even when cache lines map to the same set.
Multi-level Cache • There are three levels of cache commonly being used: • One on-chip with the processor, referred to as the "Level-1" cache (L1) or primary cache. • Another is on-die cache is the "Level 2" cache (L2) or secondary cache. • L3 Cache, generally much larger and implemented on a separate chip.
Multi-level Caches new design decisions • Inclusive caches • Data in the L1 cache may also be in the L2 cache. • Example : Intel Pentium II, III, IV and most RISCs. • Exclusive caches • Data is guaranteed to be in at most of the L1 and L2 caches. • Example : AMD Athlon
Cache Issues • Latency: time for cache to respond to a request. • Smaller caches typically respond faster. • Bandwidth: number of bytes which can be read or written per second. • Cost: expensive to implement. • A large level 3 cache can generally cost in excess of $1000 to implement. • Benefits depends on the application’s access patterns.
Cache Issues (continued) • Memory requests are satisfied from • Cache • Cache Hit • Occurs when the processor requests an address stored in the cache. • Processor writes or reads directly to or from cache. • Main Memory • Cache Miss • Occurs when the processor requests an address that is not stored in the cache.
Caching Algorithm • Caching algorithms are used to optimize cache management. • Cache size is limited. • Algorithm used to decide which items to keep and which to discard to make room for new items. • Cache algorithms: • Least Recently Used (LRU) • Least Frequently Used • Belady’s Min
Least Recently Used • Discards the least recently used item first. • Must keep track of least-recently used item. • Using Pseudo-LRU, only one bit per cache item required to work.
Least Frequently Used • Counts how often an item is used. • Items used the least are discarded first.
Belady’s Min • “Optimal” algorithm, discard information that will not be needed for the longest time in the future. • Can not be implemented in hardware as it requires future knowledge. • Used in simulations to judge effectiveness of other algorithms.
Cache Optimization • Locality • Spatial Locality • Requested data is physically near previously used data. • Temporal Locality • Requested data was recently used, or frequently re-used.
Optimization for Spatial Locality • Spatial locality refers to accesses close to one another in position. • Spatial locality is important to the caching system because contiguous cache lines are loaded from memory when the first piece of that line is loaded. • Subsequent accesses within the same cache line are then practically free until the line is flushed from the cache. • Spatial locality is not only an issue in the cache, but also within most main memory systems.
Optimization for Spatial Locality • Prefetch data in other cache lines.
Optimization for Temporal Locality • Temporal locality refers to 2 accesses to a piece of memory within a small period of time. • The shorter the time between the first and last access to a memory location the less likely it will be loaded from main memory or slower caches multiple times.
Optimization for Temporal Locality • Re-use data which has been brought to cache as often as possible.
Optimization Techniques • Prefetching • Loop blocking • Loop fusion • Array padding • Array merging
Prefetching • Many architectures include a prefetch instruction that is a hint to the processor that a value will be needed from memory soon. • When the memory access pattern is well defined and the programmer knows many instructions ahead of time, prefetching will result in very fast access when the data is needed.
Prefetching (continued) • It does no good to prefetch variables that will only be written to. • The prefetch should be done as early as possible. Getting values from memory takes a LONG time. • Prefetching too early, however will mean that other accesses might flush the prefetched data from the cache. • Memory accesses may take 50 processor clock cycles or more.
Prefetching (continued) • The compiler may be inserting prefetch instructions. • May be slower than manual prefetch. • The CPU probably has a hardware prefetching feature. • Can be dynamically driven by run-time data. • Independent of manual prefetch.
Loop Blocking • Reorder loop iteration so as to operate on all the data in a cache line at once, so it needs only to be brought in from memory once. • For instance if an algorithm calls for iterating down the columns of an array in a row-major language, do multiple columns at a time. The number of columns should be chosen to equal a cache line.
Loop Fusion • Combine loops that access the same data. • Leads to a single load of each memory address.
Array Padding • Arrange accesses to avoid subsequent access to different data that may be cached in the same position.
Array Merging • Merge arrays so that data that needs to be accessed at once is stored together
Pitfalls and Gotchas • Basically, the pitfalls of memory access patterns are the inverse of the strategies for optimization. • There are also some gotchas that are unrelated to these techniques. • The associativity of the cache. • Shared memory. • Sometimes an algorithm is just not cache friendly.
Problems From Associativity • When this problem shows itself is highly dependent on the cache hardware being used. • It does not exist in fully associative caches. • The simplest case to explain is a direct-mapped cache. • If the stride between addresses is a multiple of the cache size, only one cache position will be used.
Shared Memory • It is obvious that shared memory with high contention cannot be effectively cached. • However it is not so obvious that unshared memory that is close to memory accessed by another processor is also problematic. • When laying out data, complete cache lines should be considered a single location and should not be shared.
Optimization Wrapup • Only try after the best algorithm has been selected. Cache optimizations will not result in an asymptotic speedup. • If the problem is too large to fit in memory or in memory local to a compute node, many of these techniques may be applied to speed up accesses to even more remote storage.
