Download

1 / 20
200 likes | 337 Views
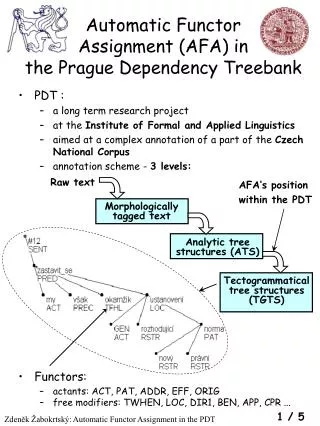
Chinese Semantic Dependency Relation System and Treebank Construction. Author(s): Yanqiu Shao ; Likun Qiu ; Chunxia Liang Product Type: Conference Publications This paper appears in: Web Intelligence and Intelligent Agent Technology (WI-IAT), 2011 IEEE/WIC/ACM International Conference on

E N D
Chinese Semantic Dependency Relation System and Treebank Construction Author(s): YanqiuShao; LikunQiu; Chunxia Liang Product Type: Conference Publications This paper appears in: Web Intelligence and Intelligent Agent Technology (WI-IAT), 2011 IEEE/WIC/ACM International Conference on Issue Date : 22-27 Aug. 2011 Speaker:Pei Mei Chen
目錄 • 摘要 • 序論 • SRL與SDP之比較 • 語料庫介紹 • 語意依存關係系統的建置 • 語意依存關係樹庫的建構 • 語料庫的建置過程 • 結論與未來工作
摘要 • 深層語意分析的關鍵點在於理解句子的意思。本篇論文結合了一些根據不同學者所給予的中文語意關係系統,並提出了更全面的語意依存分析系統。 • 新的語意關係系統包含了定義狀態(ex:動詞扮演修飾詞和動名詞扮演主要的名詞片語)。而且其中的中文語意依存關係樹庫是透過自動和手動的方法來建構的。 • 這種語意依存關係結構樹將成為研究深層語意分析的基礎。
序論 • 語言通常有三個重要的層次:聲音、形式和意義。在三個層次中,意義是最重要的一層。 • 根據透過多變的句法形式去做語意分析,以捕獲句子意義的性質。 • 例如:「我們打敗了敵人」和「敵人被我們所打敗」是不同的句法形式,但它們代表著相同的語意形式:打敗(我們、敵人)。 • 從此可以看出,語意關係與句法關係相比是來得更加穩定。語意關係的關鍵點在於要理解一個句子的含義。
序論 • 到目前為止,在研究句子的意思主要集中於語意角色標註(簡稱SRL,又稱淺層語意分析)上。但是SRL無法描述詳細的語意關係,不過透過語意依存分析(SDP)將可能有好的處理方法。 • SDP的理論基礎是依存語法理論。SDP整合依存結構與語意資訊,並清楚地、深入地描述句子的結構和語意關係。
SRL與SDP之比較 SRL-語意角色標註 • SRL只處理述語和相關參數之間的關係。 SDP-語意依存分析 • SDP是捕獲修飾詞和主詞之間的全部關係。 • SDP完全呈現整個句子的語意資訊。 • SDP涵蓋了許多語意關係(如:數量、屬性、次數等)遠遠超出周圍的主要述語的關係。 • 例如:在片語「兩本書」,其中「兩」和「書」之間含有數量的關係。而這種關係在SRL中是不被標記的。
SRL與SDP之比較 SDP不僅分析述語的語意角色,也會分析名詞片語的內部結構。例如,對於名詞片語「魯迅寫的《故鄉》,其有分析出「寫」和「故鄉」這二個字。但是在SRL中,扮演動詞角色的「是」,就不會被詳細的分析出來了。
語料庫介紹 • 語料庫:在語言學上意指大量的文本,通常經過整理,具有既定格式與標記。 • 語料庫其分為二種: • 語法依存語料庫 • 語意角色標註語料庫。 • 語料庫種類: • 英文 • 賓州樹庫-是比較流行的英語片語結構語法樹庫,其有高水準的一致性和準確的標籤,並已成為目前研究英文語法分析的公認練習和測試的語料集。 • PropBank(命題樹庫)-是一個以賓夕法尼亞大學所開發的賓州樹庫為基礎的語意角色標註語料庫。PropBank僅標記述語動詞(連接動詞除外),並只包括20個關係角色。其有6個核心的角色,並且不同的述語動詞在相同的核心角色時,可能也會有不同的含義。
語料庫介紹 • 語料庫種類: • 中文 • 由中研院所開發的中文句結構樹資料庫 • 從賓夕法尼亞大學所開發的賓州中文樹庫 • TCT(華漢語樹庫,根據核心節點轉移TCT至依存結構以繪製清單和依存關係的類型規則) • 由哈爾濱工業大學資訊檢索研究中心所建置的依存樹庫 • 中文的PropBank 中文句結構樹資料庫