Recent Cache Architecture • AMD Athlon 64 X2 • 128kB 2-way set associative L1 (64kB data, 64kB instruction) per core • 1MB or 512kB full-speed 16-way set associative L2 cache per core • Intel Core (Yonah) • 64kB L1 (32kB data, 32kB instruction) per core • 2MB full-speed 8-way set associative L2 cache, shared • Designed for power-saving, cache can be flushed to memory and cache ways can be deactivated.
Recent Cache Architecture • SUN UltraSparc T1 • 24kB 4-way set associative L1 (8kB data, 16kB instruction) per core • 3072kB full-speed 12-way set associative L2 cache, shared • IBM Power5 • 96kB L1 (64kB 2-way set associative instruction, 32kB 4-way set associative data) • 1.92MB full-speed 10-way set associative L2 cache, shared • 36MB half-speed 12-way set associative L3 cache, shared (off-die)
Recent Cache Architecture • Sony/Toshiba/IBM Cell Broadband Engine • 9 cores • 1 POWER Processing Element (PPE) • 64kB L1(32kb 2-way set associative instruction, 32kb 4-way set associative data) • 512kB full-speed 8-way set associative L2 • 8 Synergistic Processing Elements (SPEs) • 256kB Local Storage per core • No direct access to memory • Can access any 128-bit word at L1 speed from local storage
Specialized Cache Designs • CAM-Tag Cache for Low-Power
Motivation • Cache uses 30-60% processor energy in embedded systems. • Example: 43% for StrongArm-1 • Many Industrial Low-Power Processors use CAM (content-addressable-memory) • ARM3 – 64-way set-associative – [Furber et. al. ’89] • StrongArm – 32-way set-associative – [Santhanam et. al. ’98] • Intel XScale – 32-way set-associative – ’01 • CAM: Fast and Energy-Efficient
Tag Status Data Tag Status Data =? =? Tag Index Offset Set-Associative RAM-tag Cache • Not energy-efficient • All ways are read out • Two-phase approach • More energy-efficient • 2X latency
Cache BUS 128 I/O 32 gwl BUS lwl lwl Tag SRAM Cells Data SRAM Cells Address Decoder Data SRAM Cells Offset Dec. Offset Dec. Tag Comp Sense Amps Sense Amps addr offset offset Set-Associative RAM-tag Sub-bank • Not energy-efficient • All ways are read out • Two-phase approach • More energy-efficient • 2X latency • Sub-banking • 1 sub-bank = 1 way • Low-swing Bitlines • Only for reads, writes performed full-swing • Wordline Gating
Tag Status Data HIT? HIT? CAM-tag Cache Tag Status Data • Only one sub-bank activated • Associativity within sub-bank • Easy to implement high associativity HIT? Word Tag Bank Offset
128 32 gwl lwl lwl I/O BUS SRAM Cells SRAM Cells CAM-tag Array Offset Dec. Offset Dec. Sense Amps Sense Amps tag offset offset CAM-tag Cache Sub-bank • Only one sub-bank activated • Associativity within sub-bank • Easy to implement high associativity
32x64 RAM Array 2x12x32 CAM Array CAM-tag Cache Sub-bank Layout 1-KB Cache Sub-bank implemented in 0.25 m CMOS technology 10% area overhead over RAM-tag cache
Global Wordline Decoding Local Wordline Decoding gwl lwl Decoded offset Tag Comp. Tag bits Tag readout Data out Data readout Tag bits Local Wordline Decoding Tag bits broadcasting gwl lwl Tag Comp. Decoded offset Data out Data readout Delay Comparison RAM tag Cache Critical Path: Index Bits CAM tag Cache Critical Path: Tag bits Within 3% of each other
Hit Energy Comparison Hit Energy per Access for 8KB Cache in pJ Associativity and Implementation
Total Access Energy (pegwit) Pegwit – High miss rate for high associativity Total Energy per Access for 8KB Cache in pJ Miss Energy Expressed in Multiples of 32-bit Read Access Energy
Total Access Energy (perl) Perl – Very low miss rate for high associativity Total Energy per Access for 8KB Cache in pJ Miss Energy Expressed in Multiples of 32-bit Read Access Energy
References • Wikipedia • http://en.wikipedia.org/wiki/Cache_algorithms • UMD • http://www.cs.umd.edu/class/spring2003/cmsc311/Notes/index.html • Michael Zhang and Krste Asanovic • Highly-Associative Caches for Low Power Processors, MIT Laboratory for Computer Science, December 2000 (from Kool Chips Workshop) • Cache Designs and Tricks • Kevin Leung, Josh Gilkerson, Albert Kalim, Shaz Husain
References Cont’d • Many academic studies on cache • [Albera, Bahar, ’98] – Power and performance trade-offs • [Amrutur, Horowitz, ‘98,’00] – Speed and power scaling • [Bellas, Hajj, Polychronopoulos, ’99] – Dynamic cache management • [Ghose, Kamble,’99] – Power reduction through sub-banking, etc. • [Inoue, Ishihara, Murakami,’99] – Way predicting set-associative cache • [Kin,Gupta, Mangione-Smith, ’97] – Filter cache • [Ko, Balsara, Nanda, ’98] – Multilevel caches for RISC and CISC • [Wilton, Jouppi, ’94] – CACTI cache model