語意依存關係系統的建置 語意依存關係系統的資訊來源有: • 知網(HowNet) • 知網裡的事件分類出83類的語意關係,而類別可劃分出主要的語意角色和輔助的語意角色。 • 雖然知網的語意角色是豐富且複雜的,但是其主要的語意角色全都以動詞為目標,並且在知網中沒有語法的關係。 • LuChuan和YuanYulin的語意關係系統
語意依存關係系統的建置 • 由於知網裡的關係是由擴展、結合,以及新的語意關係系統所建置的。所以本文新建了兩種語意關係,其主要的目的在於動詞扮演修飾詞和動名詞扮演主詞片語的情況。 • 例如:「去世的爺爺」和「被打傷的群眾」在這裡的「去世」和「打傷」是作為動詞,但是這兩句詞也是修飾詞。然而,如果只是修飾詞關係被標記為「修飾關係」,則真正的語意關係-「經歷」和「病人」這二句將被掩蓋。 • 當在片語中出現以動詞為主詞的語意關係時就表示為「r-」,即反向關係。因此,例子就可以標示為「r-經歷」和「r-病人」。
語意依存關係系統的建置 • 除了反向關係,還有另一種為間接關係增加到我們的語意系統中,像是動名詞為片語中的主詞。 • 例如:「企業管理」在這裡的「管理」是動名詞。當它被用作為動詞時,其也具有相同的角色。所以為了區別「動詞+名詞」的情況,而增加了一個「j-」的語意關係,以代表動名詞為主詞的情況。
語意依存關係系統的建置 • 因為一些知網的關係發生頻率低,所以將其修飾或加以合併。 • 例如:「伙伴」的關係合併為「代理」、「事件之前的期間」和「事件之後的期間」合併為「持續的時間」,並且新增一些標籤(如:原因)。
語意依存關係樹庫的建構 可用兩種方法來建構結構樹庫: • 改造現有的語法或語意關係標註語料庫 • 賓州中文樹庫(PCT) • 使用PCT的功能標籤。 • 賓州中文樹庫是一個片語結構語法樹庫。 • 頂部節點發現規則應用到將片語結構轉換成依存結構。 • 為了減少工作量,片語結構的功能標籤是用來做查詢。 • 透過編寫規則,某些部分的語意關係是自動標註的。
語意依存關係樹庫的建構 可用兩種方法來建構結構樹庫: • 改造現有的語法或語意關係標註語料庫 • 中文的PropBank(CPB) • 根據CPB來建立語意依存框架。 • CPB是根據增加語意角色資訊層到PCT的語法元件裡而建構成的。 • 這些標籤的真實含義是在框架工作檔案中給與的。 • 這些述語的語意依存框架可以根據在PropBank中的語意角色框架來建造。 • 在語意依存框架中的關係是統一且具體的。
語意依存關係樹庫的建構 可用兩種方法來建構結構樹庫: • 手動標註新的語料庫標籤 • 在手動標註的過程中,為了提高標註的效率,主動學習的方法將應用於幫助標籤語料庫之中。 • 透過使用標註工具來手動標註。其功能有:標註和校正依存弧形、依存關係、斷詞和部分詞類、尋找當前弧形相同或相似的弧形關係、顯示語意依存關係框架的動詞等。 • 標註弧形的關係在語料庫建置過程中的主要工作之一。最大熵模型是用來幫助自動標註該關係的。如:弧形的方向、子節點與父節點之間的距離、父節點左邊和右邊等。
語意依存關係樹庫的建構 可用兩種方法來建構結構樹庫: • 手動標註新的語料庫標籤 • 還需做一致性檢查。因為面對同一對詞,而不同的標註者可能會有不一樣的標註結果。其檢查內容包括: • 完全符合的檢查-如果二對詞有相同的字、相同的弧形,以及相同的弧線方向,那它們可能是相同的語意關係。反之則是錯誤的。 • 對每個語意關係進行檢查-將檢查所有具有相同語意關係的詞對。例如:對於「內容結果」的語意關係,收集所有父節點的詞對,因為每個動詞都有一個或數個語意框架,所以其就可以判斷在集合中的動詞框架是否屬於其的語意關係。 • 模式吻合的檢查-當它們扮演為一個修飾詞時,對於那些有相同模式(如:「穩定性」和「流動性」)應該有相同的關係。此種檢查可以發現一些同類的錯誤。
語料庫的建置過程 • 1000句先手動標記→根據這1000句來做最大熵模型→手動校正→不斷地增加訓練數據來進行改善的動作。 • [補充]因為該模型可以提供標註者一個初始的註釋,所以讓註釋的過程更簡化,也能讓標註的效率大大提高。
結論與未來工作 • 語意依存深層分析的關鍵在理解句子的意思。語意關係系統的定義和語意分析樹庫的建置都是以深層語意依存為基礎。本篇論文結合了一些根據不同學者所給予的中文語意關係系統,並形成了一個新的語意關係系統。而建立一個大規模的語意依存語料庫,其是以結合自動和手動標記的方法為基礎。例如:在樹庫的建置過程中,一些規則的形成是基於這些現有的資料和規則,然後其可以用於改造現有的資料至語意依存語料庫中。最大熵模型也有助於手動標記。同時,一致性檢查可以幫助確保標籤的一致性。 • 基於此語意依存語料庫,自動的SDP模型正在研究中,並且在未來將展示研究成果。並根據調查結果,如何進一步改進和完善的SDP系統是我們下一步的工作。